ULIP and ULIP-2: Envisioning a Future Where Machines Perceive 3D Objects as Humans Do – A Quantum Leap in Three-Dimensional Comprehension
Think about a future where machines have the same level of 3D object comprehension as humans. By radically improving 3D comprehension, the ULIP and ULIP-2 initiatives, funded by Salesforce AI, are making this a reality. Aligning 3D point clouds, pictures, and texts into a single representation space, ULIP pre-trains models like no other method can. Using this method, we may achieve state-of-the-art performance on 3D classification tasks and explore new avenues for image-to-3D retrieval and other cross-domain applications. Following the success of ULIP, ULIP-2 uses huge multimodal models to produce holistic language equivalents for 3D objects, allowing for scalable multimodal pre-training without the need for manual annotations. With the help of these innovative projects, we are getting closer to a time when artificial intelligence can fully comprehend our physical reality.
Critical to the development of AI, research in three-dimensional cognition focuses on teaching computers to think and behave in space the way humans do. Numerous technologies, from driverless vehicles and robotics to augmented and virtual realities, rely on this skill heavily.
3D comprehension was difficult for a long time due to the high difficulty associated with processing and comprehending 3D input. These difficulties are amplified by the high price tag attached to gathering and annotating 3D data. The complexity of real-world 3D data, such as noise and missing information, is often further compounded by the data itself. Opportunities in 3D comprehension have expanded thanks to recent AI and machine learning developments. Multimodal learning, in which models are trained using data from various sensory modalities, is a promising new development. By taking into account not just the geometry of 3D objects but also how they are depicted in photos and described in the text, this method can assist models in capturing a complete knowledge of the things in question.
Salesforce AI’s ULIP and ULIP-2 programs are in the vanguard of these developments. With their cutting-edge approaches to 3D-environment comprehension, these projects are revolutionizing the field. Scalable improvements in 3D comprehension are made possible by the ULIP and ULIP-2’s use of cutting-edge, practical methodologies that tap into the potential of multimodal learning.
ULIP
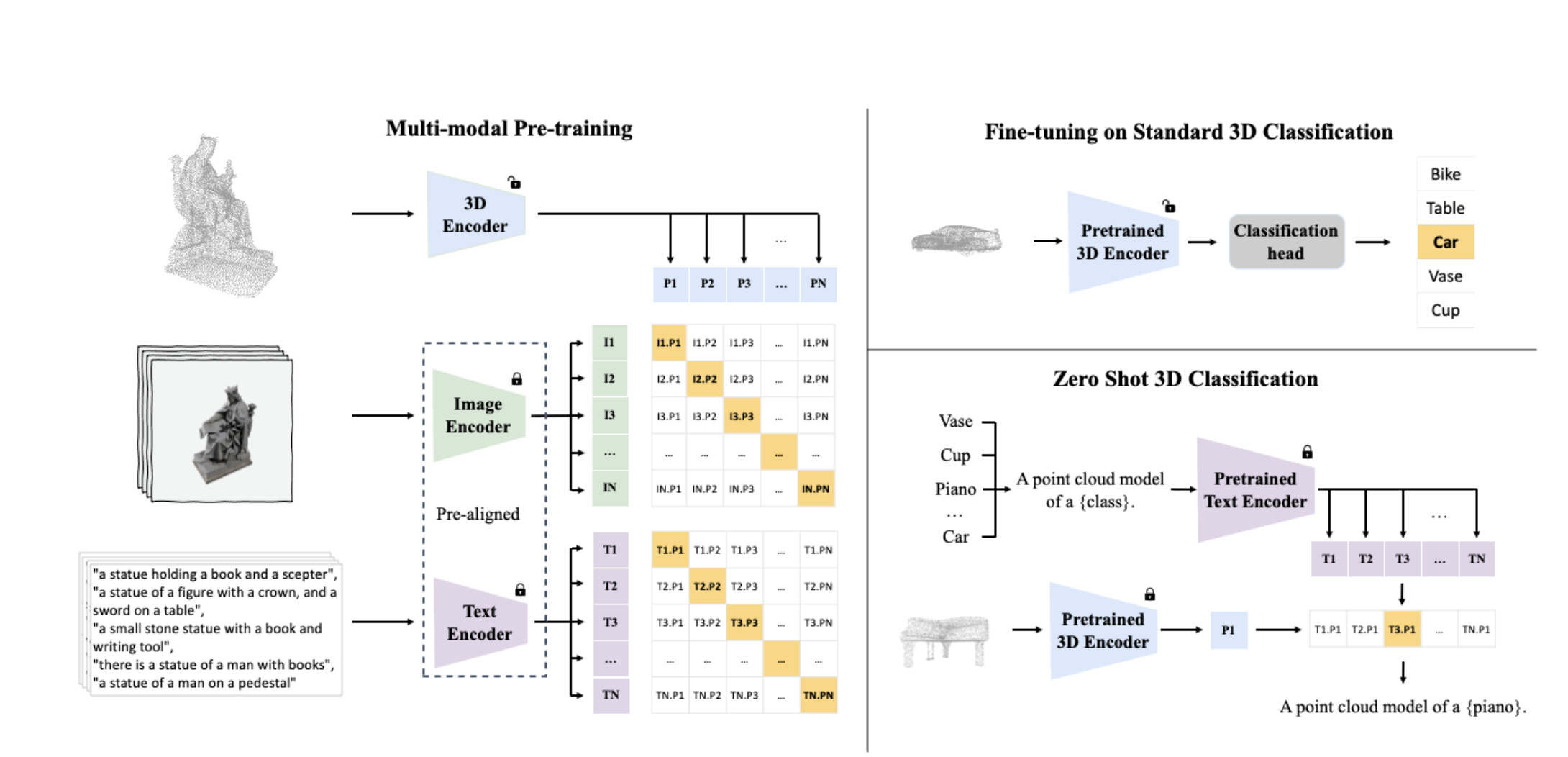
The ULIP takes a novel method by first training models on sets of three data types: photos, textual descriptions, and 3D point clouds. In a sense, this technique is analogous to instructing a machine to comprehend a 3D object by providing it with information on the thing’s appearance (picture), function (text description), and structure (3D point cloud).
ULIP’s success can be attributed to using the pre-aligned image and text encoders like CLIP, which has already been pre-trained on many picture-text pairs. Using these encoders, the model can better comprehend and categorize 3D objects, as the characteristics from each modality are aligned in a single representation space. In addition to enhancing the model’s knowledge of 3D input, the 3D encoder gets multimodal context through better 3D representation learning, allowing for cross-modal applications such as zero-shot categorization and picture-to-3D retrieval.
ULIP : Key features
- Any 3D design can benefit from ULIP because it is backbone network agnostic.
- Our framework, ULIP, pre-trains numerous recent 3D backbones on ShapeNet55, allowing them to achieve state-of-the-art performance on ModelNet40 and ScanObjectNN in traditional 3D classification and zero-shot 3D classification.
- On ScanObjectNN, ULIP increases PointMLP’s performance by about 3%, and on ModelNet40, ULIP achieves a 28.8% improvement in top-1 accuracy for zero-shot 3D classification compared to PointCLIP.
ULIP-2
ULIP-2 improves upon its predecessor by using the computational might of today’s massive multimodal models. Scalability and the absence of manual annotations contribute to this approach’s effectiveness and versatility.
The ULIP-2 method generates comprehensive natural language descriptions of each 3D object for the model’s training process. To fully realize the benefits of multimodal pre-training, this system allows for generating large-scale tri-modal datasets without manual annotations.
In addition, we share the resulting tri-modal datasets, dubbed “ULIP-Objaverse Triplets” and “ULIP-ShapeNet Triplets,” respectively.
ULIP-2 : Key Features
- ULIP-2 significantly enhances upstream zero-shot categorization on ModelNet40 (74.0% in top-1 accuracy).
- This method is scalable to huge datasets because it does not require 3D annotations. By achieving an overall accuracy of 91.5% with only 1.4 million parameters on the real-world ScanObjectNN benchmark, this method represents a major step forward in scalable multimodal 3D representation learning without human 3D annotations.
Salesforce AI’s support of the ULIP project and the subsequent ULIP-2 is driving revolutionary changes in the 3D understanding industry. To improve 3D classification and open the door to cross-modal applications, ULIP brings together previously disparate modalities into a single framework. When constructing big tri-modal datasets without manual annotations, ULIP-2 goes above and beyond. These endeavors are breaking new ground in 3D comprehension, opening the door to a future where machines can fully comprehend the world around us in three dimensions.
Check out the SF Blog, Paper-ULIP, and Paper-ULIP2. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.