Does The Segment Anything Model Work For Medical Images? This AI Study Explains
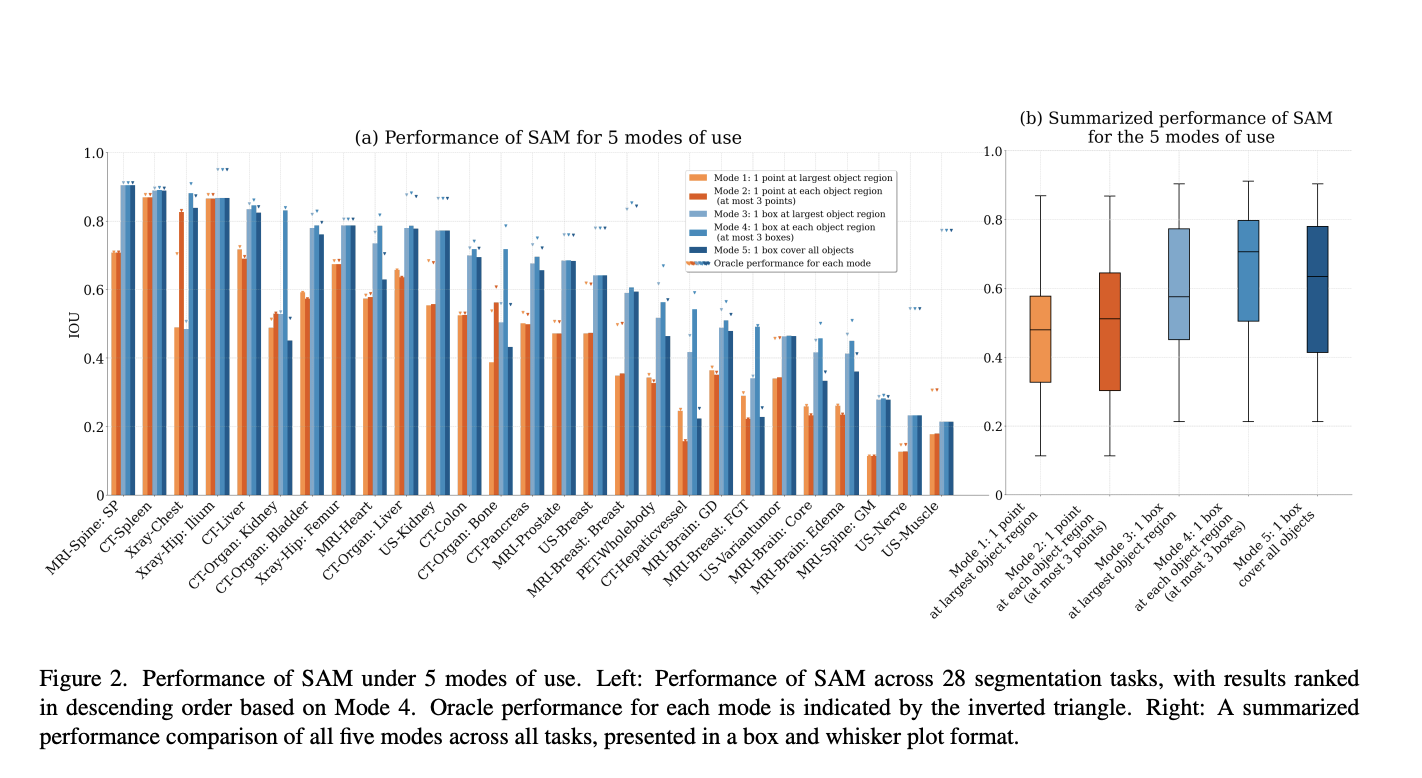
Image segmentation, which includes the segmentation of organs, abnormalities, bones, and other objects, is a key problem in medical image analysis. Deep learning has made considerable advances in this area. The expensive and time-consuming nature of gathering and curating medical images, particularly because trained radiologists must frequently provide meticulous mask annotations, makes it practically difficult to develop and train segmentation models for new medical imaging data and tasks. These issues might be considerably reduced with the introduction of foundation models and zero-shot learning.
The natural language processing field has benefited from foundation models’ paradigm-shifting capacities. To perform zero-shot learning on brand-new data in various contexts, foundation models are neural networks trained on a large amount of data with inventive knowledge and prompting objectives that typically do not require traditional supervised training labels. The recently created Segment Anything Model is a foundation model which has demonstrated impressive zero-shot segmentation performance on several realistic picture datasets. Researchers from the Duke University put it to the test on a medical image dataset.
In response to user-provided instructions, the Segment Anything Model (SAM) is intended to segment an object of interest in an image. A single point, a group of points (including a whole mask), a bounding box, or text can all be used as prompts. Even when the prompt is unclear, the model is prompted to provide a suitable segmentation mask. The main notion behind this method is that the model can segment any object that is pointed out since it has learnt the concept of an object. As a result, there is a good chance that it will perform well under the zero-shot learning regime and be able to segment objects of kinds that it has never seen before. The SAM authors used a particular model architecture and a particularly big dataset in addition to the prompt-based formulation of the job, as explained in the following.
SAM was gradually trained while the collection of pictures and accompanying object masks (SA-1B) was being developed. Three processes went into the creation of the dataset. First, human annotators clicked on items in a series of photographs and manually refined masks produced by SAM, which had been trained on open datasets at the time. Second, to broaden the variety of objects, the annotators were requested to segment masks SAM had yet to create confidently. The final set of masks was created automatically by picking confident and stable masks and providing the SAM model with a collection of points scattered in a grid over the image.
SAM is made to need one or more prompts to generate a segmentation mask. Technically, the model may be run without asking for any visible items, but they don’t anticipate this will be helpful for medical imaging because there are frequently many other things in the image in addition to the one of interest. SAM cannot be utilised in the same manner as most segmentation models in medical imaging, where the input is only an image and the output is a segmentation mask or multiple segmentation masks for the required item or objects. This is because SAM is prompt-based. They suggest that there are three key applications for SAM in the segmentation of medical pictures.
The first two entail training new models, creating masks, or annotating data using the Segment Anything Model itself. These methods don’t involve SAM adjustments. The final method is developing and honing a SAM-like model specifically for medical imagery. Then, each strategy is explained. Because SAM is still in the proof-of-concept phase with text-based prompting, please note that they make no comments here. “Human in the loop” semi-automated annotation. One of the major obstacles to creating segmentation models in this discipline is the human annotation of medical pictures, which often takes up doctors’ valuable time.
SAM might be utilized as a tool for quicker annotation in this situation. There are several methods for doing this. In the most basic scenario, a human user prompts SAM, which creates a mask that the user may accept or modify. This might be improved repeatedly. The “segment everything” mode is another option, where SAM receives instructions spaced evenly over the image and creates masks for several things that the user may subsequently name, pick, and/or modify. There are many more options after this; this is only the beginning.
Check out the Paper. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.