Researchers Introduce SPFlowNet: An End-To-End Self-Supervised Approach For 3D Scene Flow Estimation
The field of scene flow estimation, which seeks to estimate motion between two successive frames of point clouds, is integral to a myriad of applications, from estimating the motion of objects around a vehicle in autonomous driving to analyzing sports movements. The development of 3D sensors, such as Lidar or stereo-vision cameras, has stimulated research into the topic of 3D scene flow estimation. In a paper from Nanjing University of Science and Technology, researchers in China have introduced a novel end-to-end self-supervised approach for scene flow estimation.
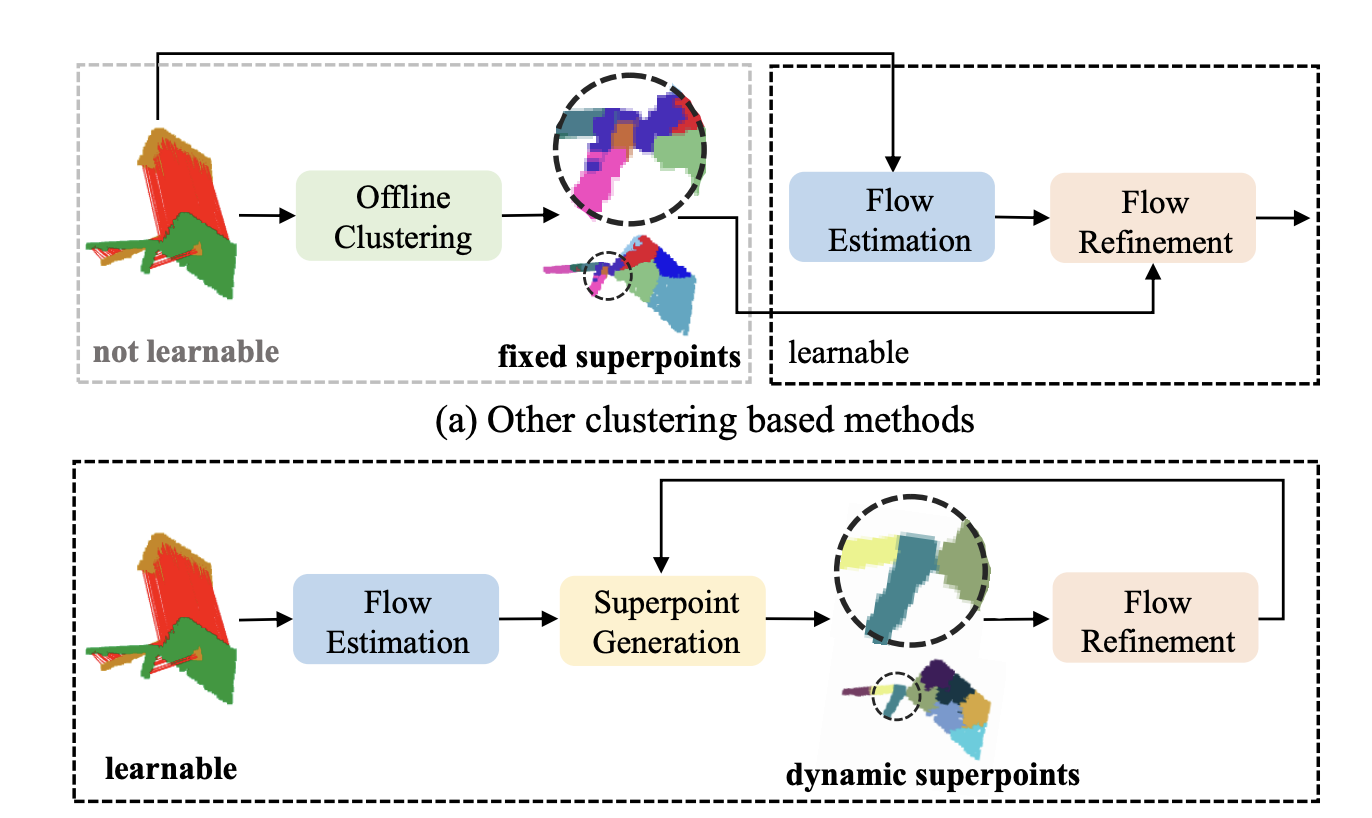
Traditionally, this task is performed in two steps: identifying points or clusters of interest (which could be moving) within a point cloud and then estimating the flow based on the calculated point displacement. The estimation of point cloud clusters typically relies on hand-crafted algorithms, which can yield inaccurate results for complex scenes. Once the point clouds are generated by these algorithms, they remain fixed during the flow estimation step, leading to potential error propagation over time and imprecise flow estimation. This can occur when points with different underlying flow patterns – for example, points associated with two objects moving at different speeds – are assigned to the same superpoint. Recent approaches have explored the use of supervised methods employing deep neural networks to estimate the flow from point clouds directly, but the scarcity of labeled ground-truth data for flows makes the training of these models challenging. To address this issue, self-supervised learning methods have recently emerged as a promising framework for end-to-end scene flow learning from point clouds.
In their paper, the authors propose SPFlowNet (Super Points Flow guided scene estimation), an end-to-end approach for point segmentation, based on the existing work of SPNet. SPFlowNet takes as input two successive point clouds, P and Q (each containing 3-dimensional points), and attempts to estimate the flow in both directions (from P to Q and from Q to P). What sets this approach apart from others is the flow refinement process used, which allows for the dynamic updating of superpoints and flows. This process involves an iterative loop that estimates pairs of Flows F_t. The method can be summarized as follows:
- At the outset (t=0), a feature encoder is applied to point clouds P and Q, which calculates an initial guess of the flow pair, F₀. Both point clouds and the flow estimate are then fed into an algorithm called farthest point sampling (FPS), which assigns superpoints to each point cloud.
- For t>0, the estimated flows F_t and superpoints are iteratively updated as depicted in the image below. The flow refinement process uses the latest superpoint estimate to compute F_t, which is subsequently used to calculate the pair of superpoint clouds, SP_t. Both processes involve learnable operators.
The training of the neural network involves a specific loss function, L, which includes a regularized Chamfer loss with a penalty on the flow’s smoothness and consistency. The Chamfer loss is given by the following equation:
Here, points of P’ refer to points of the cloud P, moved by the estimated flow F_t.
The overall framework can be considered self-supervised as it does not require the existence of ground truth in the predicted loss function. Notably, this approach achieves state-of-the-art results by a significant margin in the considered benchmark while being trained on modest hardware. However, as discussed in the paper, some parameters remain hand-tuned, including the unsupervised loss function, the number of iterations, T, and the number of superpoints centers, K, considered.
In conclusion, the SPFlowNet presents a significant stride forward in 3D scene flow estimation, offering state-of-the-art results with modest hardware. Its dynamic refinement of flows and superpoints addresses crucial accuracy issues in current methodologies. This work showcases the potential of self-supervised learning for advancing applications where precise motion capture is important.
[1] Learning representations for rigid motion estimation from point clouds. In CVPR, 2019
[2] 3d scene flow estimation on pseudo-lidar: Bridging the gap on estimating point motion
[3] Superpoint network for point cloud over-segmentation. In ICCV, 2021. 3, 8
Check out the Paper. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Simon Benaïchouche received his M.Sc. in Mathematics in 2018. He is currently a Ph.D. candidate at the IMT Atlantique (France), where his research focuses on using deep learning techniques for data assimilation problems. His expertise includes inverse problems in geosciences, uncertainty quantification, and learning physical systems from data.
Credit: Source link
Comments are closed.