Meet NerfDiff: An AI Framework To Enable High-Quality and Consistent Multiple Views Synthesis From a Single Image
The synthesis of new views is a hot topic in computer graphics and vision applications, such as virtual and augmented reality, immersive photography, and the development of digital replicas. The objective is to generate additional views of an object or a scene based on limited initial viewpoints. This task is particularly demanding because the newly synthesized views must consider occluded areas and previously unseen regions.
Recently, neural radiance fields (NeRF) have demonstrated exceptional results in generating high-quality novel views. However, NeRF relies on a significant number of images, ranging from tens to hundreds, to effectively capture the scene, making it susceptible to overfitting and lacking the ability to generalize to new scenes.
Previous attempts have introduced generalizable NeRF models that condition the NeRF representation based on the projection of 3D points and extracted image features. These approaches yield satisfactory results, particularly for views close to the input image. However, when the target views significantly differ from the input, these methods produce blurry outcomes. The challenge lies in resolving the uncertainty associated with large unseen regions in the novel views.
An alternative approach to tackle the uncertainty problem in single-image view synthesis involves utilizing 2D generative models that predict novel views while conditioning on the input view. However, the risk for these methods is the lack of consistency in image generation with the underlying 3D structure.
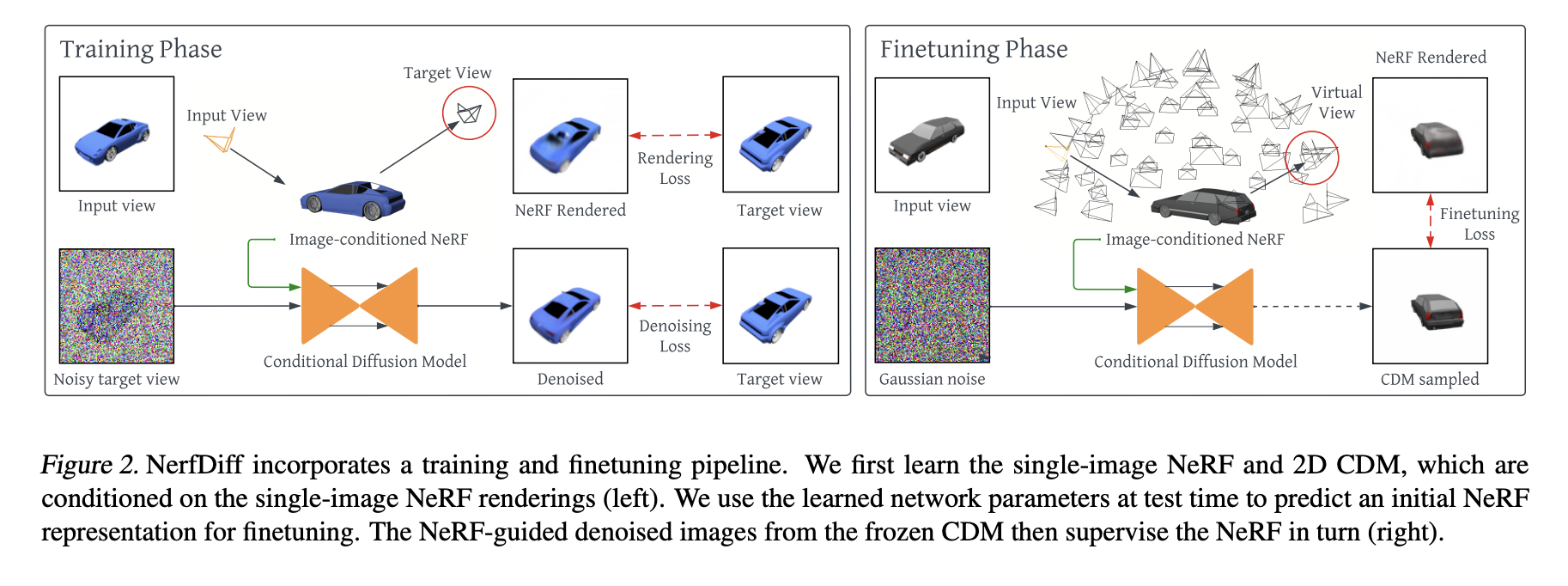
For this purpose, a new technique called NerfDiff has been presented. NerfDiff is a framework designed for synthesizing high-quality multi-view consistent images based on single-view input. An overview of the workflow is presented in the figure below.

The proposed approach consists of two stages: training and finetuning.
During the training stage, a camera-space triplane-based NeRF model and a 3D-aware conditional diffusion model (CDM) are jointly trained on a collection of scenes. The NeRF representation is initialized using the input image at the finetuning stage. Then, the parameters of the NeRF model are adjusted based on a set of virtual images generated by the CDM, which is conditioned on the NeRF-rendered outputs. However, a straightforward finetuning strategy that optimizes the NeRF parameters directly using the CDM outputs produces low-quality renderings due to the multi-view inconsistency of the CDM outputs. To address this issue, the researchers propose NeRF-guided distillation, an alternating process that updates the NeRF representation and guides the multi-view diffusion process. Specifically, this approach allows the resolution of uncertainty in single-image view synthesis by leveraging the additional information provided by the CDM. Simultaneously, the NeRF model guides the CDM to ensure multi-view consistency during the diffusion process.
Some of the results obtained through NerfDiff are reported here below (where NGD stands for Nerf-Guided Distillation).

This was the summary of NerfDiff, a novel AI framework to enable high-quality and consistent multiple views from a single input image. If you are interested, you can learn more about this technique in the links below.
Check out the Paper and Project. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.