Researchers From China Propose a Generate-and-Edit Approach that Utilizes Execution Results of the Generated Code from LLMs to Improve the Code Quality in the Competitive Programming Task
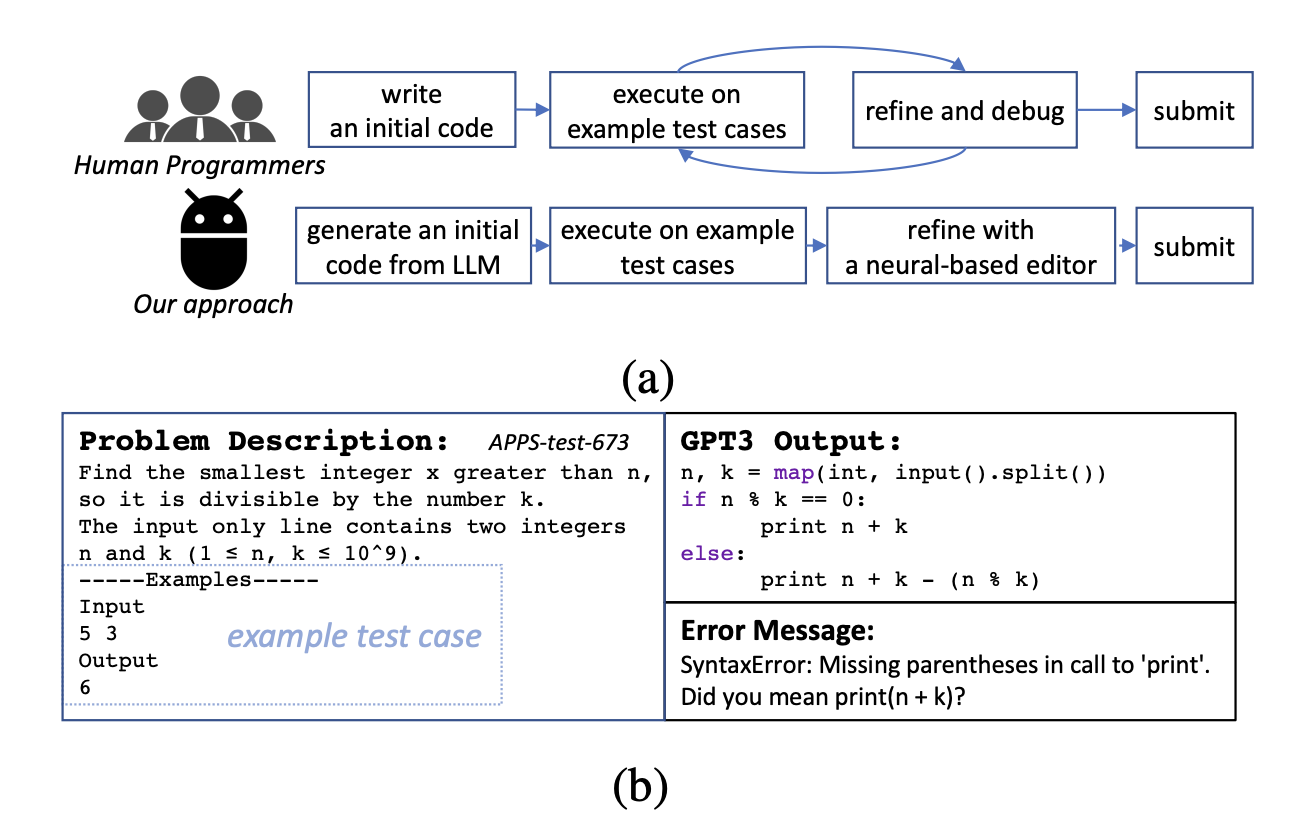
Researchers draw inspiration from the process of human programming to help LLMs do better in competitive programming jobs. The competitive programming job has recently been applied to large language models. This work necessitates accurately implementing solutions that can span hundreds of lines and comprehending a sophisticated natural language description of a problem with example test cases. Executing solutions on concealed test cases allows for solution evaluation. However, current LLMs’ accuracy and pass rates could be higher for this purpose. For instance, on the widely used APPS test, a competitive programming benchmark, the virtually most powerful model GPT3 only scores 7% accuracy.
Programmers often develop an initial program, run a few sample test cases, and then make changes to the code in response to the test findings while resolving competitive programming difficulties. During this step, the programmer may use important information from the test results to troubleshoot the software. They implement this concept by using a comparable workflow with a neural-based editor. The code produced by a pre-trained LLM was examined, and it was discovered that several of the generated codes might be enhanced with small adjustments.
They see that the error message identifies the coding fault, allowing them to correct the problem rapidly. It encourages us to look into editing methods and enhance the code quality produced by LLMs with the aid of execution outcomes. In this study, researchers from Peking University suggest a unique generate-and-edit approach to improve LLMs at competitive programming tasks. Their method uses the capability of LLMs in three phases to emulate the behavior of the human programmers mentioned above:
- Generation utilizing LLMs. They create the program based on the problem description using huge language models like black box generators.
- Execution. They run the created code on the sample test case using LLMs to obtain the execution results. They also offer templates for the execution results as additional comments to include more useful data for modification.
- Edit. They create a fault-aware neural code editor that improves the code using the produced code and additional comments as input. Their code editor strives to raise the caliber and precision of LLM-based code production.
They conduct in-depth research on the APPS and HumanEval public competitive programming benchmarks. To demonstrate the universality, they apply their methodology to 9 well-known LLMs with parameter values ranging from 110M to 175B. Their strategy dramatically raises LLM’s performance. In particular, their method raises the average of pass@1 on APPS-dev and APPS-test by 89% and 31%, respectively. Their tiny editor model can increase pass@1 from 26.6% to 32.4% on the APPS-dev test, even for the biggest language model used, GPT3-175B. They prove the transferability of their method on the out-of-distribution benchmark by improving the average of pass@1 by 48% on a new kind of dataset called HumanEval. Various methods for post-processing programs created by LLMs have recently been presented.
These methods do extensive LLM sampling, rerank the sampled programs, and produce the final program. Their strategy, in contrast, provides two benefits: Their method keeps the sample budget constant and drastically lowers the computational burden on LLMs. Their editor alters the programs directly and outperforms these reranking-based techniques, particularly with a constrained sample budget like pass@1. They are the first, as far as they are aware, to use an editing-based post-processing technique for programming competitions.
The following is a list of the contributions:
• To produce high-quality code for challenging programming jobs, they suggest a generate-and-edit method for huge language models.
• They create a fault-aware neural code editor that uses error messages and produces code as input to improve the code’s precision and quality.
• They do trials using two well-known datasets and nine LLMs to show the potency and applicability of their strategy.
Check out the Paper. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.