Meet DERA: An AI Framework For Enhancing Large Language Model Completions With Dialog-Enabled Resolving Agents
Deep learning “large language models” have been developed to forecast natural language content based on input. Beyond only language modelling challenges, the usage of these models has improved the performance of natural language. LLM-powered approaches have demonstrated benefits in medical tasks such as information extraction, question-answering, and summarization. Prompts are natural language instructions used by LLM-powered techniques. The task specification, the rules the predictions must abide by, and optionally some samples of the task input and output are all included in these instruction sets.
Generative language models’ capacity to produce results based on instructions given in natural language eliminates the requirement for task-specific training and enables non-experts to expand on this technology. Although many jobs may be expressed as a single cue, further research has shown that segmenting tasks into smaller ones might improve task performance, particularly in the healthcare sector. They support an alternative strategy that consists of two crucial components. It begins with an iterative process for enhancing the first product. As opposed to conditional chaining, this enables the generation to be refined holistically. Second, it has a guide who may direct by proposing regions to concentrate on throughout each repetition, making the procedure more comprehensible.
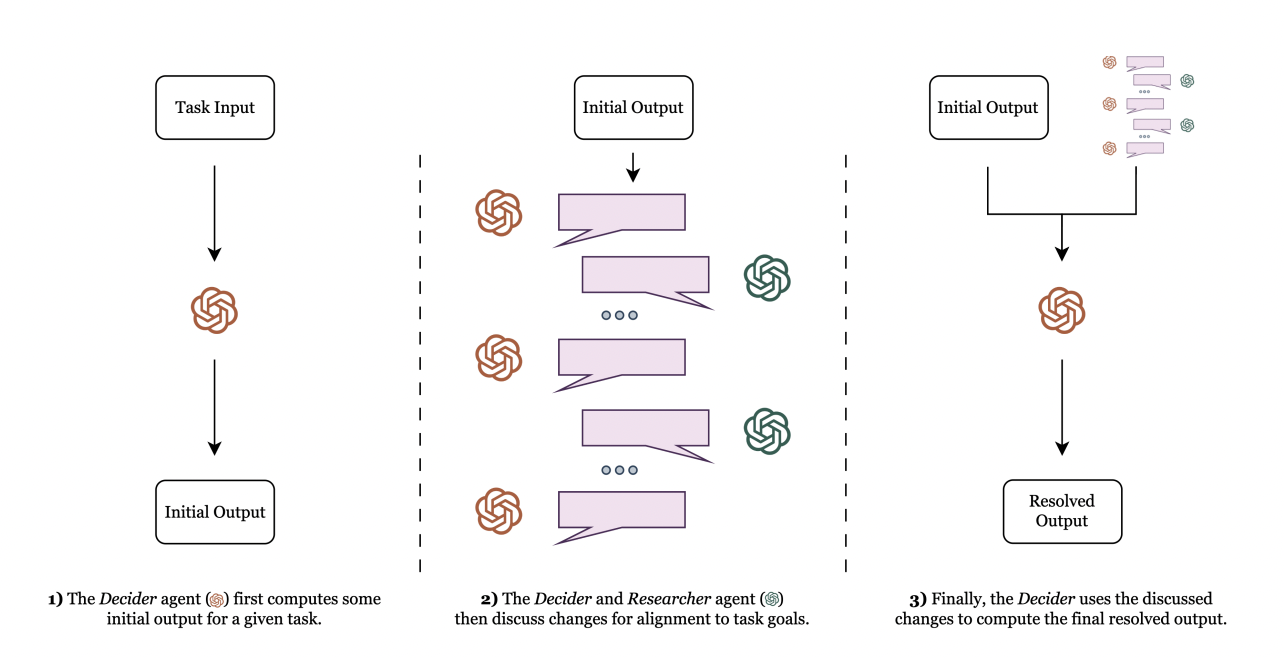
With the development of GPT-4, they now have a rich, lifelike conversational medium at their disposal. Researchers from Curai Health suggest Dialog-Enabled Resolving Agents or DERA. DERA is a framework to investigate how agents charged with dialogue resolution might enhance performance on natural language tasks. They contend that assigning each dialogue agent to a particular role will help them focus on certain aspects of the work and guarantee that their partner agent maintains alignment with the overall objective. The Researcher agent seeks pertinent data regarding the issue and suggests topics for the other agent to concentrate on.
To enhance performance on natural language tasks, they offer DERA, a framework for agent-agent interaction. They assess DERA based on three distinct categories of clinical tasks. To answer each of them, various textual inputs and levels of expertise are needed. The medical conversation summarising challenge aims to provide a summary of a doctor-patient dialogue that is factually correct and free of hallucinations or omissions. Creating a care plan requires a lot of information and has lengthy outputs that are helpful in clinical decision support. The Decider agent role is free to respond to this data and choose the ultimate course of action for the output.
The work has a variety of solutions, and the objective is to create as much factually correct and pertinent material as possible. Answering questions about medicine is an open-ended assignment that requires knowledge thinking and has just one possible solution. They use two question-answering datasets to research in this more challenging environment. In both human-annotated assessments, they discover that DERA performs better than base GPT-4 in the care plan creation and medical conversation summarising tasks on various measures. According to quantitative analyses, DERA successfully corrects medical conversation summaries that include a lot of inaccuracies.
On the other hand, they discover little to no improvement in GPT-4 and DERA performance in question-answering. According to their theories, this method works well for longer-form generation problems that involve a lot of fine-grained features. They will collaborate to publish a new open-ended medical question-answering job based on MedQA, which consists of practice questions for the US Medical Licensing Test. This makes it possible to do a new study on the modelling and assessing question-answering systems. Chains of reasoning and other task-specific methods are examples of chaining strategies.
Chain-of-thought techniques encourage the model to approach a problem as an expert might, which improves some tasks. All of these methods make an effort to force the appropriate generation out of the fundamental language model. The fact that these prompting systems are limited to a predetermined set of prompts made with specific purposes, like writing explanations or fixing output abnormalities, is a fundamental constraint of this method. They have taken a good step in this direction but applying them to real-world circumstances is still a huge challenge.
Check out the Paper and Github. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 17k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.