Meet ImageReward: A Revolutionary Text-to-Image Model Bridging the Gap between AI Generative Capabilities and Human Values
In machine learning, generative models that can produce images based on text inputs have made significant progress in recent years, with various approaches showing promising results. While these models have attracted considerable attention and potential applications, aligning them with human preferences remains a primary challenge due to differences between pre-training and user-prompt distributions, resulting in known issues with the generated images.
Several challenges arise when generating images from text prompts. These include difficulties with accurately aligning text and images, accurately depicting the human body, adhering to human aesthetic preferences, and avoiding potential toxicity and biases in the generated content. Addressing these challenges requires more than just improving model architecture and pre-training data. One approach explored in natural language processing is reinforcement learning from human feedback, where a reward model is created through expert-annotated comparisons to guide the model toward human preferences and values. However, this annotation process can take time and effort.
To deal with those challenges, a research team from China has presented a novel solution to generating images from text prompts. They introduce ImageReward, the first general-purpose text-to-image human preference reward model, trained on 137k pairs of expert comparisons based on real-world user prompts and model outputs.
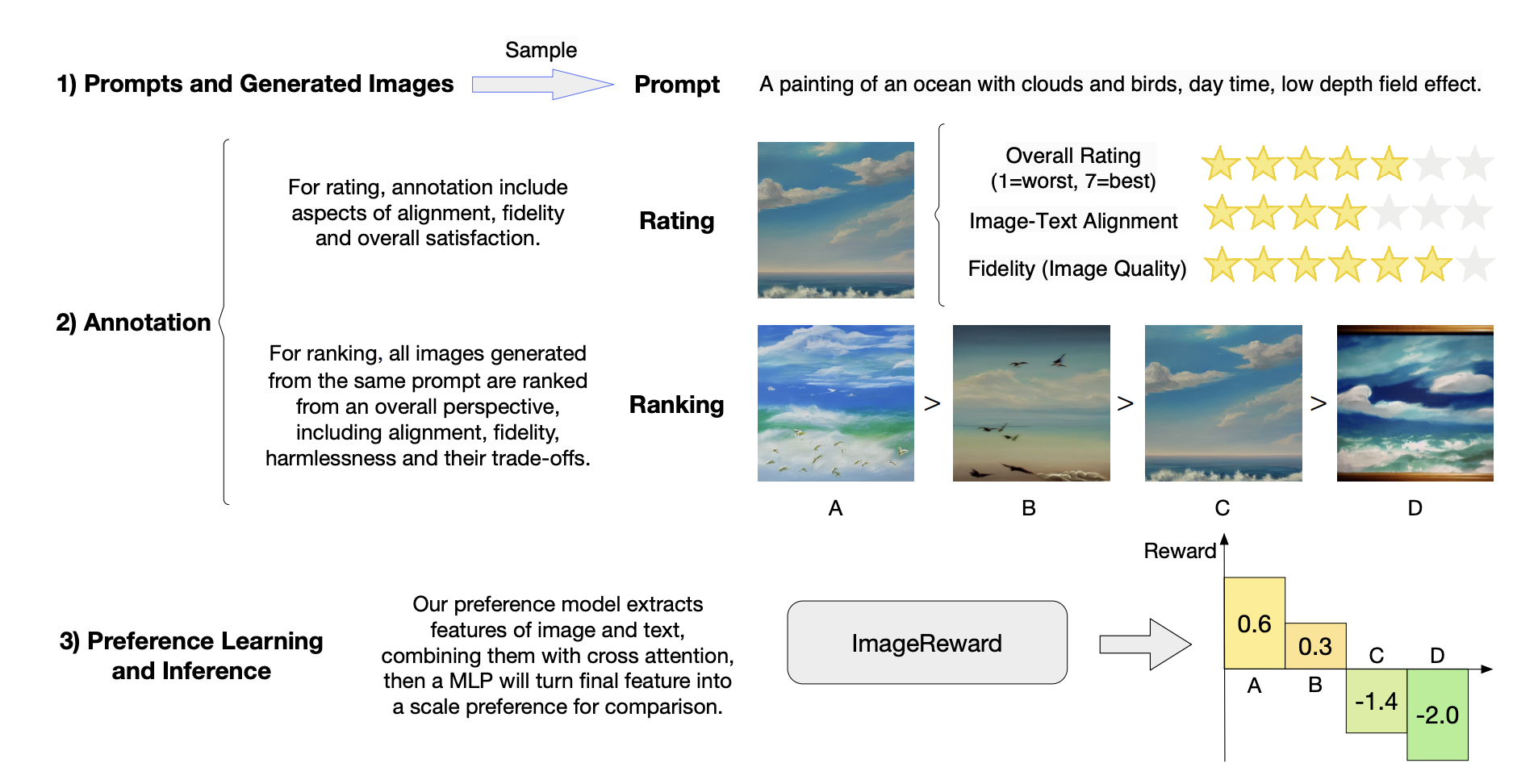
To construct ImageReward, the authors used a graph-based algorithm to select various prompts and provided annotators with a system consisting of prompt annotation, text-image rating, and image ranking. They also recruited annotators with at least college-level education to ensure a consensus in the ratings and rankings of generated images. The authors analyzed the performance of a text-to-image model on different types of prompts. They collected a dataset of 8,878 useful prompts and scored the generated images based on three dimensions. They also identified common problems in generated images and found that body problems and repeated generation were the most severe. They studied the influence of “function” words in prompts on the model’s performance and found that proper function phrases improve text-image alignment.
The experimental step involved training ImageReward, a preference model for generated images, using annotations to model human preferences. BLIP was used as the backbone, and some transformer layers were frozen to prevent overfitting. Optimal hyperparameters were determined through a grid search using a validation set. The loss function was formulated based on the ranked images for each prompt, and the goal was to automatically select images that humans prefer.
In the experiment step, the model is trained on a dataset of over 136,000 pairs of image comparisons and is compared with other models using preference accuracy, recall, and filter scores. ImageReward outperforms other models, with a preference accuracy of 65.14%. The paper also includes an agreement analysis between annotators, researchers, annotator ensemble, and models. The model is shown to perform better than other models in terms of image fidelity, which is more complex than aesthetics, and it maximizes the difference between superior and inferior images. In addition, an ablation study was conducted to analyze the impact of removing specific components or features from the proposed ImageReward model. The main result of the ablation study is that removing any of the three branches, including the transformer backbone, the image encoder, and the text encoder, would lead to a significant drop in the preference accuracy of the model. In particular, removing the transformer backbone would cause the most significant performance drop, indicating the critical role of the transformer in the model.
In this article, we presented a new investigation made by a Chinese team that introduced ImageReward. This general-purpose text-to-image human preference reward model addresses issues in generative models by aligning with human values. They created a pipeline for annotation and a dataset of 137k comparisons and 8,878 prompts. Experiments showed ImageReward outperformed existing methods and could be an ideal evaluation metric. The team analyzed human assessments and planned to refine the annotation process, extend the model to cover more categories and explore reinforcement learning to push text-to-image synthesis boundaries.
Check out the Paper and Github. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Mahmoud is a PhD researcher in machine learning. He also holds a
bachelor’s degree in physical science and a master’s degree in
telecommunications and networking systems. His current areas of
research concern computer vision, stock market prediction and deep
learning. He produced several scientific articles about person re-
identification and the study of the robustness and stability of deep
networks.
Credit: Source link
Comments are closed.