MIT Researchers Propose AbMAP: A Protein Language Model (PLM) Customized For Antibodies
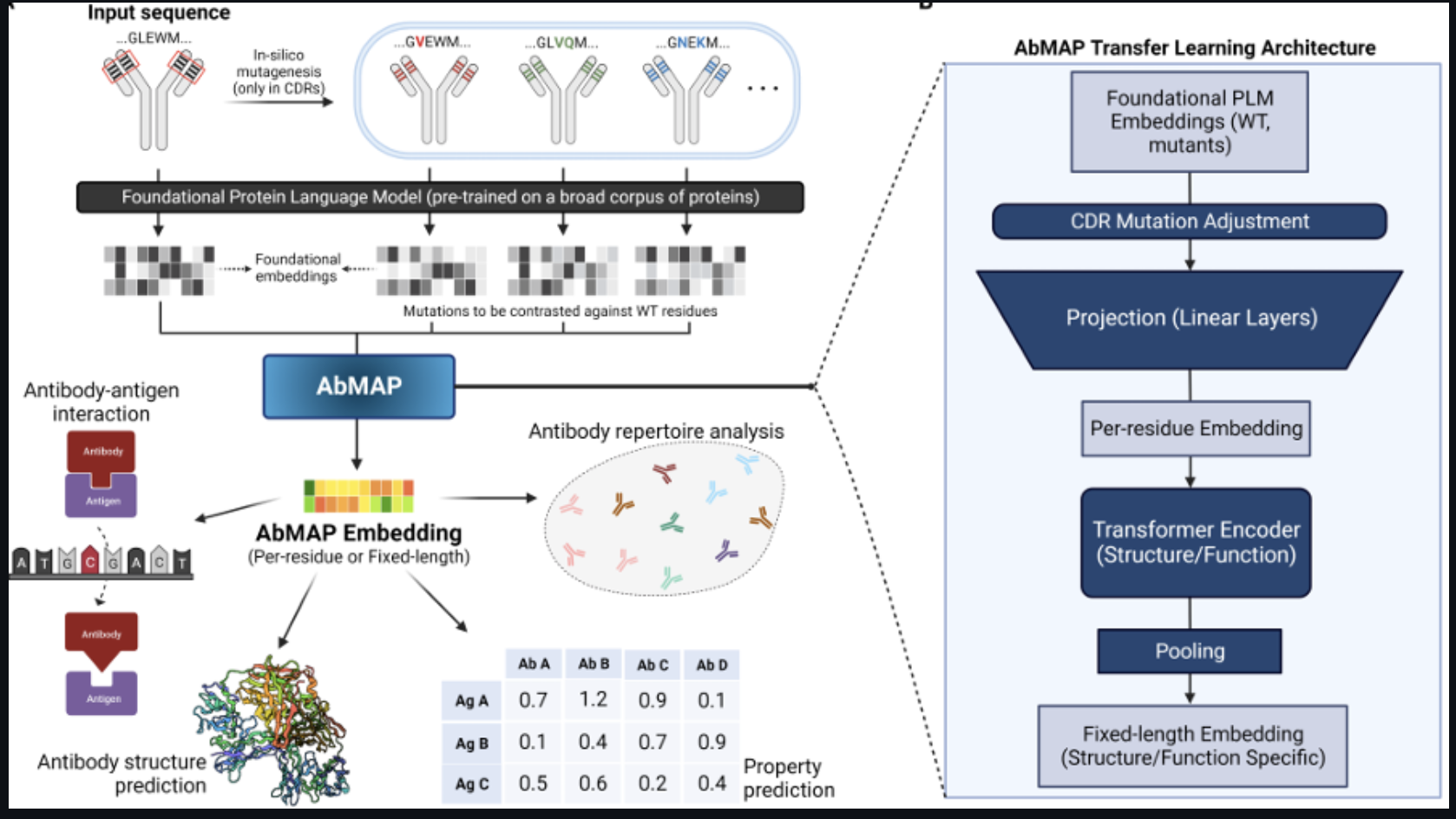
Some of the most promising medication candidates in current therapies have been antibodies. The incredible structural diversity of antibodies, which enables them to recognize an incredibly broad array of possible targets, is to thank for this therapeutic success. Their hypervariable sections, which are essential to the functional specificity of antibodies, are where this variety emerges. In the past, methods like immunization or directed evolution methods like phage display selection have been used to develop an antibody against a target of interest experimentally. The creation and screening procedure, however, is time- and money-consuming. The potential structure space must be thoroughly explored, which can provide candidates with unfavorable binding properties.
Since antibody structures’ hypervariable sections exhibit structurally distinctive evolutionary patterns, general protein structure-prediction methods can have difficulty predicting them. Furthermore, it is difficult to take into account downstream issues readily. Therefore, there is a need for computational techniques that either more effectively refine a small number of experimentally determined candidates or develop a brand-new antibody from scratch for a specific target. Modeling the 3D structure of the complete antibody or its CDRs has been one step in this approach, but the accuracy of these models could be better. It cannot conduct large-scale computational exploration or analyze a person’s antibody repertoire, which may comprise millions of sequences because they are sluggish and take many minutes per antibody structure.
Recently, high-dimensional protein representations have been created using machine learning methods employed in natural language processing. Protein language models allow for the prediction of protein properties while implicitly capturing structural characteristics. One approach is hiring PLMs trained on all proteins’ corpus when discussing antibodies. We refer to these as “foundational” PLMs, which is machine learning speak for big, all-purpose models. However, the sequence diversity in CDRs is not evolutionarily limited, which means that the CDRs of antibodies directly violate the distributional premise behind fundamental PLMs. One of the main reasons AlphaFold 2 performs less effectively on antibodies than on ordinary proteins is the need for more high-quality multiple sequence alignments.
Because of this, a different set of methods known as IgLM have been suggested by researchers from MIT and Sanofi R&D Cambridge. These methods train the PLM only on antibody and B-cell receptor sequence repertoires. These methods are more effective at addressing the CDRs’ hypervariability. Still, they need the varied corpus of all protein sequences to base their training, preventing them from accessing the deep understanding provided by basic PLMs. Additionally, current methods like AntiBERTa spend significant explanatory power modeling the antibody’s non-CDRs, which are considerably less varied and less important for antibody binding-specificity.
Their main conceptual contribution is to use supervised learning techniques trained on antibody structure and binding specificity profiles to solve the shortcoming of fundamental PLMs on antibody hypervariable regions. They specifically introduce three important advances:
- We are maximizing the use of the data available by restricting the learning task to hypervariable antibody regions.
- They are refining the baseline PLM’s hypervariable region embeddings to better capture antibody structure and function.
- It is developing a multi-task supervised learning formulation that considers binding specificity and antibody protein structure to oversee the representation.
Therefore, this approach can aid in assessing potential antibody sequences for druggability before costly in vitro and pre-clinical studies.
Check out the Research Paper and Code. Don’t forget to join our 20k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.