Meta AI Researchers Propose MEGABYTE: A Multiscale Decoder Architecture that Enables End-to-End Differentiable Modeling of Sequences of Over One Million Bytes
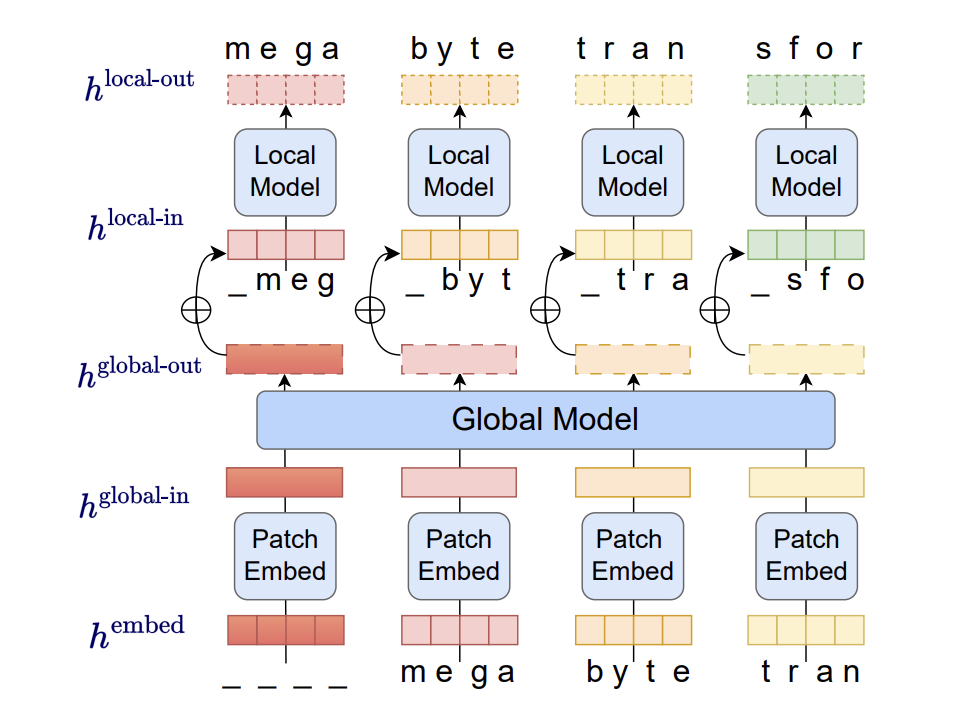
Million-byte sequences are common as music, picture, and video files frequently have several megabyte sizes. However, because of the quadratic cost of self-attention and, more significantly, the expense of large feedforward networks per position, large transformer decoders (LLMs) normally only require a few thousand tokens of context. This significantly reduces the range of tasks for which LLMs may be used. Researchers from META present MEGABYTE, a novel method for simulating lengthy byte sequences. Byte sequences are divided into fixed-sized patches roughly equivalent to tokens.
Then, their model has three components:
(1) A local module, a tiny autoregressive model that forecasts bytes within a patch.
(2) A patch embedder merely encodes a patch by losslessly concatenating embeddings of each byte.
(3) A global module, a big autoregressive transformer that inputs and outputs patch representations.
Importantly, most byte predictions are straightforward for many tasks (such as completing a word given the initial few letters), negating the need for massive networks per byte and allowing for considerably smaller models for intra-patch modeling. For extended sequence modeling, the MEGABYTE architecture offers three key advantages over Transformers: Self-attention that is sub-quadratic The vast majority of research on long sequence models has been devoted to reducing the quadratic cost of self-attention. Lengthy sequences are divided into two shorter sequences using MEGABYTE, and the self-attention cost is decreased to O(N(4/3)) by using optimum patch sizes, which are still tractable for lengthy sequences. Layers with per-patch feedforward. MEGABYTE allows for far bigger and more expressive models at the same cost by using huge feedforward layers per patch rather than per position. More than 98% of FLOPS are used in GPT3-size models to compute position-wise feedforward layers.
Decoding Parallelism three Transformers must serially process all calculations during generation since each timestep’s input results from the initial output. MEGABYTE makes Greater parallelism during generation possible thanks to the parallel production of representations for patches. With patch size P, MEGABYTE may utilize a layer with mP parameters once for the same price as a baseline transformer, using the same feedforward layer with m parameters P times. For instance, when trained on the same compute, a MEGABYTE model with 1.5B parameters may create sequences 40% quicker than a conventional 350M Transformer while increasing perplexity.
Together, these enhancements enable us to expand to lengthy sequences, increase generation speed during deployment, and train much bigger and better-performing models for the same computational budget. Sequences of bytes are translated into bigger discrete tokens in existing autoregressive models, which generally involve some tokenization. This is where MEGABYTE stands in stark contrast. Tokenization makes pre-processing, multi-modal modeling, and transfer to different domains more difficult while obscuring the model’s beneficial structure. Additionally, it implies that most cutting-edge models are still in progress. The most popular methods of tokenization lose information without language-specific heuristics.
Therefore, switching from tokenization to performant and effective byte models would have several benefits. They carry out in-depth tests for both strong baselines and MEGABYTE. To concentrate their comparisons entirely on the model architecture rather than training resources, which are known to be advantageous to all models, they employ a single compute and data budget across all models. They discover that MEGABYTE enables byte-level models to reach state-of-the-art perplexities for density estimation on ImageNet, perform competitively with subword models on extended context language modeling, and allow audio modeling from raw audio data. These findings show that tokenization-free autoregressive sequence modeling is scaleable.
Check out the Paper. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.