4 Prompting Techniques For Solving Difficult and Multi-Step Problems With LLMs
When it comes to tackling reasoning-based problems, large language models (LLMs) have a terrible reputation. Their reasoning performance can, however, be greatly enhanced by applying straightforward methods that don’t demand fine-tuning or task-specific verifiers. Chain-of-thought (CoT) prompting is the name for this method. Specifically, it uses few-shot learning to enhance LLMs’ capacity for deductive thinking. Many more advanced prompting strategies build on the chain of thought (CoT) prompting foundation, useful for addressing difficult, multi-step problems with LLMs.
Here are four methods of prompting that can help LLMs work through complex, multi-step problems presented by the collective efforts from researchers Google, the University of Tokyo, Peking University, and Microsoft:
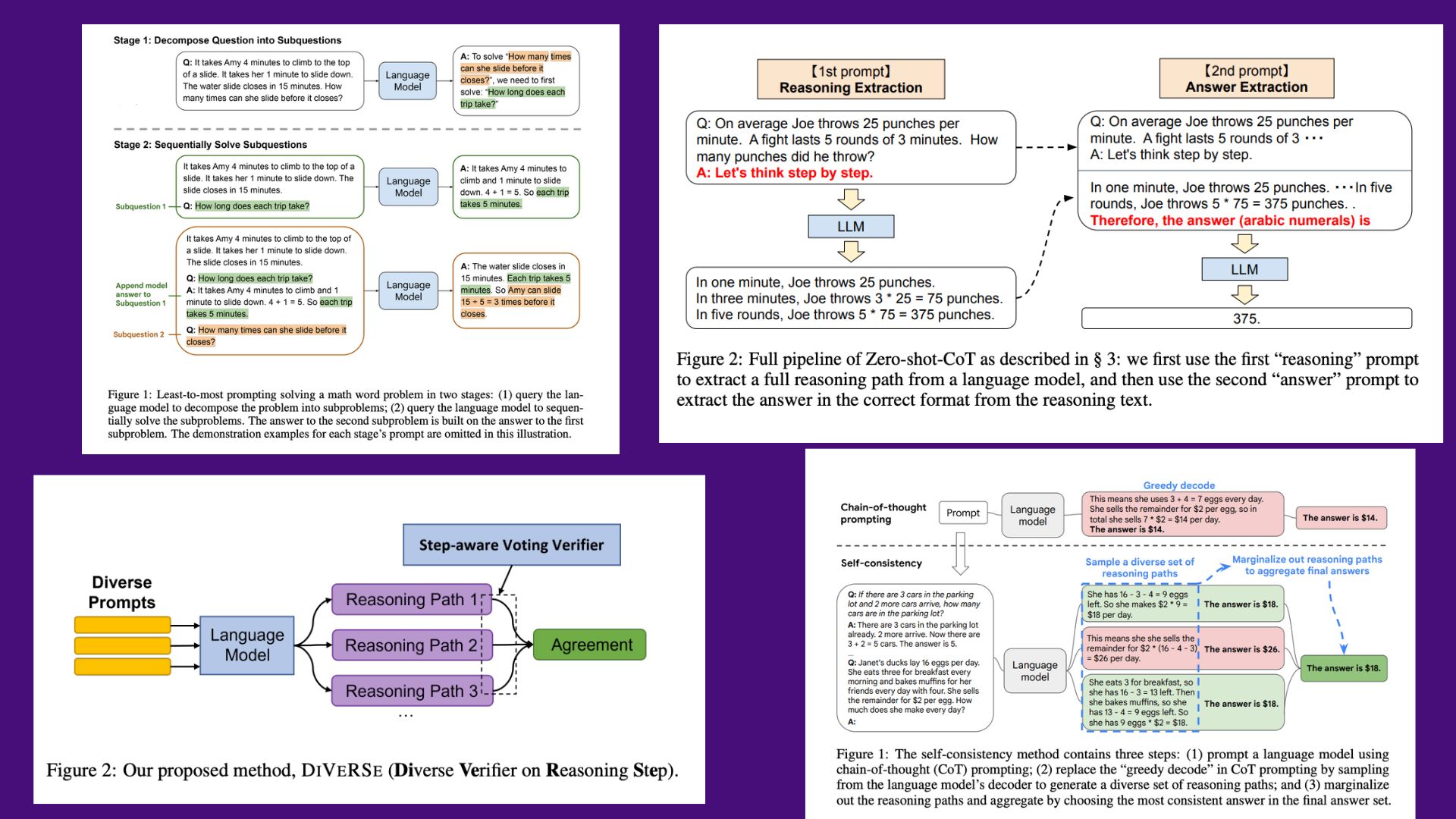
1. Zero-Shot CoT
In a scenario where the traditional zero-shot strategy fails, Zero-shot-CoT constructs a reasonable reasoning path in a zero-shot manner and finds the correct solution. This is achieved without resorting to few-shot learning by inserting “Let’s think step by step” into the query. Unlike previous task-specific prompt engineering, which typically took the form of examples (few-shot) or templates (zero-shot), Zero-shot-CoT is flexible and task-agnostic, allowing it to facilitate step-by-step answers across a wide range of reasoning tasks (such as arithmetic, symbolic reasoning, commonsense reasoning, and other logical reasoning tasks) without requiring any prompt modification.
2. Least-to-most Prompting
The LLM problem-solving method involves openly decomposing a problem into smaller, more manageable chunks, with the results of each chunk being fed into the next.
It has two distinct phases:
- Decomposition: At this point, the question that needs decomposing is presented in the prompt, followed by a series of constant instances illustrating the decomposition.
- Problem-Solving: At this point, the question to be answered is preceded by a set of constant instances illustrating how the subproblems are addressed, followed by a list of previously answered subquestions and generated solutions, and finally, the question itself.
Prompting from least to most can be used with other methods, such as chain of reasoning and self-consistency, but this is not required. The two phases of least-to-most prompting can be combined into a single pass for specific activities.
3. Self-consistency
The reasoning ability of language models is further improved by using a unique decoding method called self-consistency in place of the greedy decoding technique utilized in chain-of-thought prompting. To achieve self-consistency, researchers work on the intuition that there are several valid routes to a solution for most complicated reasoning tasks. The more time and effort must be put into thinking about and analyzing a problem, the more possible routes of reasoning there are to arrive at a solution. The ultimate decision is then made by a vote of the majority.
4. Diverse
In addition to self-consistency, DiVeRSE trains a second verification module to infer/aggregate the right answer from various generated reasoning paths using a technique called prompt ensembles (a group of prompts that all address the same problem).
DIVERSE is a powerful and general strategy for improving the reasoning abilities of big language models. The key ideas of various are threefold: various prompts, a voting verifier, and step-level correctness. Using codedavinci-002, DIVERSE outperforms the 540B PaLM model and prior prompting methods combined to produce state-of-the-art results in most reasoning tests.
Check out the Paper 1, Paper 2, Paper 3, and Paper 4. This article is inspired from this Tweet. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.