This AI Paper Presents the Application of a Recurrent Memory to Extend the Model’s Context Length to an Unprecedented Two Million Tokens
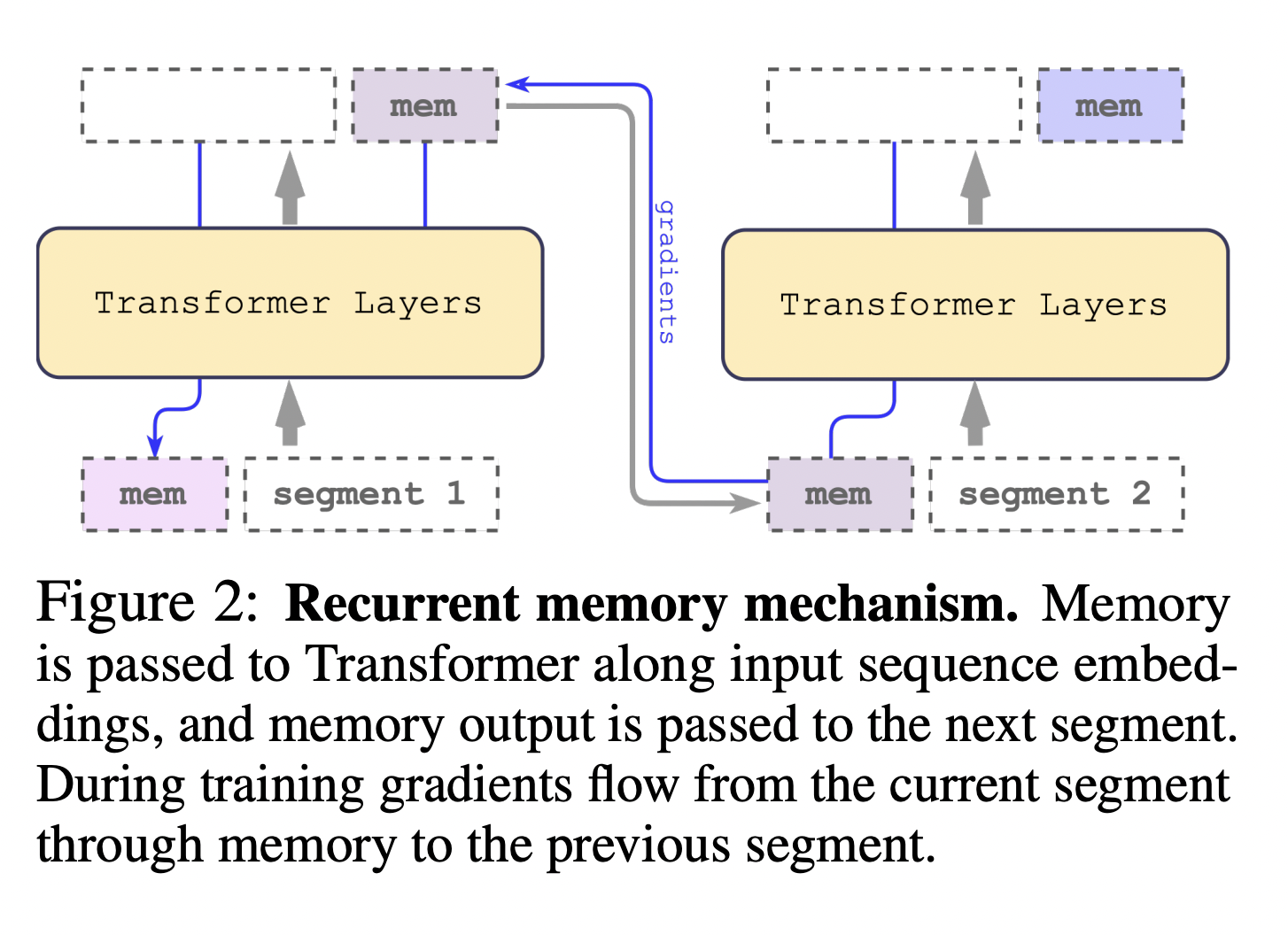
The Transformer concept has been widely embraced and applied in several fields of study and business. The model’s most significant flaw is the quadratic complexity of the attention operation, which makes big models harder to apply to lengthier inputs. This study demonstrates how a single Nvidia GTX 1080Ti GPU may process sequences longer than 1 million tokens utilizing a straightforward token-based memory scheme paired with pretrained transformer models like BERT.
The first step in enabling Recurrent memory (RMT) to generalize to problems with unknown features, such as language modeling, is the study of synthetic tasks. Since this design gained popularity, a great deal of study has been done on the issue of lengthy inputs in Transformers. This study shows that significant amounts of memory are only sometimes necessary when using Transformers to analyze long texts. A recurrent strategy and memory may transform quadratic complexity into linear complexity. Additionally, models trained on sufficiently big inputs may generalize to readers with longer orders of magnitude. They plan to modify the recurrent memory technique in further work to increase the effective context size of the most often used Transformers.

Researchers from DeepPavlov, Artificial Intelligence Research Institute, and London Institute for Mathematical Sciences make the following contributions
1. To improve the existing system, token-based memory storage and segment-level recurrence with recurrent memory (RMT) are added to BERT.
2. They show that the memory-augmented BERT can be taught to handle jobs on sequences up to seven times longer than its 512-token intended input length.
3. They found that the trained RMT may extrapolate to tasks of various durations, including those requiring linear scaling of calculations and surpassing 1 million tokens, effectively.
4. Using attention pattern analysis, they discovered the memory processes RMT uses to handle extraordinarily lengthy sequences successfully.
The use of a recurrent memory in BERT, one of the most successful Transformer-based models in natural language processing, is presented by the authors as a conclusion. They have effectively extended the model’s effective context length to an unprecedented two million tokens while retaining good memory retrieval accuracy using the Recurrent Memory Transformer architecture. Their approach permits information flow across segments of the input sequence by using recurrence and enables the storing and processing of local and global information. Their tests show the efficacy of their method, which has great potential to improve the handling of long-term dependencies in tasks involving natural language creation and comprehension, as well as to enable large-scale context processing for memory-intensive applications.
Check out the Paper. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.