When SAM Meets NeRF: This AI Model Can Segment Anything in 3D
We are all amazed by the generative AI advancements recently, but that does not mean we do not get any significant breakthroughs in other applications. For example, the computer vision domain has been seeing relatively rapid advancements recently as well. The Segment Anything Model (SAM) release by Meta was a huge success and changed the game in 2D image segmentation entirely.
In image segmentation, the goal is to detect and sort of “paint” all the objects in the scene. Usually, this is done by training a model on a dataset of objects we want to segmentize. Then, we can use the model to segment the very objects in different images. However, the main problem here is that the model is bounded by the objects we show it during the training; and it cannot segmentize unseen objects.
With SAM, this is changed. SAM is the first model that could segmentize anything, literally. This is achieved by training the SAM on large-scale data and giving it the ability to perform zero-shot segmentation across various styles of image data. It is designed to automatically segment objects of interest in images, regardless of their shape, size, or appearance. SAM has demonstrated remarkable performance in segmenting objects in 2D images, revolutionizing the field of computer vision.
Of course, people did not simply stop there. They started working on ways to extend SAM’s capabilities beyond 2D. However, a key question has remained unanswered: Can SAM’s segmentation ability be extended to 3D, thereby bridging the gap between 2D and 3D perception caused by data scarcity? The answer is looking like yes, and it is time to meet with SA3D.
SA3D leverages advancements in Neural Radiance Fields (NeRF) and the SAM model to revolutionize 3D segmentation. NeRF has emerged as one of the most popular 3D representations in recent years. NeRF builds connections between sparse 2D images and real 3D points through differentiable volume rendering. It has seen numerous improvements, making it a powerful tool for tackling the challenges of 3D perception.
There have been some attempts to extend NeRF-based techniques for 3D segmentation. These approaches involved training an additional feature field aligned with a pre-trained 2D visual backbone. While effective, these methods suffer from limitations such as high memory footprint, artifacts in radiance fields affecting feature fields, and inefficiency due to the need for training an additional feature field for every scene.
This is where SA3D comes into play. Unlike previous methods, SA3D does not require training an additional feature field. Instead, it leverages the power of SAM and NeRF to segment desired objects from all views automatically.
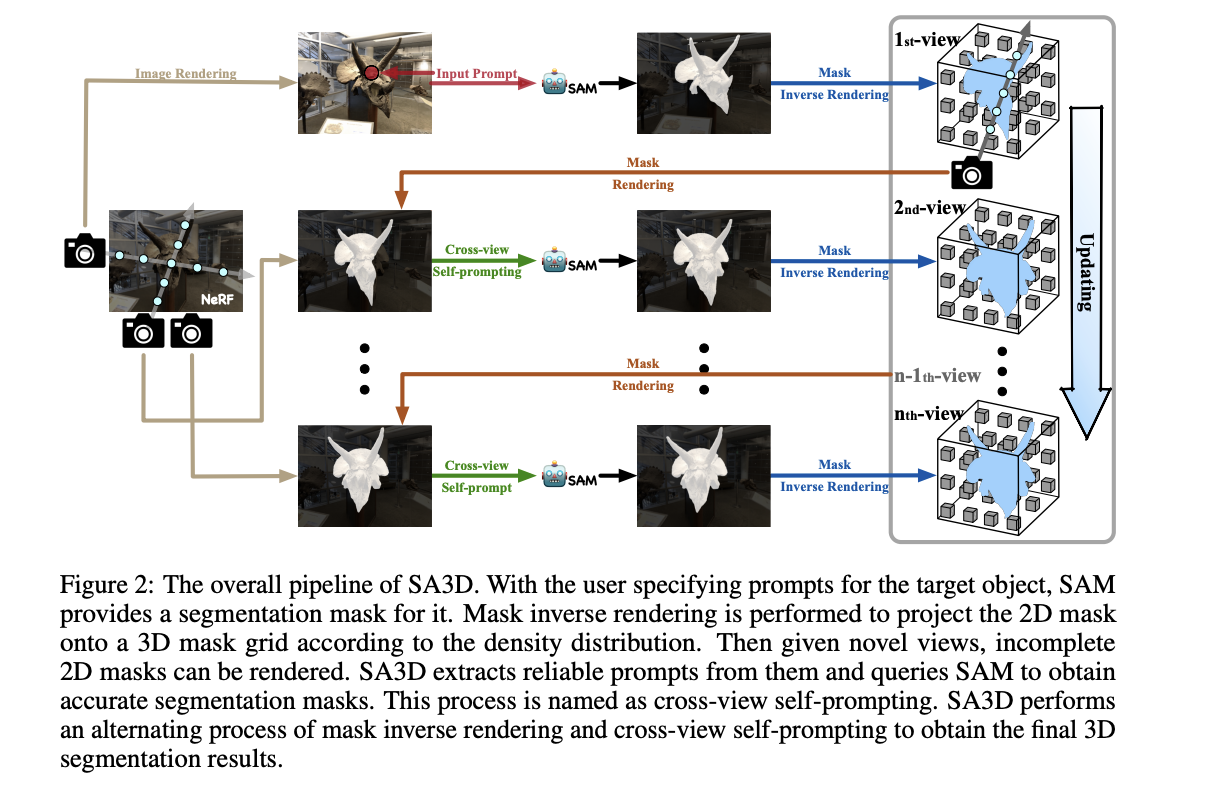
SA3D works by taking user-specified prompts from a single rendered view to initiate the segmentation process. The segmentation maps generated by SAM are then projected onto 3D mask grids using density-guided inverse rendering, providing initial 3D segmentation results. To refine the segmentation, incomplete 2D masks from other views are rendered and used as cross-view self-prompts. These masks are fed into SAM to generate refined masks, which are then projected onto the 3D mask grids. This iterative process allows for the generation of complete 3D segmentation results.

Overview of how SA3D works. Source: https://arxiv.org/abs/2304.12308
SA3D offers several advantages over previous approaches. It can easily adapt to any pre-trained NeRF model without the need for changes or re-training, making it highly compatible and adaptable. The entire segmentation process with SA3D is efficient, taking approximately two minutes without requiring engineering optimization. This speed makes SA3D a practical solution for real-world applications. Moreover, experimental results have demonstrated that SA3D can generate fine-grained segmentation results for various types of 3D objects, opening up new possibilities for applications such as robotics, augmented reality, and virtual reality.
Check out the Paper, Project, and Github link. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018 and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He is currently pursuing a Ph.D. degree at the University of Klagenfurt, Austria, and working as a researcher on the ATHENA project. His research interests include deep learning, computer vision, and multimedia networking.
Credit: Source link
Comments are closed.