New Google AI Report Shows Data Improvements And Scaling Insights That Have Enabled Its New Palm2 Large Language Model
For a long time, the next-word prediction was the go-to method for estimating the linguistic information present, making language modeling a vital study area. Over the past few years, large language models (LLMs) have demonstrated impressive performance in reasoning, math, science, and language problems thanks to greater scale and the Transformer architecture. Expanding the model size and data quantity has played critical roles in these breakthroughs. Most LLMs still stick to a tried-and-true formula, including primarily monolingual corpora and a language modeling goal.
Recent Google research presents PaLM 2, an updated version of the PaLM language model that incorporates new modeling, data, and scaling developments. PaLM 2 integrates a wide variety of new findings from several fields of study, including:
- Rationalization by computation: Data size has recently been shown to be at least as relevant as model size through compute-optimal scaling. This study debunks the conventional wisdom that it’s better to scale the model three times as quickly as the dataset if users want optimal performance for their training computation.
- The blending of data sets improved: Most of the text in previous large pre-trained language models was in English. With hundreds of languages and domains in mind (such as programming, mathematics, and parallel multilingual texts), the team has developed a more multilingual and diverse pretraining mixture. The findings demonstrate that more complex models can effectively deal with more diverse non-English datasets and employ deduplication to decrease memory without negatively impacting English language understanding ability.
- In the past, LLMs have typically relied on either a single causal or concealed goal. The proposed model architecture is based on the Transformer, which has been shown to improve both architecture and objective metrics. The researchers used a carefully balanced combination of pretraining objectives to train this model to comprehend a wide range of linguistic facets.
The findings reveal that PaLM 2 models perform much better than PaLM on a wide range of tasks, such as generating natural language, translating it, and reasoning. Even though it requires more training compute than the largest PaLM model, the PaLM 2-L model, the largest in the PaLM 2 family, is much smaller. These findings point to alternatives to model scaling for enhancing performance, such as carefully selecting the data and having efficient architecture/objectives that can unlock performance. Having a smaller model that is nevertheless high quality improves inference efficiency, decreases serving costs, and opens the door for the model to be used in more downstream applications and by more users.
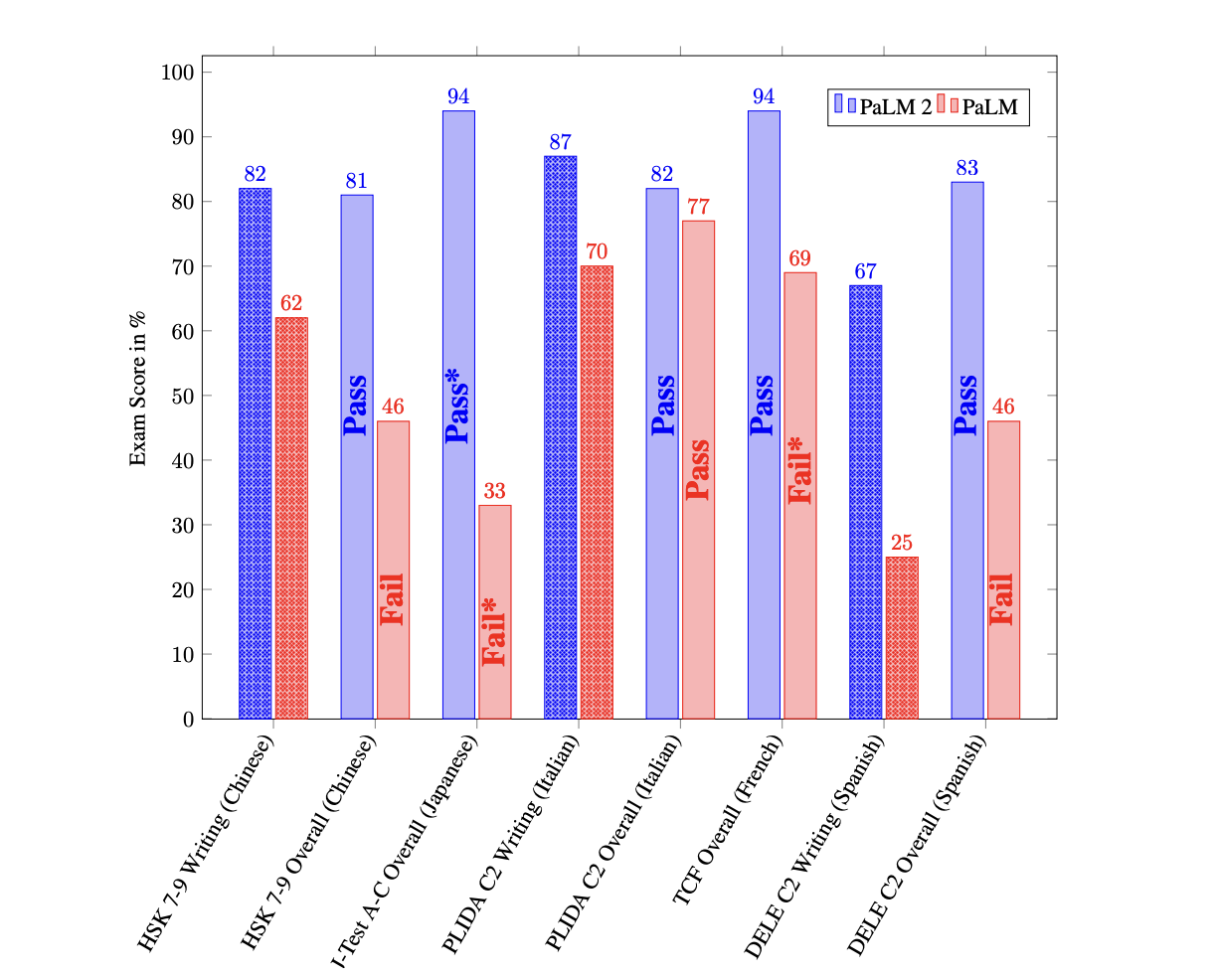
The language, code production, and reasoning abilities of PaLM 2 across languages are impressive. It outperforms its predecessor on advanced language proficiency tests in the wild by a wide margin.
By altering only a subset of pretraining, PaLM 2 allows inference-time control over toxicity through control tokens. PaLM 2’s pretraining data were augmented with novel ‘canary’ token sequences to facilitate better cross-lingual memory evaluations. After comparing PaLM and PaLM 2, the researchers found that the latter has lower average rates of verbatim memorization. For tail languages, memorizing rates only increase above English when data is repeated numerous times throughout texts. The group demonstrates that PaLM 2 has enhanced multilingual toxicity classification capabilities and assesses the risks and biases associated with several potential applications.
The team believes that changes to the architecture and objective, as well as additional scaling of model parameters and dataset size and quality, can continue to generate advancements in language interpretation and generation.
Check out the Paper. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.