Researchers from China Propose StructGPT to Improve the Zero-Shot Reasoning Ability of LLMs over Structured Data
Large language models (LLMs) have recently made significant progress in natural language processing (NLP). Existing research has shown that LLMs) have strong zero-shot and few-shot capacities to complete various tasks with the aid of specifically created prompts without task-specific fine-tuning. Despite their effectiveness, according to current research, LLMs may produce untruthful information at odds with factual knowledge and fall short of mastering domain-specific or real-time expertise. The problems may be directly resolved by adding external knowledge sources to LLMs to repair the wrong generations.
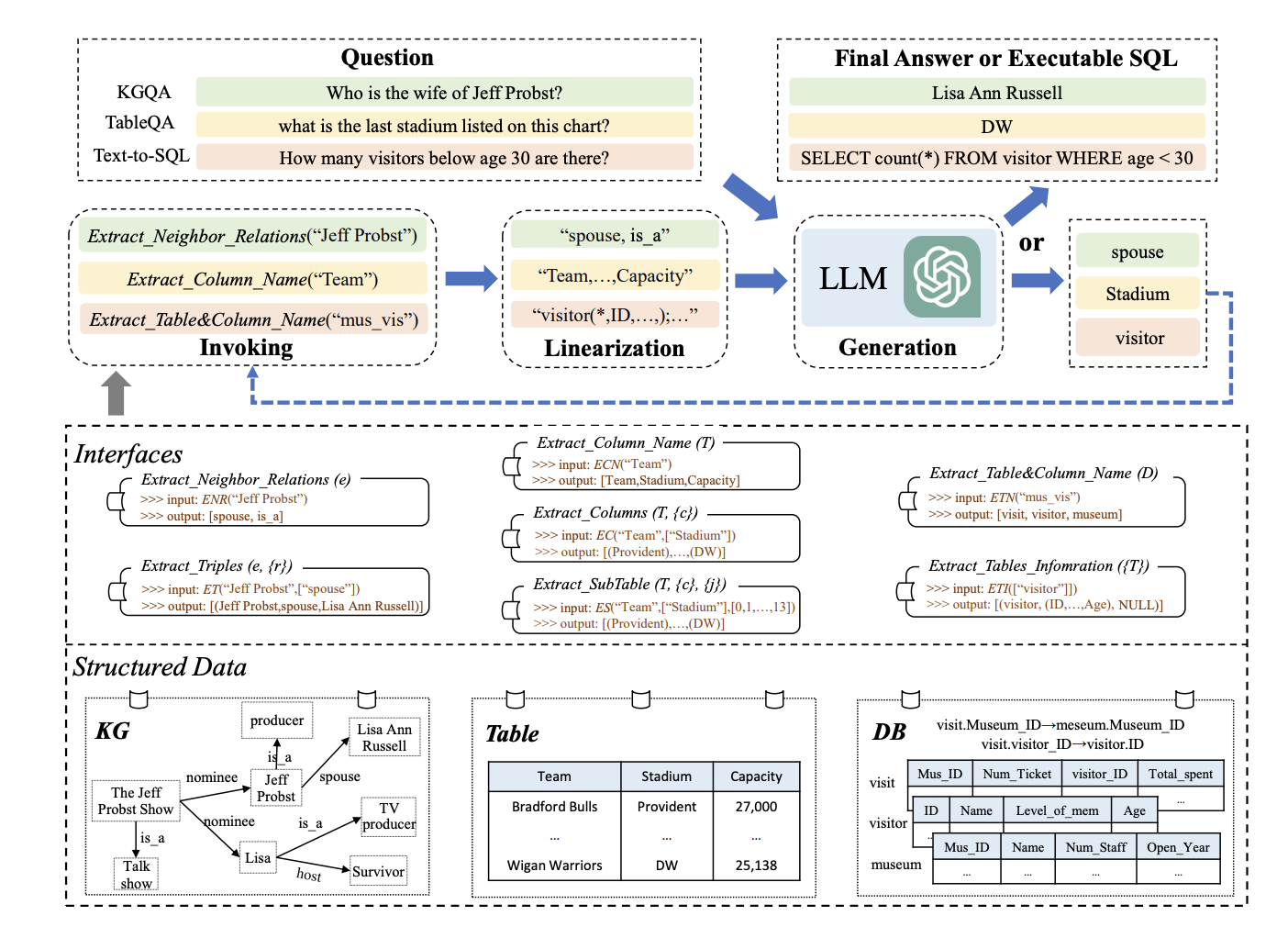
Structured data, such as databases and knowledge graphs, has been routinely employed to carry the knowledge needed for LLMs among various resources. However, because structured data uses unique data formats or schemas that LLMs were not exposed to during pre-training, they might need help to understand them. Structured data, as opposed to plain text, is arranged in a consistent manner and follows a certain data model. Data tables are arranged as column-indexed records by rows, whereas knowledge graphs (KGs) are frequently organized as fact triples describing the relationships between head and tail entities.
Although the volume of structured data is frequently enormous, it is impossible to accommodate all the data records in the input prompt (for example, ChatGPT has a maximum context length of 4096). The linearization of the structured data into a statement that LLMs can easily grasp is a simple solution to this issue. The tool manipulation technique motivates them to enhance LLMs’ capabilities about the aforementioned difficulties. The fundamental idea behind their strategy is to use specialized interfaces to alter the structured data records (for instance, by extracting columns for tables). With the help of these interfaces, they may more precisely locate the needed proof to complete particular activities and successfully limit the search area of the data records.
Researchers from the Renmin University of China, Beijing Key Laboratory of Big Data Management and Analysis Methods, and the University of Electronic Science and Technology of China in this study focus on designing appropriate interfaces for certain tasks and using them for reasoning by LLMs, which are the two primary issues that need to be solved to apply the interface-augmented method. In this fashion, LLMs may make decisions based on the evidence gathered from the interfaces. To do this, they provide an Iterative Reading-then-Reasoning (IRR) method in this study called StructGPT for resolving tasks based on structured data. Their method considers two key responsibilities to complete various activities: gathering pertinent data (reading) and assuming the correct response or formulating a strategy for the next action (reasoning).
To their knowledge, this is the first study that looks at how to help LLMs in reasoning on various forms of structured data (such as tables, KGs, and DBs) using a single paradigm. Fundamentally, they separate the two reading and reasoning processes for LLMs: they use structured data interfaces to accomplish precise, effective data access and filtering and rely on their reasoning capacity to determine the next move or the answer to the query. With external interfaces, they specifically suggest an invoking-linearization generation process to assist LLMs in understanding and making decisions on structured data. They may gradually come closer to the desired response to a query by repeating this process with the supplied interfaces.
They do comprehensive trials on various tasks (such as KG-based question answering, Table-based question answering, and DB-based Text-to-SQL) to assess the efficacy of their technique. Experimental findings on eight datasets show that their suggested methodology may significantly improve ChatGPT’s reasoning performance on structured data, even to the level of competing full-data supervised-tuning approaches.
• KGQA. Their method results in an increase of 11.4% in Hits@1 on WebQSP for the KGQA challenge. With the aid of their method, ChatGPT’s performance in multi-hop KGQA datasets (such as MetaQA-2hop and MetaQA-3hop) may be enhanced by up to 62.9% and 37.0%, respectively.
• QA Table. In the TableQA challenge, their method increases denotation accuracy by around 3% to 5% in WTQ and WikiSQL compared to utilizing ChatGPT directly. In TabFact, their method increases accuracy in table fact verification by 4.2%.
• Text to SQL. In the Text-to-SQL challenge, their method increases execution accuracy across three datasets by about 4% compared to utilizing ChatGPT directly.
The authors have released the code for Spider and TabFact, which can help understand the framework of StructGPT, and the whole codebase is yet to be released.
Check out the Paper and Github link. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.