This AI paper shows an avenue for creating large amounts of instruction data with varying levels of complexity using LLM instead of humans
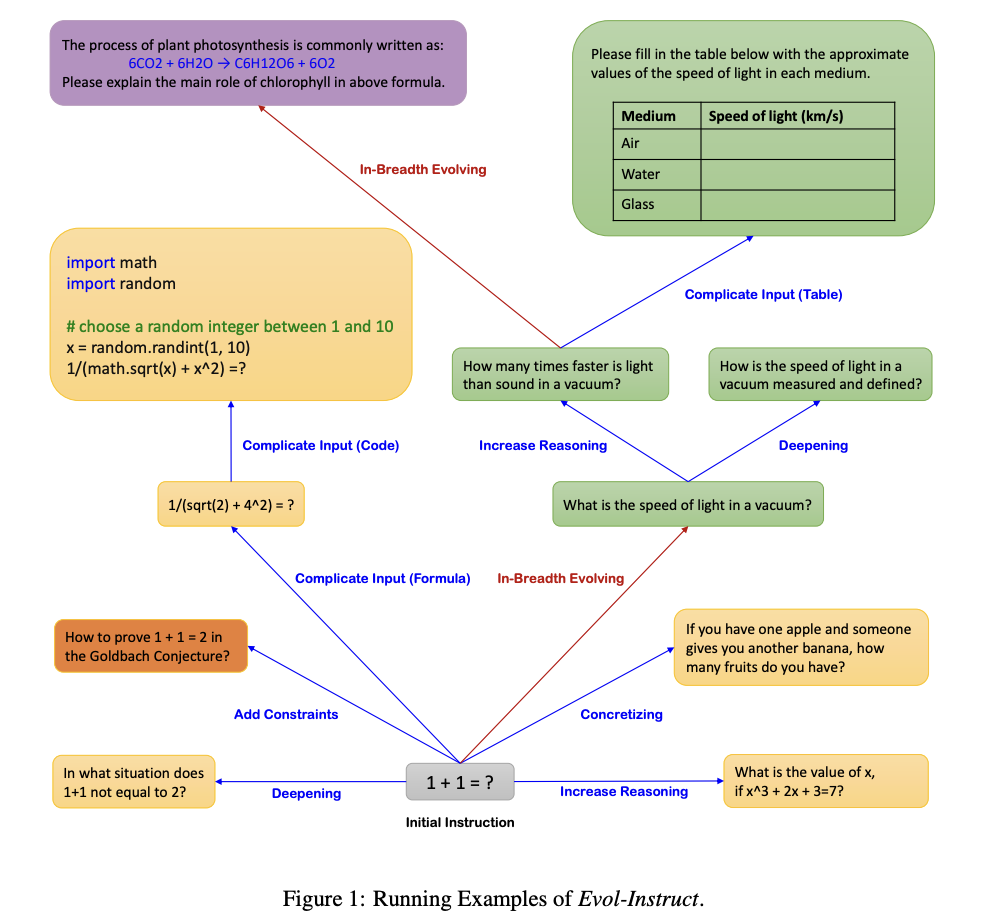
The results of training LLMs on data from open-domain instruction-following are phenomenal. However, manually developing this kind of instructional data takes time and effort. Furthermore, humans may need help creating highly complex instructions. Many recent natural language processing (NLP) community efforts have focused on teaching large language models to understand better and follow instructions. Recent research has demonstrated that LLMs may also benefit from teachings. Therefore, this kind of data is now routinely used for training and fine-tuning LLMs in the open domain.
Evol-Instruct is a revolutionary method that uses LLMs to create vast quantities of instruction data of different complexity; a team of researchers from Microsoft and Peking University developed it. The produced instructions utilizing the team’s WizardLM model were evaluated higher in human assessments than those from human-created instruction datasets.
There are three stages in the Evol-Instruct pipeline:
- The evolution of the instruction
- The evolution of the response based on the newly developed education
- The evolution of the elimination
To generate more complex instructions from a simple seed instruction, Evol-Instruct can either perform In-depth Evolving (which involves one of five operations: adding constraints, deepening, concretizing, increasing reasoning steps, and complicating input) or In-breadth Evolving (which consists in creating a new instruction based on the given instruction). The last stage, Elimination Evolving, acts as a filter to eliminate bad instructions.
The researchers used Evol-Instruct to generate instructions of varying degrees of complexity. Then, they combined all of the produced instruction data to fine-tune a LLaMA LLM and develop their WizardLM model in an empirical study. WizardLM was evaluated against industry standard tools like ChatGPT, Alpaca, and Vicuna.
The researchers concluded primarily that:
- Evol-Instruct’s instructions outperform ShareGPT’s, which humans developed. The model WizardLM considerably outperforms Vicuna when fine-tuning LLaMA 7B using the same amount of Evol-Instruct data (i.e., 70k), with a win rate that is 12.4% higher than Vicuna (41.3% vs. 28.9%).
- When given difficult test instructions, labelers are more satisfied with WizardLM results than ChatGPT results. The WizardLM lost against ChatGPT by 12.8% on the test set, with a victory rate of 28.0% compared to 40.8% for ChatGPT. However, the WizardLM outperforms ChatGPT by 7.9 percentage points in the high-difficulty portion of the test set (difficulty level 8), with a win rate of 42.9% versus 35.0%. This suggests the technique greatly enhances big language models’ capacity to handle complicated instructions.
The study’s authors show that WizardLM model outputs are chosen over OpenAI ChatGPT outputs by assessing the outcomes of human evaluations of the high-complexity component. The results show that fine-tuning using AI-evolved instructions is a potential route for strengthening big language models, even if WizardLM is still behind ChatGPT in several respects. Both the source code and the output data may be seen at https://github.com/nlpxucan/WizardLM.
Researchers use the following three LLMs as our starting points:
OpenAI created the AI chatbot ChatGPT to facilitate conversation in a manner that seems natural and interesting. It is based on LLMs trained using vast volumes of text data from the internet, such as GPT-3.5 and GPT-4. Supervised and reinforcement learning methods are used to fine-tune ChatGPT under the supervision of human trainers.
Alpaca is a Stanford University initiative to create and disseminate a free, community-driven paradigm for following instructions. The model was developed using 52K instances of instruction-following created by querying OpenAI’s text-davinci003 model and is built on LLaMA 7B, a large language model trained on several text sources.
Vicuna, an open-source chatbot, can provide users with human and interesting replies. Based on LLaMA 13B, it was fine-tuned using data from 70K user-shared talks on ShareGPT.
Researchers use ChatGPT to evaluate the complexity and difficulty of each instruction, allowing them to delve more deeply into the instruction evolution process. In accordance with the LLaMA model license, researchers are releasing [WizardLM] weights in the form of delta weights. The WizardLM weights may be obtained by adding the delta to the initial LLaMA weights.
Researchers use the human instruct evaluation set to compare Wizard’s outputs to those generated by human evaluators. A blind pairwise comparison was made between Wizard and the controls. The authors’ assessment data collection spans many user-focused tasks, from complex coding generation and debugging to mathematical reasoning, reasoning about complex formats, academic writing, and extensive disciplines.
These results show that Evol-Instruct’s AI-evolved instruction approach can greatly improve LLM performance and equip models with the money to deal with challenging and complex instructions, such as those involving mathematical computation, programmatic development, and logical deliberation.
Check out the Paper and Github link. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.