Salesforce AI Introduces CodeT5+: A New Family of Open Code Large Language Models with an Encoder-Decoder Architecture
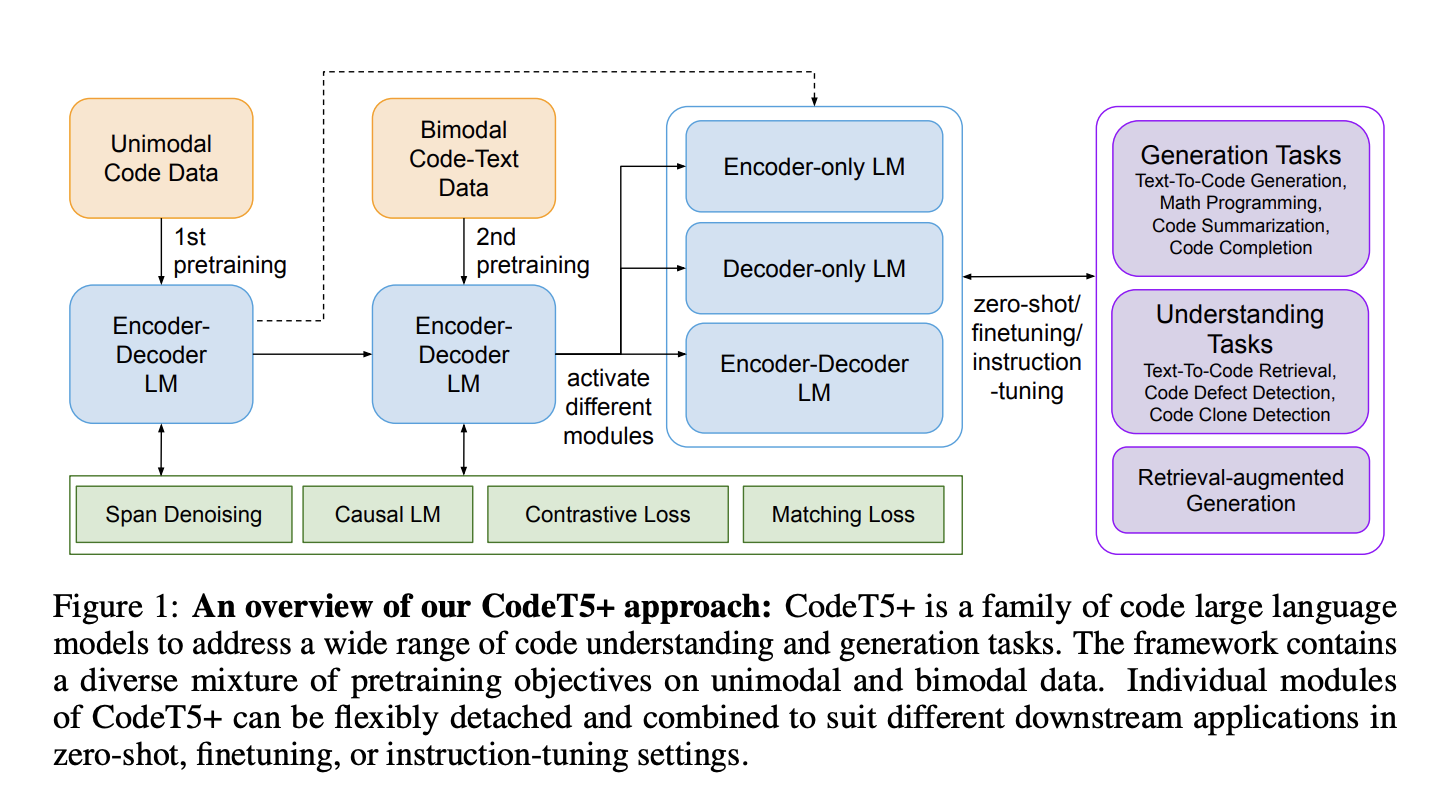
Modern large language models (LLMs) have excellent performance on code reading and generation tasks, allowing more people to enter the once-mysterious field of computer programming. Architecturally, existing code LLMs use encoder- or decoder-only models, which excel at just some comprehension and generating tasks. Code-focused LLMs typically have a limited set of pretraining objectives, which will degrade performance on downstream tasks that are less relevant to those objectives, and they often adopt an encoder-only or decoder-only architecture, which can limit their optimal performance to only specific tasks.
The AI Research team at Salesforce presents CodeT5+. It is a revolutionary family of encoder-decoder code foundation LLMs that can be easily customized to perform exceptionally well on various code interpretation and generation tasks. To do this, the team provides CodeT5+ with a wide range of pretraining objectives on unimodal and bimodal data to provide a code LLM that can be easily adapted to various downstream tasks.
What is CodeT5+
CodeT5+ is a set of large-scale language models for analyzing and generating code. The framework incorporates a wide range of unimodal and bimodal pretraining goals. CodeT5+’s modules can be separated and recombined flexibly to meet the needs of a wide variety of zero-shot, finetuning, and instruction-tuning applications.
While the decoder is trained to provide various outputs based on the pretraining learning tasks, the encoder learns to encode contextual representations from code/text sequences (entire, partial, or span-masked sequences).
- CodeT5+ is initially pretrained on large-scale unimodal data from public-facing platforms like GitHub. To teach the model how to recover code contexts in code spans, partial programs, and entire programs, this pretraining employs a variety of objectives, including span denoising, decoder-only causal LM, and seq2seq causal LM tasks.
- The second stage of pretraining uses text-code bimodal data, or combinations of text and code that provide the semantics of a code function. To enhance its cross-modal understanding and creation capabilities, CodeT5+ is here pretrained on cross-modal contrastive learning, matching, and causal LM tasks.
CodeT5+ can adapt its performance to various tasks thanks to its two-stage pretraining procedure, which includes seq2seq-generating tasks, decoder-only activities, and understanding-based tasks.
In their empirical investigation, the team compared CodeT5+ against 20 benchmark datasets and state-of-the-art code LLMs, including LaMDA, GPT, StarCoder, etc., on tasks including zero-shot, finetuning, and instruction-tuning. While competing against OpenAI’s robust code-cushman-001 model, CodeT5+ achieved State-of-the-Art (SOTA) outcomes on zero-shot HumanEval code creation tasks.
To sum it up
CodeT5+ is a new family of open-source, large-language models with an encoder-decoder architecture that may function in several modes (encoder-only, decoder-only, and encoder-decoder) to serve a variety of code interpretation and generation activities. CodeT5+ is trained using a variety of pretraining tasks, including span denoising, causal language modeling, contrastive learning, and text-code matching to acquire a comprehensive understanding of both unimodal and bimodal code-text data.
This work indicates that the proposed CodeT5+ open code LLMs can support and even reach SOTA performance across a wide range of downstream code jobs by operating flexibly in encoder-only, decoder-only, and encoder-decoder modes. The team is open-sourcing all CodeT5+ models to encourage further study because they believe CodeTs+ can be deployed as a unified retrieval-augmented generation system.
Check out the Paper and Github link. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.