Meet ONE-PEACE: A General Representation Model Towards Unlimited Modalities Across Different Modalities
Representation models have gotten much attention in computer vision, voice, natural language processing, etc. Representation models exhibit high generalization in various downstream tasks after learning from vast data. Furthermore, there is a growing demand for representation models due to the spectacular rise of large-scale language models (LLMs). Representation models have recently demonstrated their fundamental importance in enabling LLMs to comprehend, experience, and engage with other modalities (like vision). Previous research has mostly focused on developing uni-modal representation models with unique topologies and pretraining tasks due to the various properties of various modalities.
Recent efforts in vision-language and audio-language learning have shown promising results thanks to the development of unified architectures and effective pretraining activities. However, research on creating universal models that can be used for language, audio, and visual modalities still needs to be made available. Despite producing outstanding results, unimodal representation models need help using multi-modal data, such as image-text and audio-text pairings, efficiently, making applying them to multi-modal tasks difficult. Use a single masked prediction task with the Multiway Transformer to analyze text and picture modalities for pretraining.
The scalability to other modalities, such as audio, is constrained since the masked prediction job necessitates the pretrained CLIP model to discretize picture input. It offers a broad pretraining approach that can be used for language, audio, and visual modalities without external models (like CLIP). Still, it needs to expand the approach to multi-modal data. In this study, they investigate a scalable method to develop a general representation model that can accommodate any number of modalities. They promote the following requirements for a broad representation model: 1. The model design must be adaptable enough to handle multi-modal interaction and multiple modalities. 2. Pretraining exercises should promote alignment across modalities and information extraction within each modality. 3. Pretraining exercises should be broad and uncomplicated so they may be used with various modalities.
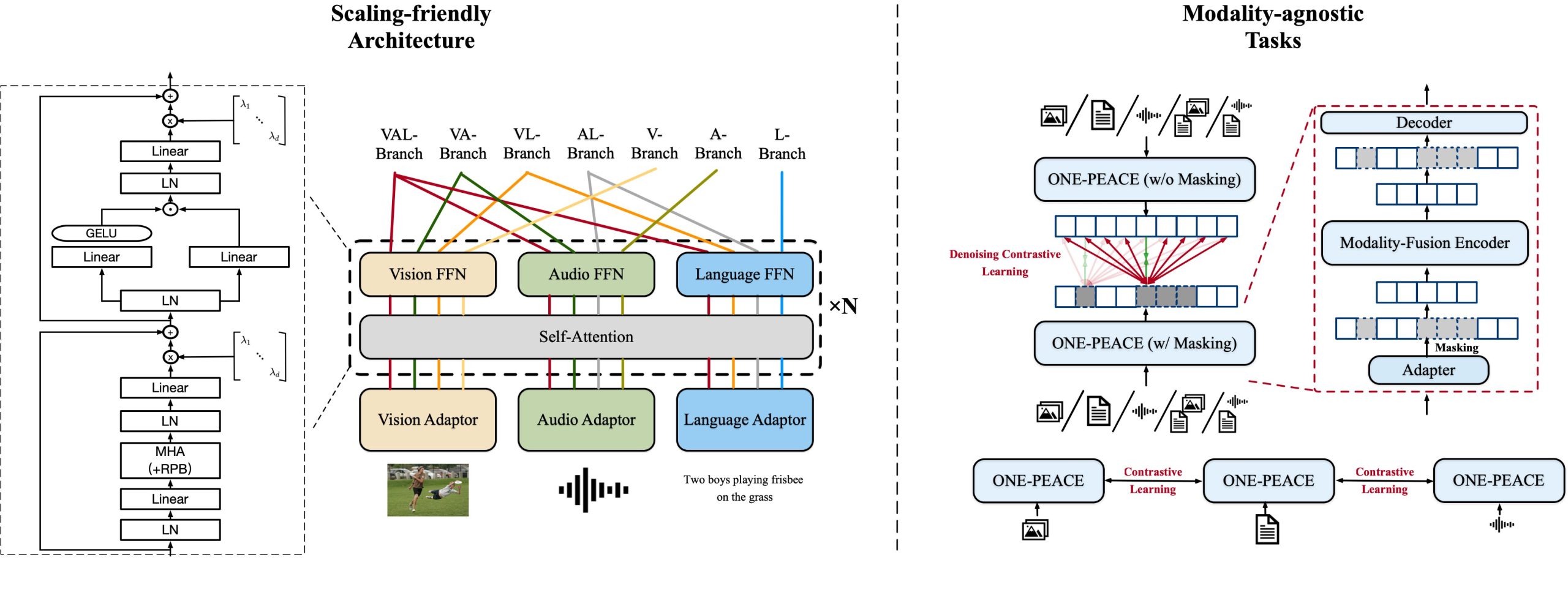
Due to these incentives, researchers from DAMO Academy and Huazhong University of Science and Technology suggest ONE-PEACE, a model with 4B parameters that can smoothly align and integrate representations across visual, audio, and language modalities. The architecture of ONE-PEACE comprises a modality fusion encoder and many modality adapters. Each modality includes an adaptor to transform the raw inputs into feature sequences. The modality fusion encoder uses the Transformer architecture-based feature sequences. A common self-attention layer and several modality Feed Forward Networks (FFNs) are present in each Transformer block. During the modality FFNs aid in information extraction within modalities. The self-attention layer uses the attention mechanism to enable interaction between the multi-modal features.
This architecture’s obvious division of labor makes adding new modalities simple and merely calls for adding adapters and FFNs. They provide two modality-independent pretraining assignments for ONE-PEACE. The first is cross-modal contrastive learning, which combines vision-language contrastive education and audio-language contrastive learning to successfully align the semantic spaces of the three modalities of vision, audio, and language. The second method is intra-modal denoising contrastive learning, which can be thought of as combining masked prediction and contrastive knowledge. Contrastive loss is performed between the fine-grained masked features and visible features, like image patches, language tokens, or audio waveform features.
ONE-PEACE can be expanded to infinite modalities thanks to the scaling-friendly model design and pretraining activities. Together, these activities improve the model’s performance during fine-tuning while preserving cross-modal retrieval capacity. They also eliminate the requirement for modality-specific plans because they are ubiquitous for all modalities. They carry out in-depth studies on various tasks in various modalities, such as vision, audio, vision-language, and audio-language activities. ONE PEACE achieves industry-leading results without using vision or language-pre-trained models for initialization in uni-modal and multi-modal tasks. The code is publicly available on GitHub.
Check out the Paper and Github. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.