Google AI Releases A New Differentially Private Clustering Algorithm

Almost all industries maintain user databases that include a variety of user attributes to develop relevant user groups and comprehend their characteristics for various purposes. Sometimes, these include sensitive user attributes. In recent years, many studies have made progress in establishing confidentiality methods for processing sensitive data to reveal these group features without compromising individual users’ privacy.
Clustering, a fundamental building block in unsupervised machine learning, can be used to accomplish this task. A clustering algorithm divides data points into groups and allows any new data point to be assigned to the group with which it shares the most similarities. When working with sensitive datasets, however, it has the potential to leak extensive information about individual data points, putting the user’s privacy in danger.
To address this problem, Google AI researchers designed a novel differentially private clustering technique based on creating new representative data points confidentially.
Differentially Private Algorithm
In their previous work, the researchers have proposed a differentially private algorithm for clustering data points. In the local model, where the user’s privacy is protected even from the central server performing the clustering, the algorithm had the advantage of being private. However, any such approach inevitably incurs a significantly larger loss than approaches based on privacy models that require trusting a central server.
The new method uses a clustering algorithm inspired by the central model of differential privacy, in which the central server is trusted to have complete access to the raw data. This method aims to compute differentially private cluster centers that do not leak information about individual data points. The central model is the standard paradigm for differential privacy. Furthermore, central model algorithms can be simply swapped with non-private counterparts because they do not need changes to the data collecting process. After this, any (non-private) clustering method (e.g., k-means++) is executed on this privately produced core-set.
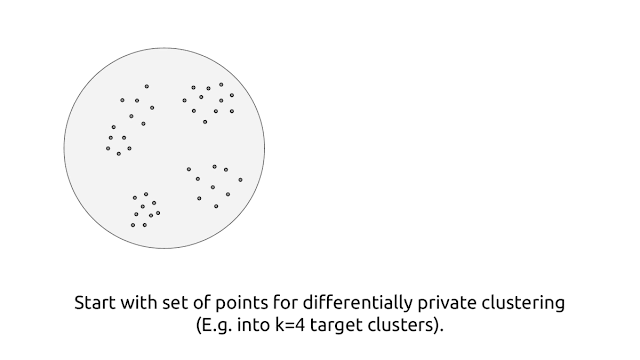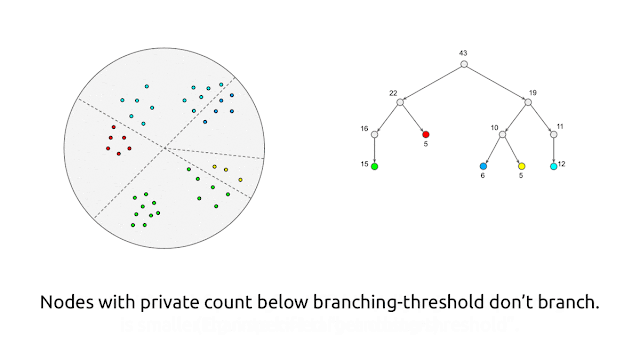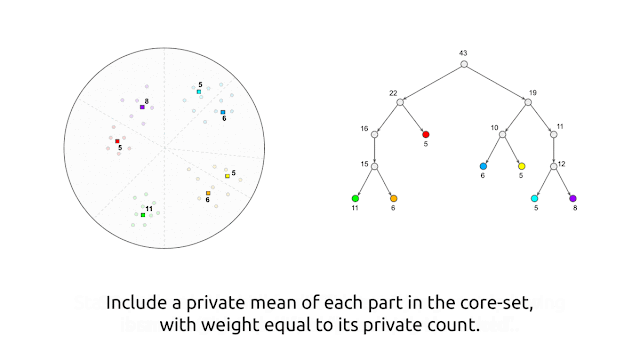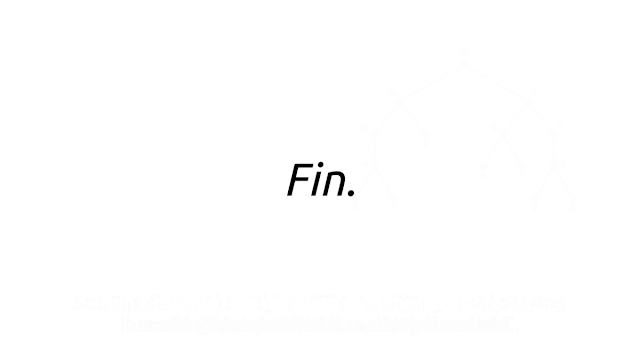
The algorithm produces the private core-set at a high level by recursively partitioning the points into “buckets” of similar points using random–projection-based locality-sensitive hashing (LSH). Then it replaces each bucket with a single weighted point that is the average of the points in the bucket. Here weight is equal to the number of points in the same bucket. However, as previously stated, this algorithm is not private yet. The algorithm is made private by introducing noise to both the counts and averages of points within a bucket and privately performing each action.
Because the added noise disguises each point’s contributions to the bucket counts and bucket averages, the algorithm’s behavior does not reveal information about any individual point and meets differential privacy. Individual points will not be well-represented by points in the core set if the number of points in the buckets is too large. In contrast, if the number of points in a bucket is too small, the added noise will become significant compared to the actual values, resulting in poor core-set quality. The algorithm achieves this trade-off using user-supplied parameters.
Source: https://ai.googleblog.com/2021/10/practical-differentially-private.html
The researchers compared the performance of the proposed technique with (non-private) k-means++ algorithm and a few other algorithms with implementations available, such as diffprivlib and dp-clustering-icml17. For this, they used the following benchmark datasets:
- A synthetic dataset with 100,000 data points in 100 dimensions sampled from a mixture of 64 Gaussians
- Neural representations for the MNIST dataset on handwritten digits obtained by training a LeNet model
- The UC Irvine dataset on Letter Recognition
- The UC Irvine dataset on Gas Turbine CO and NOx Emissions
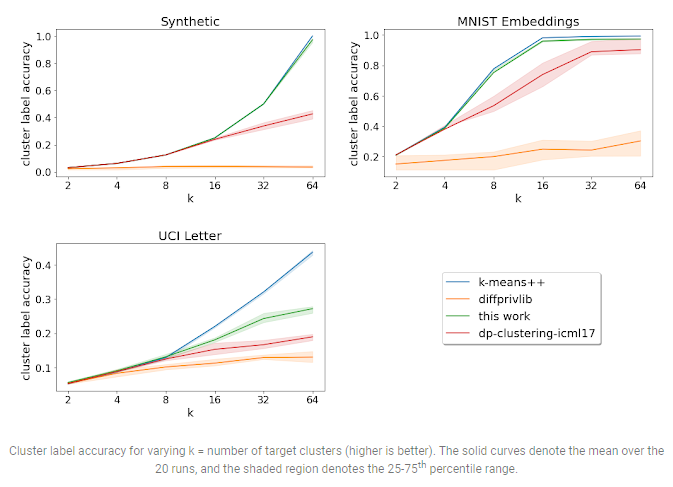
For these benchmark datasets, they evaluate the normalized k-means loss while altering the number of target centers (k). The proposed method achieves a smaller loss in three of the four datasets analyzed than the other private algorithms.

Furthermore, they examine the cluster label accuracy for datasets with specified ground-truth labels, which is the labeling accuracy obtained by assigning the most frequent ground-truth label in each cluster discovered by the clustering algorithm to all points in that cluster. The results show that the method outperforms existing private algorithms for all datasets with pre-specified ground-truth labels considered.
The researchers point out that any preprocessing done before employing the private clustering technique should account for the privacy loss individually. They intend to make adjustments to the algorithm to perform better with data that hasn’t been preprocessed.
In addition, the proposed algorithm requires a user-supplied radius, with all data points falling within that radius’s sphere. This is used to calculate how much noise should be added to the bucket averages. They estimated the relevant boundaries for each dataset non-privately for this experimental evaluation. However, these bounds should be computed privately or provided without knowing the dataset when executing the algorithms in reality.
GitHub: https://github.com/google/differential-privacy/tree/main/learning/clustering
Source: https://ai.googleblog.com/2021/10/practical-differentially-private.html
Suggested
Credit: Source link
Comments are closed.