Microsoft Research Propose LLMA: An LLM Accelerator To Losslessly Speed Up Large Language Model (LLM) Inference With References
High deployment costs are a growing worry as huge foundation models (e.g., GPT-3.5/GPT-4) (OpenAI, 2023) are deployed in many practical contexts. Although quantization, pruning, compression, and distillation are useful general methods for lowering LLMs’ serving costs, the inference efficiency bottleneck of transformer-based generative models (e.g., GPT) is primarily associated with autoregressive decoding. This is because, at test time, output tokens must be decoded (sequentially) one by one. This presents serious difficulties for deploying LLMs at scale.
According to studies, an LLM’s context is often the source of its output tokens in real-world applications. An LLM’s context typically consists of documents relevant to a query and retrieved from an external corpus as a reference. The LLM’s output typically consists of multiple text spans discovered in the reference.
In light of this realization, a group of Microsoft researchers suggests LLMA. This inference-with-reference decoding technique can speed up LLM inference by capitalizing on the overlap between an LLM’s output and a reference in many real-world settings. This work aimed at speeding up inference in LLM by enhancing the performance of autoregressive decoding.
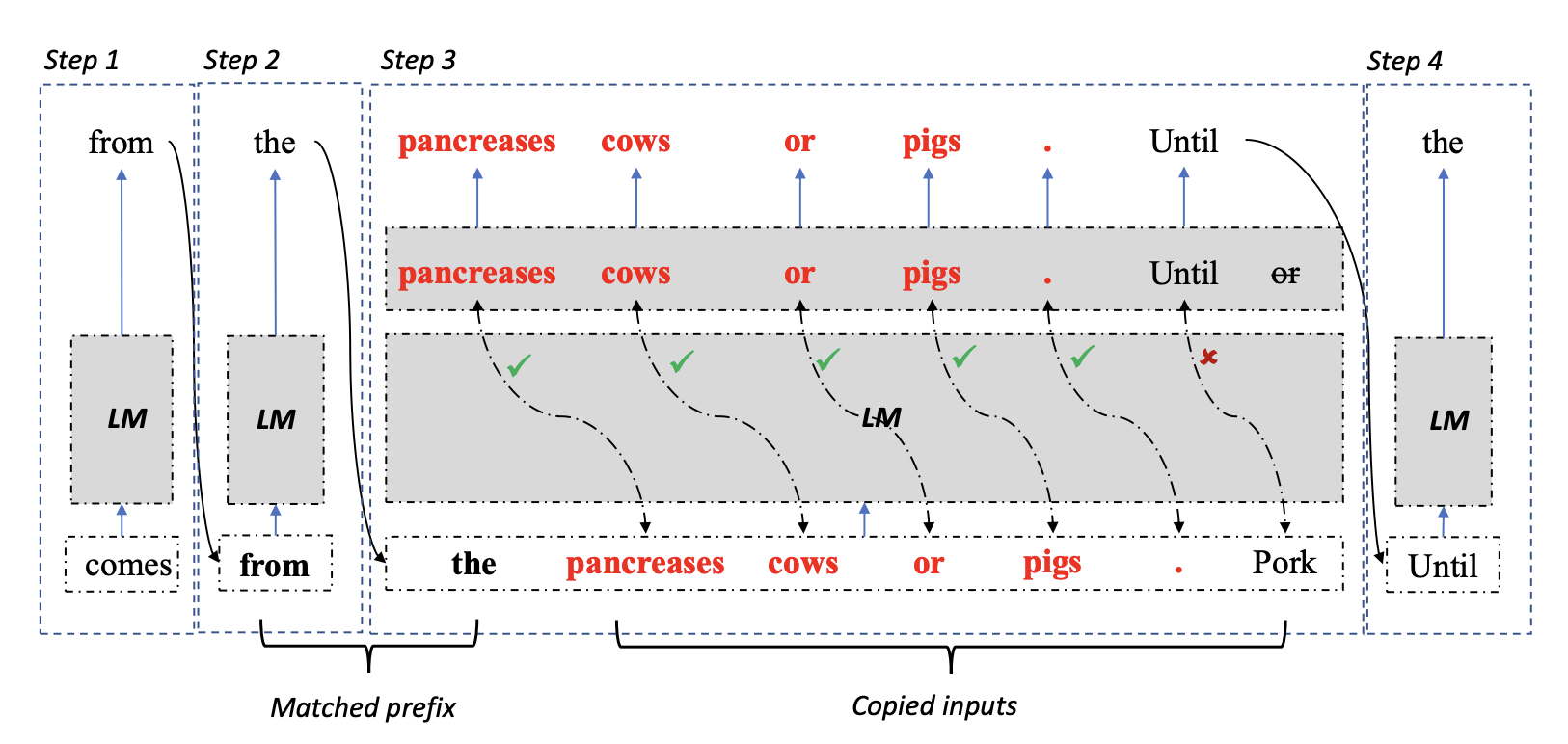
Selecting a text span from the reference, copying its tokens to the LLM decoder, and then performing an efficient parallel check based on the output token probabilities is how LLMA works. Doing so guarantees that the generation outcomes are indistinguishable from the vanilla greedy decoding method results while speeding up decoding by providing improved parallelism on vector accelerators like GPUs.
In contrast to previous efficient decoding algorithms like Speculative Decoding and Speculative Sampling, LLMA does not require an additional model to generate a draft for checking.
Experiments on various model sizes and practical application scenarios, including retrieval augmentation and cache-assisted creation, reveal that the proposed LLMA approach achieves over a two-factor speedup compared to greedy decoding.
Check out the Paper and Github. Don’t forget to join our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.