Meet Make-it-3D: An Artificial Intelligence (AI) Framework For High-Fidelity 3D Object Generation From A Single Image
Imagination is a powerful mechanism of humanity. When presented with a single image, humans have the remarkable ability to imagine how the depicted object would appear from a different perspective. While this operation seems simple for our brains, it is rather challenging for computer vision and deep learning models. Indeed, generating 3D objects from a single image is a complex task due to the limited information available from a single viewpoint.
Various approaches have been proposed with this intent, including 3D photo effects and single-view 3D reconstruction with neural rendering. However, these methods have limitations in reconstructing fine geometry and rendering large views. Other techniques involve projecting the input image into the latent space of pre-trained 3D-aware generative networks. Still, these networks are often limited to specific object classes and unable to handle general 3D objects. Furthermore, building a diverse dataset for estimating novel views or a powerful 3D foundation model for general objects is currently an insurmountable challenge.
Images are widely available, while 3D models remain scarce. Recent advances in diffusion models, such as Midjourney or Stable Diffusion, have enabled remarkable progress in 2D image synthesis. Intriguingly, well-trained image diffusion models can generate images from different viewpoints, suggesting that they have already assimilated 3D knowledge.
Building on this observation, the paper presented in this article explores the possibility of leveraging this implicit 3D knowledge in a 2D diffusion model to reconstruct 3D objects. For this purpose, a two-stage approach, termed Make-It-3D, has been proposed for generating high-quality 3D content from a single image by utilizing a diffusion prior.
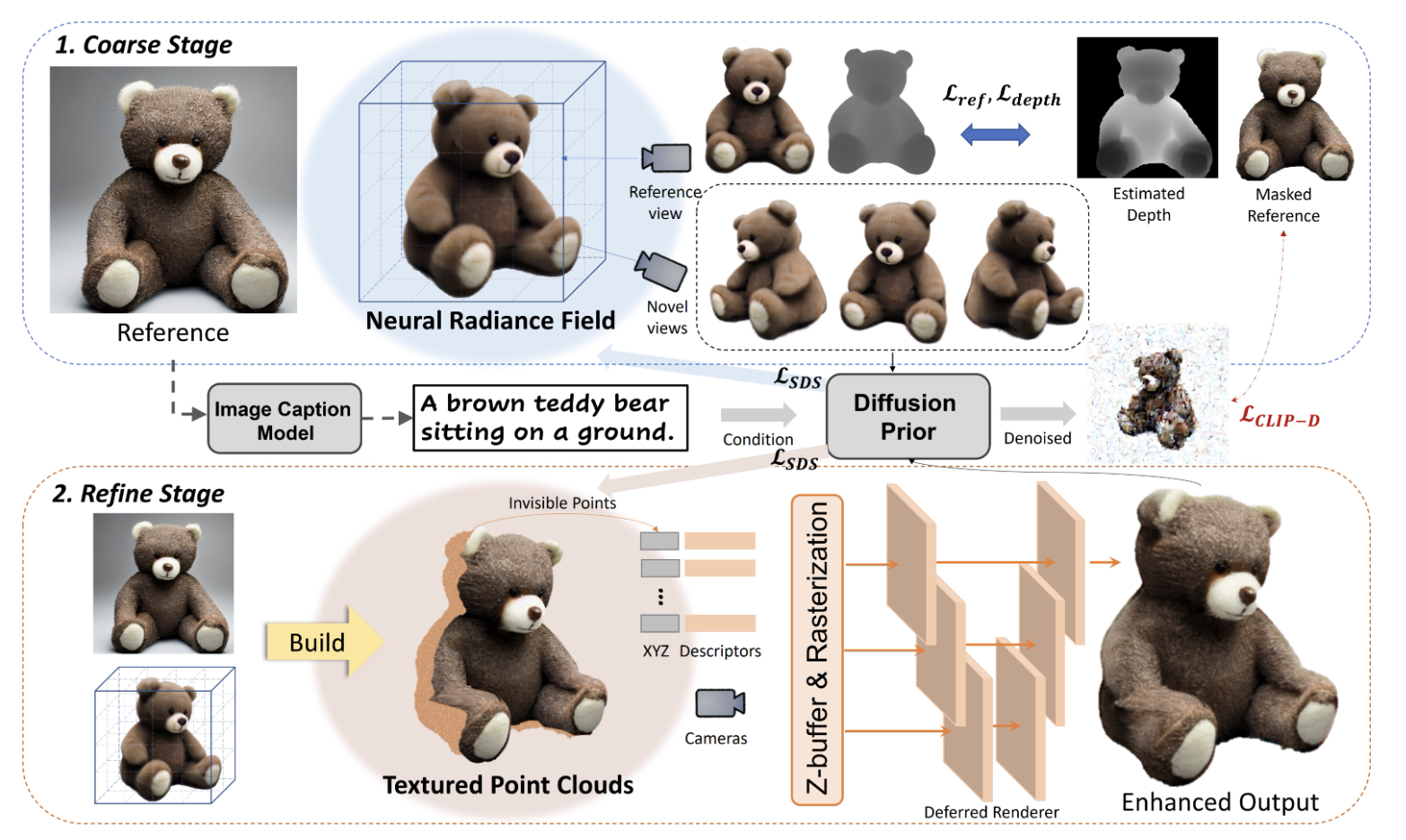
The architecture overview is presented below.

During the first stage, the diffusion prior helps improve the neural radiance field (NeRF) by utilizing score distillation sampling (SDS). In addition, reference-view supervision is used as a constraint for optimization. Unlike previous text-to-3D approaches that focus on textual descriptions, Make-it-3D prioritizes the fidelity of the 3D model to the reference image since the goal is image-based 3D creation. However, while the 3D models generated with SDS align well with textual descriptions, they often do not align faithfully with reference images, which do not capture all object details. To overcome this issue, the model is asked to maximize the similarity between the reference and the new view rendering denoised by a diffusion model. As images inherently contain more geometry-related information than textual descriptions, the depth of the reference image can be given as an additional geometry prior to alleviate the ambiguity of NeRF optimization regarding shape.
The initial 3D model generation process stage produces a rough model with reasonable geometry. Still, its appearance often lacks the quality of the reference image, with oversmooth textures and saturated colors. As a result, it is necessary to further improve the model’s realism by reducing the disparity between the rough model and the reference image. As texture is more important than geometry for high-quality rendering, the second stage focuses on texture enhancement while keeping the geometry from the first stage. A final refinement involves utilizing ground-truth textures for regions visible in the reference image obtained from mapping NeRF model and textures to point clouds and voxels.
The results of this approach are compared with other state-of-the-art techniques. Some samples taken from the mentioned work are depicted below.

This was the summary of Make-it-3D, an AI framework for high-fidelity 3D object generation from a single image.
If you are interested or want to learn more about this work, you can find a link to the paper and the project page.
Check out the Paper, Github, and Project. Don’t forget to join our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.