Meet MultiModal-GPT: A Vision and Language Model for Multi-Round Dialogue with Humans
Humans engage with the environment in various ways, including through vision and language. Each has a special benefit in expressing and communicating certain ideas about the world and promoting a deeper knowledge of it. A key goal of artificial intelligence research is to develop a flexible assistant capable of successfully executing multimodal vision-and-language commands that reflect human intents. This assistant would be capable of completing a wide range of activities in the real world. GPT-4 has been proven to be incredibly skilled at multimodal conversations with humans.
Even though GPT-4’s remarkable skills have been shown, its underlying mechanisms continue to be a mystery. By matching visual representations with the input space of the LLM and then utilizing the original self-attention in the LLM to process visual information, studies like Mini-GPT4 and LLaVA have attempted to recreate this performance. However, because of the high amount of picture tokens, including such models with comprehensive or spatiotemporal visual information might be computationally expensive. In addition, both models leverage vicuna, an open-source chatbot that has been improved by fine-tuning LLaMA on user-generated dialogues via ChatGPT, skipping the research’s language instruction tuning step.
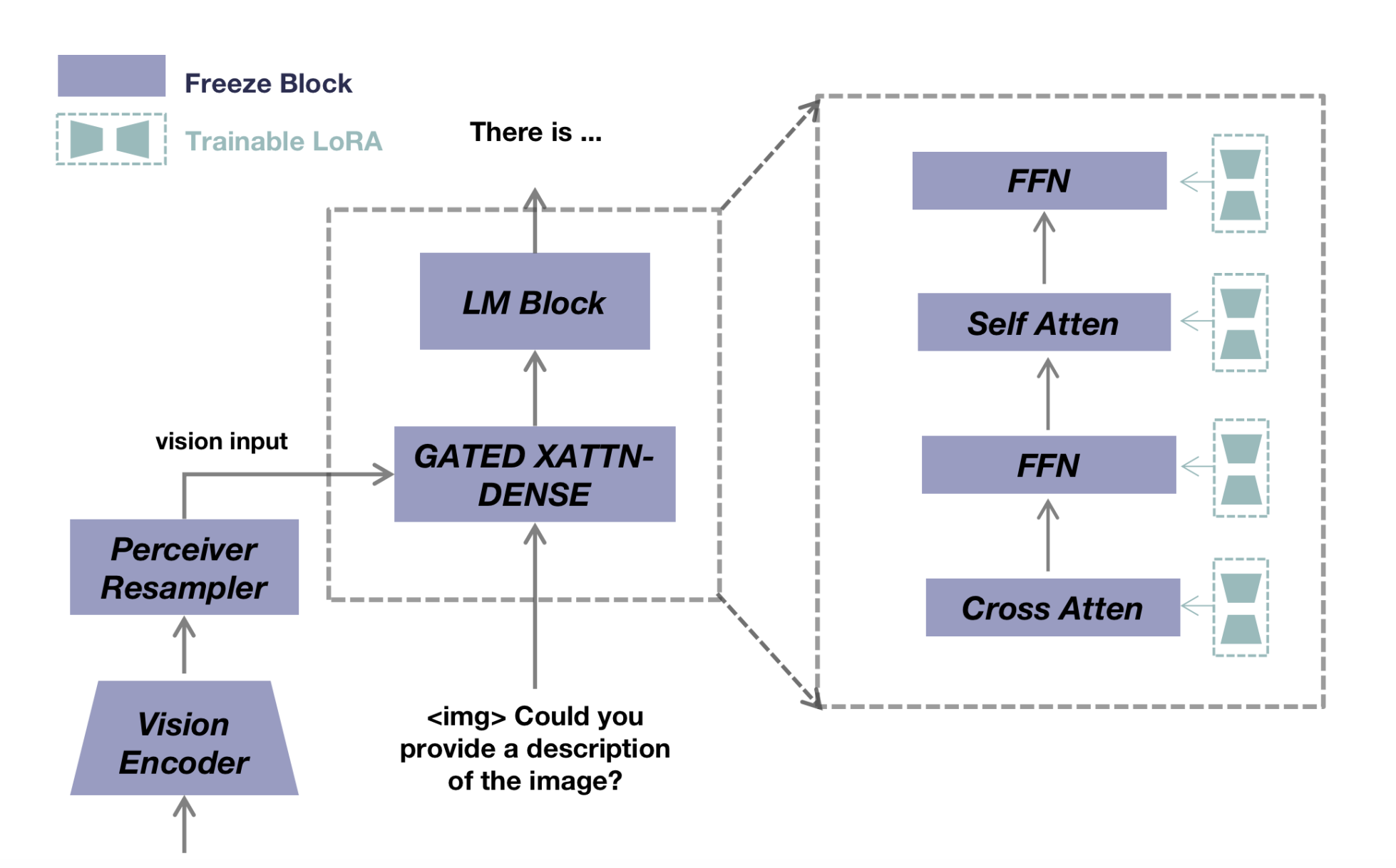
They want to improve OpenFlamingo to have conversations more aligned with human tastes by employing a large picture and text instructions database. Researchers from Shanghai AI Laboratory, the University of Hong Kong and Tianjin University use the open-source Flamingo framework, a multimodal pre-trained model that employs gated cross-attention layers for image-text interactions, and a perceiver resampler to effectively extract visual information from the vision encoder to address these problems. This model has strong few-shot visual comprehension abilities since it has been pre-trained on a large dataset of image-text pairings. However, it is unable to participate in zero-shot, multiturn image-text discussions.
They aim to close the performance gap between the model’s current capabilities and the anticipated consequence of more precise, human-like interactions in multimodal conversations by using OpenFlamingo’s fundamental strengths. Their multimodal chatbot is known as MultiModal-GPT. During model training, they adopt a common linguistic and visual instructions template. To train the MultiModal-GPT, they first create instruction templates using language and graphical data. They discover that the training data is crucial to the MultiModalGPT’s effectiveness.
Some datasets, such as the VQA v2.0, OKVQA, GQA, CLEVR, and NLVR datasets, will cause the MultiModal-GPT’s conversation performance to suffer since each response can only be one or two words (for example, yes/no). As a result, the model shows a propensity to provide replies with just one or two words when these datasets are included in the training process. This brevity does not support user-friendliness. They also gather linguistic data and create a common instruction template to jointly train the MultiModal-GPT to improve its capacity to converse with humans. The model performs better when given combined training with language-only and visual and linguistic instructions. To demonstrate the capability of MultiModal-GPT’s ongoing communication with people, they provide a variety of demos. They also make the codebase publicly available on GitHub.
Check out the Paper and Repo. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.