Meet QLORA: An Efficient Finetuning Approach That Reduces Memory Usage Enough To Finetune A 65B Parameter Model On A Single 48GB GPU While Preserving Full 16-Bit FineTuning Task Performance
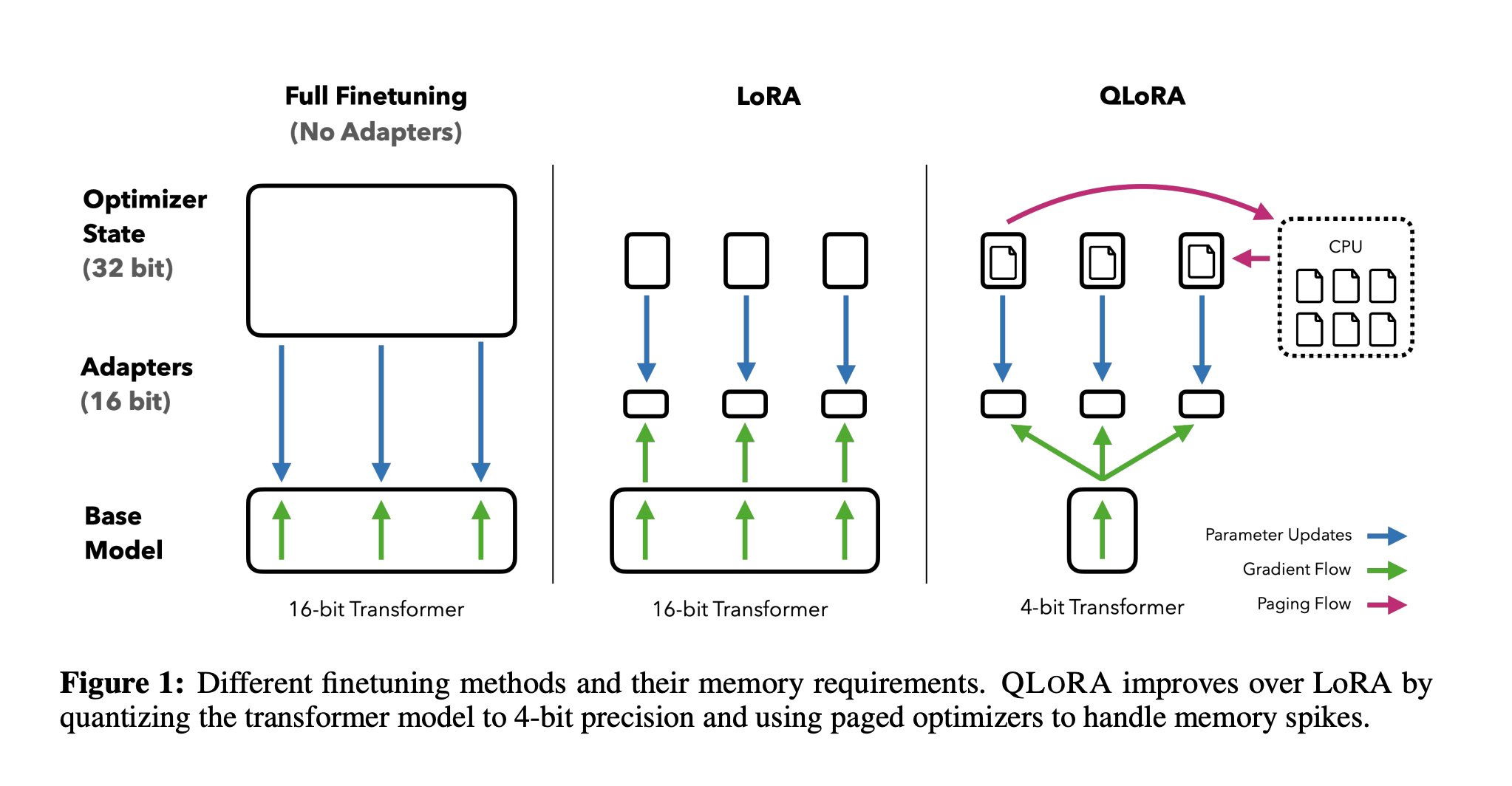
Large language models (LLMs) may be improved via finetuning, which also allows for adding or removing desired behaviors. However, finetuning big models is prohibitively costly; for example, a LLaMA 65B parameter model consumes more than 780 GB of GPU RAM when finetuning it in standard 16-bit mode. Although more current quantization approaches can lessen the memory footprint of LLMs, these methods only function for inference and fail during training. Researchers from the University of Washington developed QLORA, which quantizes a pretrained model using a cutting-edge, high-precision algorithm to a 4-bit resolution before adding a sparse set of learnable Low-rank Adapter weights modified by backpropagating gradients through the quantized consequences. They show for the first time that a quantized 4-bit model may be adjusted without affecting performance.
Compared to a 16-bit fully finetuned baseline, QLORA reduces the average memory needs of finetuning a 65B parameter model from >780GB of GPU RAM to 48GB without sacrificing runtime or predictive performance. The largest publicly accessible models to date are now fine-tunable on a single GPU, representing a huge change in the accessibility of LLM finetuning. They train the Guanaco family of models using QLORA, and their largest model achieves 99.3% using a single professional GPU over 24 hours, effectively closing the gap to ChatGPT on the Vicuna benchmark. The second-best model reaches 97.8% of ChatGPT’s performance level on the Vicuna benchmark while being trainable in less than 12 hours on a single consumer GPU.
The following technologies from QLORA are intended to lower memory use without compromising performance: (1) 4-bit NormalFloat, a quantization data type for normally distributed data that is information-theoretically optimum and produces superior empirical outcomes than 4-bit Integers and 4-bit Floats. (2) Double Quantization, which saves, on average, 0.37 bits per parameter (or around 3 GB for a 65B model), quantizes the quantization constants. (3) Paged Optimizers use NVIDIA unified memory to prevent memory spikes caused by gradient checkpointing when processing a mini-batch with a lengthy sequence. When used, their smallest Guanaco model (7B parameters) uses under 5 GB of memory while outperforming a 26 GB Alpaca model on the Vicuna test by more than 20 percentage points.
They incorporate these contributions into a more refined LoRA strategy that includes adapters at every network tier and, therefore, almost eliminates the accuracy trade-offs identified in earlier work. Due to QLORA’s efficiency, we can analyze instruction finetuning and chatbot performance on model sizes in greater detail than we could have done with conventional finetuning owing to memory cost. As a result, they train over a thousand models using a variety of instruction-tuning datasets, model topologies, and parameter values ranging from 80M to 65B. They demonstrate that QLORA restores 16-bit performance, trains Guanaco, an advanced chatbot, and examines patterns in the learned models.
First, even though both are intended to provide instruction after generalization, they discover that data quality is considerably more essential than dataset size, with a 9k sample dataset (OASST1) outperforming a 450k sample dataset (FLAN v2, subsampled) on chatbot performance. Second, they demonstrate that good Massive Multitask Language Understanding (MMLU) benchmark performance only sometimes translates into great Vicuna chatbot benchmark performance, and vice versa. In other words, dataset appropriateness is more important than scale for a given task. They also offer a thorough evaluation of chatbot performance using human raters and GPT-4.
Models compete against one another in matches using tournament-style benchmarking to determine the best response to a given stimulus. GPT-4 or human annotators decide which player wins a game. Elo scores, which are created by combining the tournament outcomes, are used to rank chatbot performance. On the rank of model performance in the tournaments, they discover that GPT-4 and human judgments mostly concur, but there are also some areas of stark divergence. As a result, they draw attention to the fact that model-based assessment has uncertainties while being a less expensive option than human annotation.
They add qualitative analysis of Guanaco models to their chatbot benchmark findings. Their study identifies instances of success and failure that the quantitative standards did not account for. They publish all model generations with GPT-4 and human comments to aid future research. They incorporate their techniques into the Hugging Face transformers stack, open-source their software and CUDA kernels, and make them widely available. For 32 distinct open-sourced, improved models, they provide a collection of adapters for models of sizes 7/13/33/65B trained on 8 different instruction following datasets. The code repository is made public, along with a demo that can be hosted on Colab.
Check out the Paper, Code, and Colab. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.