CMU Researchers Propose STF (Sketching the Future): A New AI Approach that Combines Zero-Shot Text-to-Video Generation with ControlNet to Improve the Output of these Models
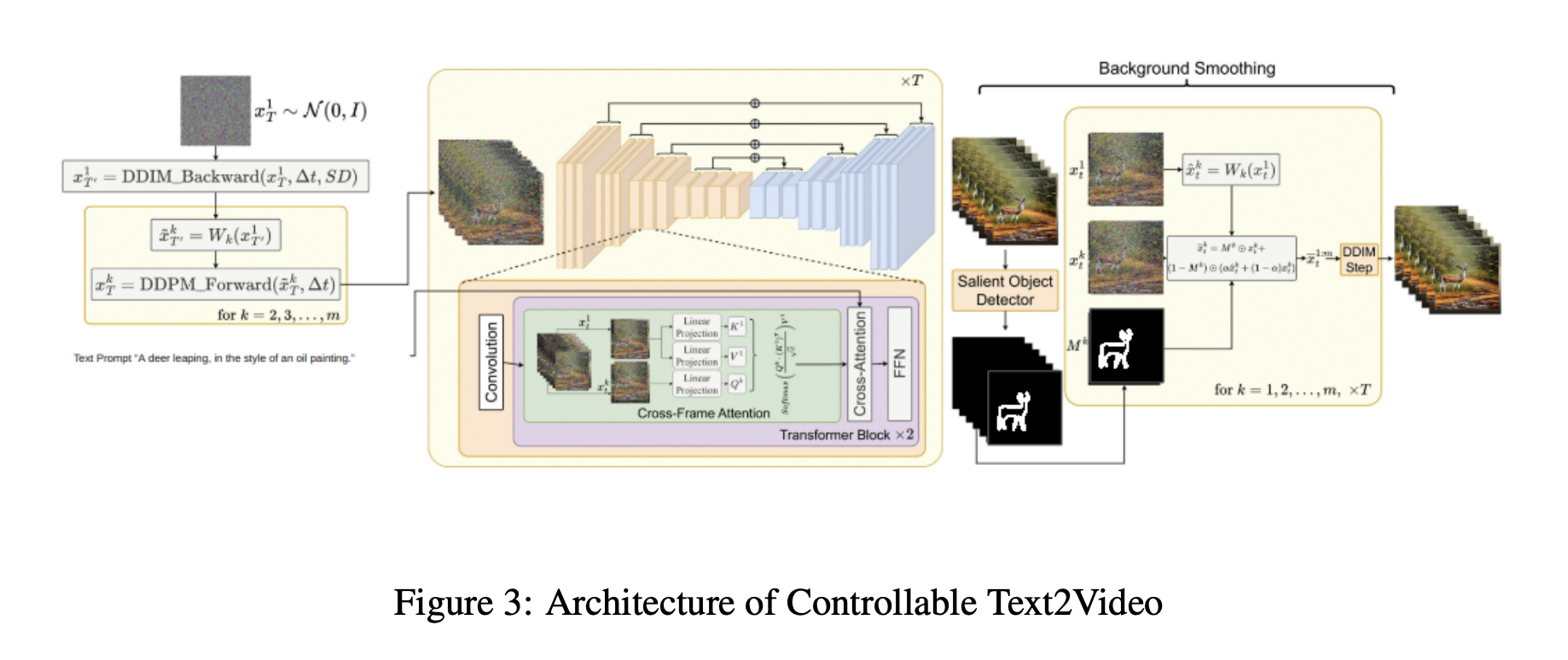
The popularity of neural network-based methods for creating new video material has increased due to the internet’s explosive rise in video content. However, the need for publicly available datasets with labeled video data makes it difficult to train Text-to-Video models. Furthermore, the nature of prompts makes it challenging to produce video using existing Text-to-Video models. They offer an innovative solution to these problems that combines the advantages of zero-shot text-to-video production with ControlNet’s strong control. Their approach is based on the Text-to-Video Zero architecture, which uses Stable Diffusion and other text-to-image synthesis techniques to generate videos at a minimal cost.
The main changes they make are the addition of motion dynamics to the produced frames’ latent codes and the reprogramming of frame-level self-attention using a brand-new cross-frame attention mechanism. These adjustments guarantee the uniformity of the foreground object’s identity, context, and appearance over the whole scene and backdrop. They include the ControlNet framework to improve control over the created video material. Edge maps, segmentation maps, and key points are just a few of the different input conditions that ControlNet may accept. It can also be trained end-to-end on a small dataset.
Textto-Video Zero and ControlNet produce a powerful and adaptable framework for building and managing video content while consuming the least resources. Their approach has video output that follows the flow of multiple drawn frames as input and multiple sketched frames as output. Before running Text-to-Video Zero, they interpolate frames between the entered drawings and use the resulting video of interpolated frames as the control method. Their method may be used for various tasks, including conditional and content-specific video production and Video Instruct-Pix2Pix, instruction-guided video editing, and text-to-video synthesis. Despite needing to be trained on additional video data, experiments demonstrate that their technology can produce high-quality and amazingly consistent video output with little overhead.
Researchers from Carnegie Mellon University offer a strong and adaptable framework for creating and managing video content while utilizing the least amount of resources by combining the benefits of Textto-Video Zero and ControlNet. This work creates new opportunities for effective and efficient video creation that can serve a variety of application fields. A wide range of businesses and applications will be significantly impacted by the development of STF (Sketching the Future). STF has the potential to dramatically alter how they produce and consume video content as a revolutionary method that blends zero-shot text-to-video production with ControlNet.
STF has both positive and Negative impacts. It can be useful for creative professionals in film, animation, and graphic design. Their method can speed up the creative process and lower the time and effort needed to produce high-quality video content by enabling the development of video content from drawn frames and written instructions. It might be advantageous to have personalized video material fast and effectively for advertising and marketing initiatives. STF can assist businesses in developing interesting and focused promotional materials that will help them connect with and better reach their target customers. STF may be used to create educational resources that match training needs or learning objectives. Their method can lead to more efficient and interesting educational experiences by producing video material that aligns with the targeted learning results. Accessibility: STF can increase the accessibility of video material for people with impairments. Their method can assist in developing video material that has subtitles or other visual aids, making information and entertainment more inclusive and reachable to a wider audience.
There are concerns about the possibility of misinformation and deep fake videos due to the capability to produce realistic video content using text prompts and sketched frames. Malicious actors may use STF to create convincing but fake video material that can be used to convey misinformation or sway public opinion. It’s possible that using STF for monitoring or surveillance purposes would violate people’s privacy. Their method may pose moral and legal issues about permission and data protection is used to create video material that features recognizable persons or locations. Displacement of jobs: Some specialists may lose jobs if STF is widely used in sectors that rely on the manual generation of video material. Their method can speed up the production of videos, but it can also decrease the demand for specific jobs in the creative sectors, including animators and video editors. They offer a complete resource bundle that includes a demo film, project website, open-source GitHub repository, and a Colab playground to encourage more study and use of the suggested strategy.
Check out the Paper, Project, and Github link. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.