Researchers from UCL and Google Propose AudioSlots: A Slot-Centric Generative Model For Audio Domain Blind Source Separation
The use of neural networks in architectures that operate on set-structured data and learn to map from unstructured inputs to set-structured output spaces has recently received much attention. Recent developments in object identification and unsupervised object discovery, especially in the vision domain, are supported by slot-centric or object-centric systems. These object-centric architectures are well suited for audio separation due to their inherent inductive bias of permutation equivariance. The goal of distinguishing audio sources from mixed audio signals without access to insider information about the sources or the mixing process is the focus of this paper’s application of the key concepts from these architectures.

Figure 1: Overview of the architecture: A spectrogram is created after chopping the input waveform. After that, the neural network encodes the spectrogram to a set of permutation-invariant source embeddings (s1…n), which are then decoded to produce a collection of distinct source spectrograms. A matching-based permutation invariant loss function oversees the whole pipeline using the ground truth source spectrograms.
Sound separation is a set-based problem since the sources’ ordering is random. A mapping from a mixed audio spectrogram to an unordered set of separate source spectrograms is learned, and the challenge of sound separation is framed as a permutation-invariant conditional generative modeling problem. With the use of their technique, AudioSlots, audio is divided into distinct latent variables for each source, which are then decoded to provide source-specific spectrograms. It is created using encoder and decoder functions based on the Transformer architecture. It is permutation-equivariant, making it independent of the ordering of the source latent variables (also known as “slots”). They train AudioSlots with a matching-based loss to produce independent sources from the mixed audio input to assess the potential of such an architecture.
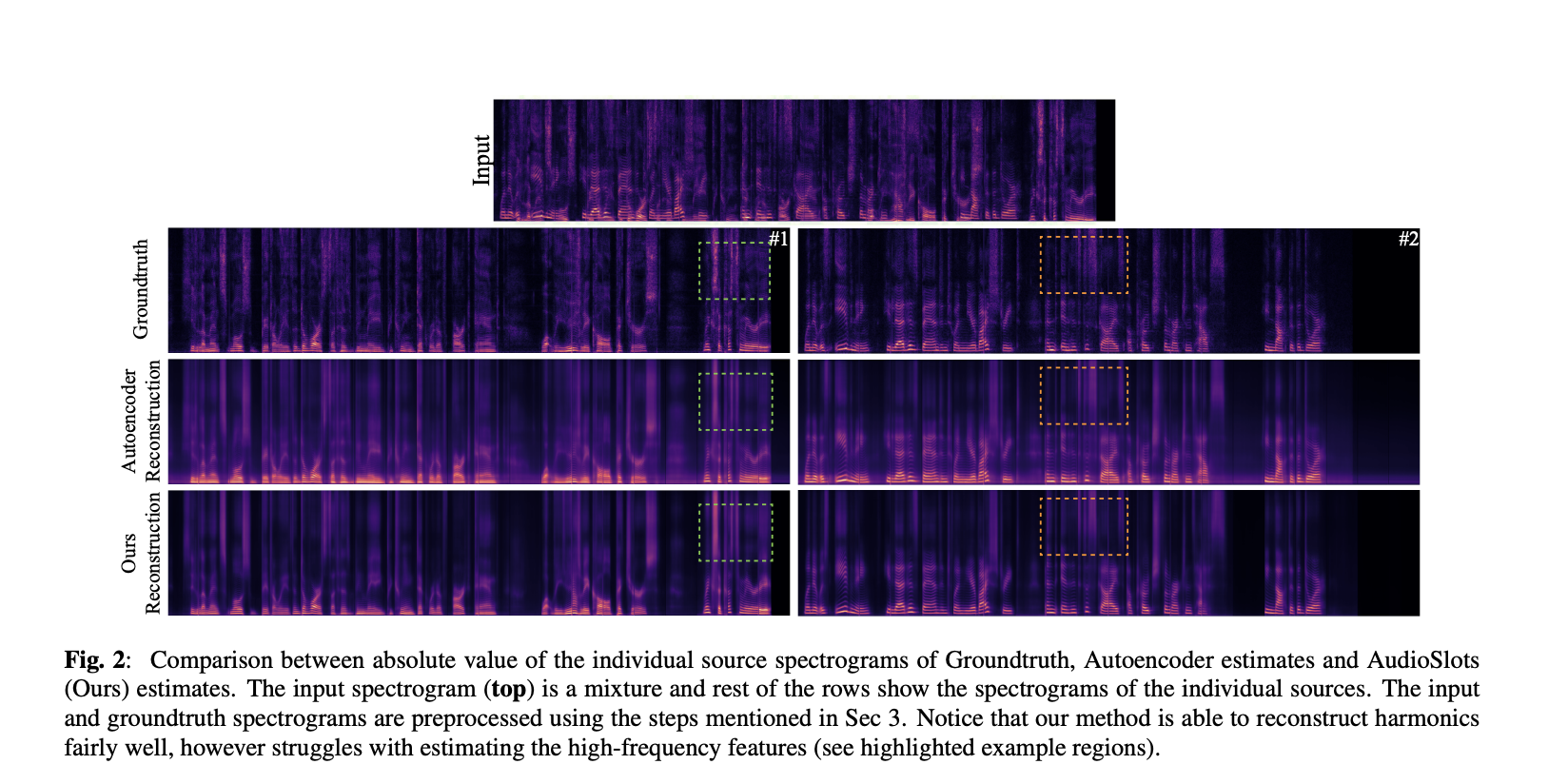
Researchers from the University College London and Google Research introduce AudioSlots, a generative architecture for slot-centric audio spectrograms. They provide evidence that AudioSlots offers the potential for employing structured generative models to tackle the problem of audio source separation. Although there are several drawbacks to their current implementation of AudioSlots, such as low reconstruction quality for high-frequency features and the need for separate audio sources as supervision, they are confident that these issues can be resolved and suggest several potential areas for further research.
They show their methodology in action on a straightforward two-speaker voice separation assignment from Libri2Mix. They discover that sound separation with slot-centric generative models shows promise but comes with some difficulties: the version of their model that is presented struggles to generate high-frequency details relies on heuristics to stitch independently predicted audio chunks together, and still needs ground-truth reference audio sources for training. In their future work, which they provide potential routes for in their study, they are optimistic that these difficulties may be addressed. Nevertheless, their results primarily serve as a proof of concept for this idea.
Check out the Paper. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.