Check out this Comprehensive and Practical Guide for Practitioners Working with Large Language Models
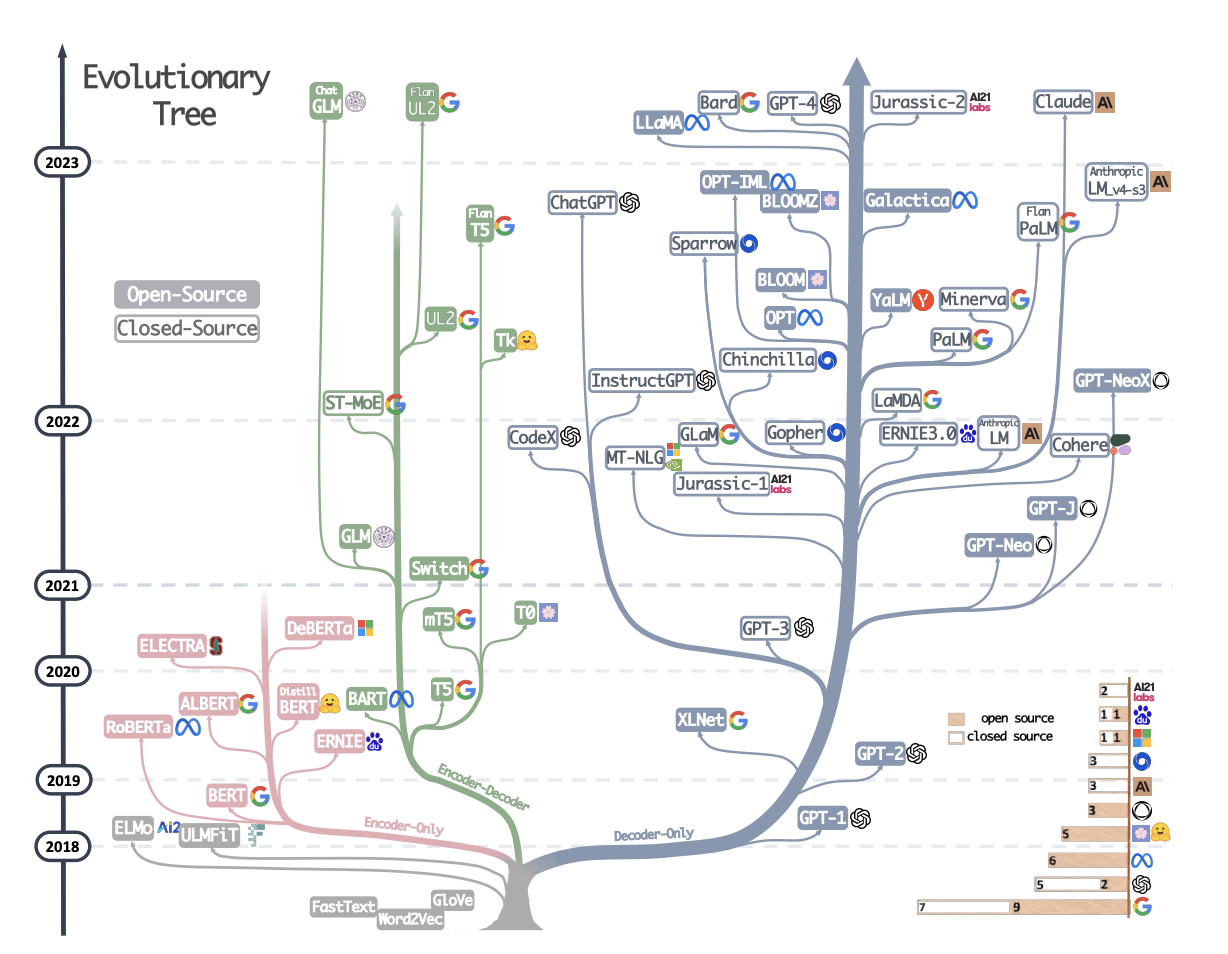
Large Language Models (LLMs) have paved their way into domains ranging from Natural Language Processing (NLP) to Natural Language Understanding (NLU) and even Natural Language Generation (NLG). LLMs like ChatGPT are exponentially gaining popularity, with more than a million users since its release. With a massive number of capabilities and applications, every day, a new research paper or an improved or upgraded model is being released.
In a recent research paper, authors have discussed Large Language Models (LLMs) and a practical guide for practitioners and end-users who work with LLMs in their downstream natural NLP tasks. It has covered everything, including LLM usages, such as models, data, and downstream tasks. The main motive is to understand the working and usage of LLMs and have a practical understanding of the applications, limitations, and types of tasks in order to use them efficiently and effectively. The paper includes a guide on how and when to use the best suitable LLM.
The team has discussed the three main types of data that are important for LLMs: pre-training data, training/tuning data, and test data. The importance of high-quality data for training and testing LLMs and the impact of data biases on LLMs have also been mentioned. The paper has provided insights into best practices for working with LLMs from a data perspective.
The authors have focused mainly on the applicability of LLMs for various NLP tasks, including knowledge-intensive tasks, traditional natural language understanding (NLU) tasks, and generation tasks. The authors provide detailed examples to highlight both the successful use cases and the limitations of LLMs in practice. They also discuss the emergent abilities of LLMs, such as their ability to perform tasks beyond their original training data and the challenges associated with deploying LLMs in real-world scenarios.
The main contribution has been summarized as follows –
- Natural Language Understanding – LLMs have exceptional generalization ability, allowing them to perform well on out-of-distribution data or with very few training examples
- Natural Language Generation – LLMs have the capability to generate coherent, contextually relevant, and high-quality text.
- Knowledge-Intensive tasks – LLMs have stored extensive knowledge that can be utilized for tasks requiring domain-specific expertise or general world knowledge.
- Reasoning Ability – The authors have emphasized the importance of understanding and harnessing the reasoning capabilities of LLMs in order to fully realize their potential in applications such as decision support systems and problem-solving.
Overall, the paper is a great guide to knowing about the practical applications of LLMs and their unique potential. It is important to know about the limitations and use cases of an LLM before starting to use it, so this research paper is definitely a great addition to the domain of LLMs.
Check out the Paper and GitHub link. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.