Hugging Face Introduces “T0”, An Encoder-Decoder Model That Consumes Textual Inputs And Produces Target Responses

Language models use various statistical and probabilistic techniques to predict the probability of a given sequence of words appearing in a phrase. For this, these models evaluate large amounts of text data.
Large language models have recently been proven to be capable of reasonable zero-shot generalization to new tasks. Despite just being trained on language modeling objectives, these models can perform reasonably well on new tasks for which they have not been explicitly trained, such as answering questions about passages or summarising.
According to studies, large language models generalize to new tasks as a result of an unconscious multitask learning process. A language model is forced to learn from various implicit tasks included in their pretraining corpus as a result of learning to anticipate the next word. This allows big language models to generalize to unknown tasks offered as natural language prompts, extending beyond the capabilities of most large-scale explicit multitask settings. However, this capability requires a sufficiently large model and is sensitive to the language of its cues.
In addition, how implicit this multitask learning remains an unanswered subject. Given the size of the training data, it’s fair to expect some typical natural language processing (NLP) tasks to appear in explicit form in the dataset, allowing the language model to be directly trained on the task. Given the size of large language models and the datasets on which they are trained, explicit multitask supervision could play a significant role in zero-shot generalization.
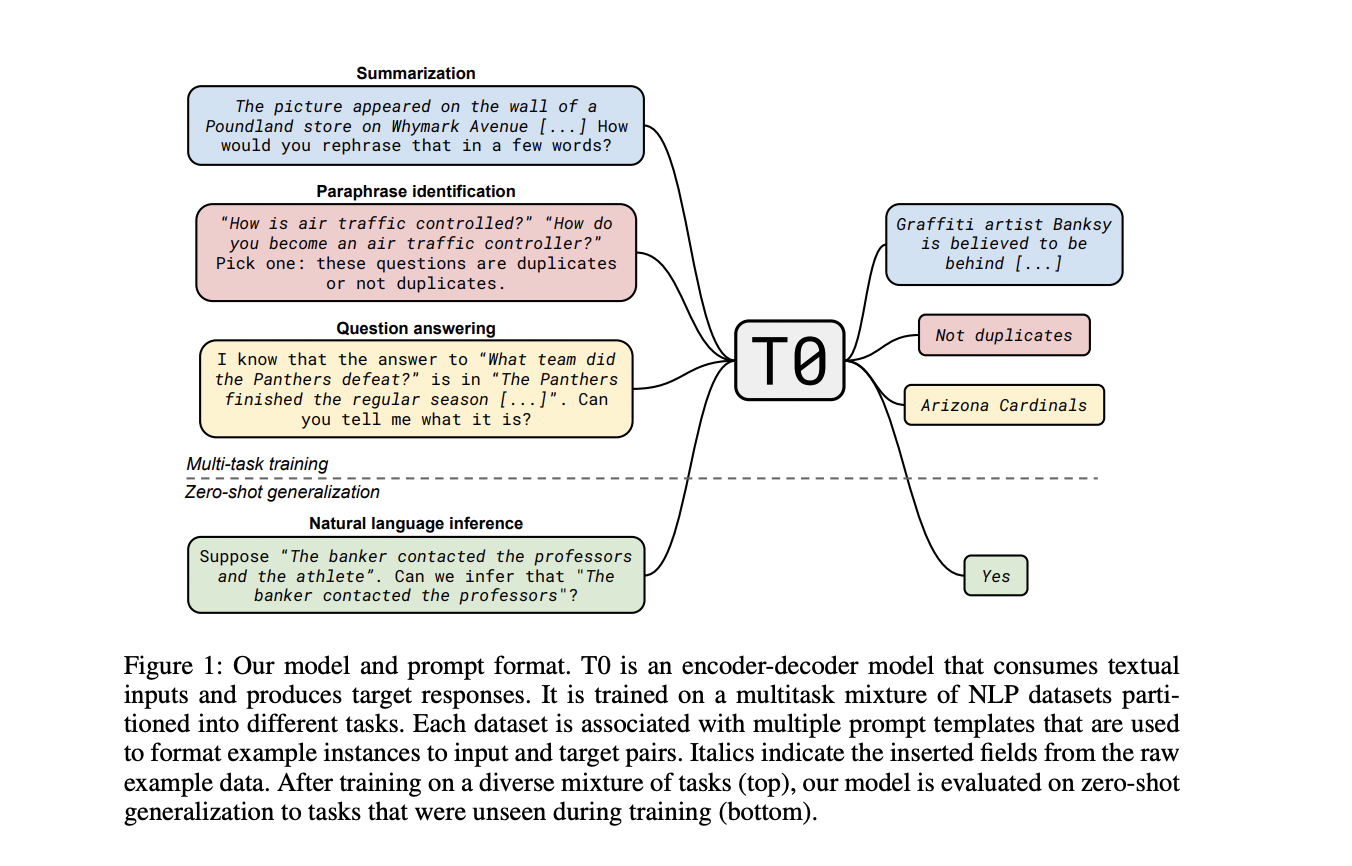
Researchers from Brown University and Hugging Face conducted a study that focused on consciously and explicitly training huge language models in a supervised and massively multitask manner. They employ a multitask training mix that consists of a large number of diverse activities that are specified via natural language prompts.
This research aimed to get a model that can generalize to new jobs without requiring vast size, as well as be more resistant to prompt phrasing choices.
They used a basic templating language for structured datasets to turn a large number of natural language jobs into suggested forms. To accomplish this, they created an interface for public contributors to collect prompts, making it easier to collect a huge multitask mixture with several questions per dataset. Then they train the T0 model, a variant of the T5 encoder-decoder model, on a subset of the tasks (each with multiple datasets). After training, they evaluate tasks on which the model has not been trained.
This research provides answers to two questions:
- Does multitask triggered training improve generalization to previously unknown tasks?
- Does training on a broader set of prompts increase prompt wording robustness?
The results demonstrate that the model meets or exceeds GPT-3 performance on 9 out of 11 held-out datasets, although being nearly 16 times smaller. When evaluating the model’s performance on BIG-benchmark 2, the model outperforms a big baseline language model on 13/14 comparable tasks. Overall, the findings show that multitask training enables zero-shot task generalization.

Furthermore, training on more prompts per dataset consistently increases the median and lowers the variability of held-out task performance. Training on prompts from a larger range of datasets improves the median but does not reduce variability.
This method is an excellent alternative to unsupervised language model pretraining, as it allows the T0 model to outperform models that are several times its size. The team hopes that their approach will enable researchers to improve zero-shot generalization in the future.
Paper: https://arxiv.org/pdf/2110.08207.pdf
GitHub: https://github.com/bigscience-workshop/promptsource/
Suggested
Credit: Source link
Comments are closed.