Meet SparseFormer: A Neural Architecture for Sparse Visual Recognition with Limited Tokens
Developing neural networks for visual recognition has long been a fascinating but difficult subject in computer vision. Newly suggested vision transformers replicate the human attention process by using attention operations on each patch or unit to interact dynamically with other units. Convolutional neural networks (CNNs) construct features by applying convolutional filters to each unit of pictures or feature maps. To conduct operations intensively, convolution-based and Transformer-based architectures must traverse every unit, such as a pixel or patch on the grid map. The sliding windows that give rise to this intensive per-unit traversal reflect the idea that foreground items may show up consistently about their spatial placements in a picture.
They don’t, however, have to look at every aspect of a situation to identify it since they are humans. Instead, they can quickly identify textures, edges, and high-level semantics inside these regions after broadly identifying discriminative areas of interest with numerous glances. Contrast this with current visual networks, where it is customary to explore each visual unit thoroughly. At higher input resolutions, the dense paradigm incurs exorbitant computing costs yet does not explicitly reveal what a vision model looks at in an image. In this study, the authors from Show Lab of NU Singapore, Tencent AI lab, and Nanjing University suggest a brand-new vision architecture called SparseFormer to investigate sparse visual recognition by precisely mimicking human vision.
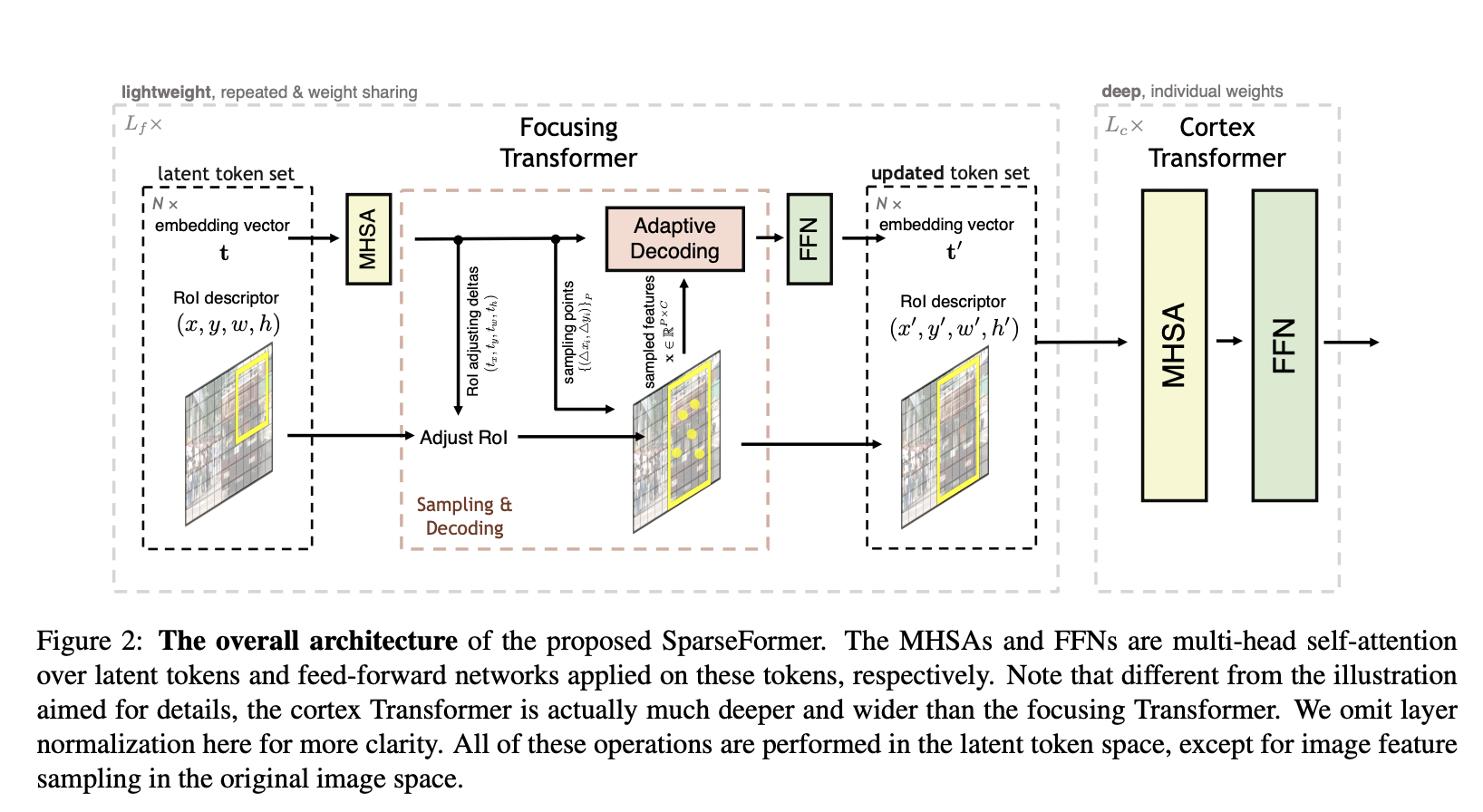
A lightweight early convolution module in the SparseFormer pulls image features from a given picture. In particular, from the very beginning, SparseFormer learns to represent a picture via latent transformers and a very small number of tokens (for example, down to 49) in the latent space. Each latent token has a region of interest (RoI) description that may be honed across several stages. To generate latent token embeddings iteratively, a latent focusing transformer modifies token RoIs to focus on foregrounds and sparsely recovers picture features according to these token RoIs. SparseFormer feeds tokens with these area properties into a bigger and deeper network or a typical transformer encoder in the latent space to achieve accurate recognition.
The restricted tokens in the latent space are the only ones to perform the transformer operations. It is appropriate to refer to their architecture as a sparse solution for visual identification, given that the number of latent tokens is extremely small and the feature sampling procedure is sparse (i.e., based on direct bilinear interpolation). Except for the early convolution component, which is light in design, the overall computing cost of the SparseFormer is almost unrelated to the input resolution. Moreover, SparseFormer may be fully trained on classification signals alone without any extra prior training on localizing signs.
SparseFormer aims to investigate an alternative paradigm for vision modeling as a first step towards sparse visual recognition rather than to provide cutting-edge outcomes with bells and whistles. On the difficult ImageNet classification benchmark, SparseFormer still achieves highly encouraging results comparable to dense equivalents but at a reduced computing cost. The memory footprints are smaller, and throughputs are higher than dense architectures because most SparseFormer operators operate on tokens in the latent space rather than the dense image space. After all, the number of tokens is constrained. This results in a better accuracy throughput trade-off, especially in the low-compute region.
Video categorization, which is more data-intensive and computationally expensive for dense vision models but appropriate for the SparseFormer architecture, may be added to the SparseFormer architecture thanks to its straightforward design. For instance, with ImageNet 1K training, Swin-T with 4.5G FLOPs achieves 81.3 at a higher throughput of 726 images/s. In contrast, the compact variation of SparseFormer with 2.0G FLOPs obtains 81.0 top-1 accuracy at a throughput of 1270 images/s. Visualizations of SparseFormer demonstrate its capability to distinguish between foregrounds and backgrounds using just classification signals from beginning to finish. They also look at various scaling-up SparseFormer techniques for better performance. Their expansion of SparseFormer in video classification produces promising performance with lower compute than dense architectures, according to experimental findings on the difficult video classification Kinetics-400 benchmark. This demonstrates how the suggested sparse vision architecture performs well when given denser input data.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 18k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.