Could It Be the Patches? This AI Approach Analyzes the Key Contributor to the Success of Vision Transformers
Convolutional neural networks (CNNs) have been the backbone of systems for computer vision tasks. They have been the go-to architecture for all types of problems, from object detection to image super-resolution. In fact, the famous leaps (e.g., AlexNet) in the deep learning domain have been made possible thanks to convolutional neural networks.
However, things changed when a new architecture based on Transformer models, called the Vision Transformer (ViT), showed promising results and outperformed classical convolutional architectures, especially for large data sets. Since then, the field has been looking to enable ViT-based solutions for problems that have been tackled with CNNs for years.
The ViT uses self-attention layers to process images, but the computational cost of these layers would scale quadratically with the number of pixels per image if applied naively at the per-pixel level. Therefore, the ViT first splits the image into multiple patches, linearly embeds them, and then applies the transformer directly to this collection of patches.
Following the success of the original ViT, many works have modified the ViT architecture to improve its performance. Replacing self-attention with novel operations, making other small changes, etc. Though, despite all these changes, almost all ViT architectures follow a common and simple template. They maintain equal size and resolution throughout the network and exhibit isotropic behavior, achieved by implementing spatial and channel mixing in alternating steps. Additionally, all networks employ patch embeddings which allow for downsampling at the start of the network and facilitate the straightforward and uniform mixing design.
This patch-based approach is the common design choice for all ViT architectures, which simplifies the overall design process. So, there comes the question. Is the success of vision transformers mainly due to the patch-based representation? Or is it due to the use of advanced and expressive techniques like self-attention and MLPs? What is the main factor that contributes to the superior performance of vision transformers?
There is one way to find out, and it is named ConvMixer.

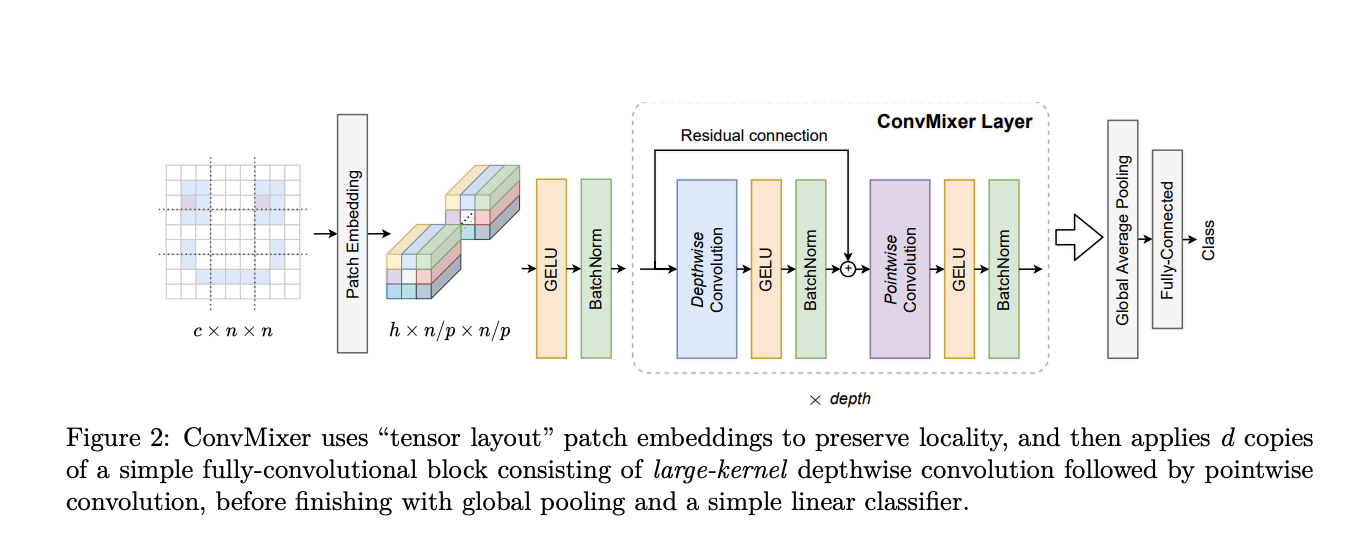
ConvMixer is a convolutional architecture developed to analyze the performance of ViTs. It is really similar to the ViT in many ways: it works directly on image patches, maintains a consistent resolution throughout the network, and separates the channel-wise mixing from the spatial mixing of information in different parts of the image.
However, the key difference is that the ConvMixer achieves these operations using standard convolutional layers, as opposed to the self-attention mechanisms used in the Vision Transformer and MLP-Mixer models. In the end, the resulting model is cheaper in terms of computing power because depthwise and pointwise convolution operations are cheaper than self-attention and MLP layers.
Despite its extreme simplicity, ConvMixer outperforms both “standard” computer vision models, such as ResNets of similar parameter counts and some corresponding ViT and MLP-Mixer variants. This suggests that the patch-based isotropic mixing architecture is a powerful primitive that works well with almost any choice of well-behaved mixing operations.
ConvMixer is an extremely simple class of models that independently mix the spatial and channel locations of patch embeddings using only standard convolutions. It can provide a substantial performance boost can be achieved by using large kernel sizes inspired by the large receptive fields of ViTs and MLP-Mixers. Finally, ConvMixer can serve as a baseline for future patch-based architectures with novel operations
Check out the Paper. Don’t forget to join our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.