Meet Text2NeRF: An AI Framework that Turns Text Descriptions into 3D Scenes in a Variety of Art Different Styles
Due to the intuitiveness of using natural language prompts to specify desired 3D models, recent advances in text-to-image generation have also sparked a lot of interest in zero-shot text-to-3D generation. This could increase the productivity of the 3D modelling workflow and lower the entry barrier for beginners. The text-to-3D generation process is still difficult because, unlike the text-to-image scenario, where paired data is available, obtaining huge amounts of coupled text and 3D data is impracticable. To get around this data restriction, some ground-breaking works, like CLIP-Mesh, Dream Fields, DreamFusion, and Magic3D, optimize a 3D representation using deep priors of previously trained text-to-image models, like CLIP or image diffusion models. This enables text-to-3D generation without the need for labelled 3D data.
Despite these works’ enormous success, the only 3D sceneries they can generally have basic geometry and surrealistic aesthetics. These restrictions may be caused by the deep priors used to optimize the 3D representation generated from pre-trained picture models, which can only impose restrictions on high-level semantics while ignoring low-level features. SceneScape and Text2Room, two recently concurrent arrived efforts, on the other hand, use the color picture produced by the text-image diffusion model directly to influence the reconstruction of 3D scenes. Due to the explicit 3D mesh representation’s limitations, which include the stretched geometry brought on by naive triangulation and noisy depth estimation, these methods, while supporting the generation of realistic 3D scenes, primarily focus on indoor scenes and are difficult to extend into large-scale outdoor scenes. In contrast, their approach uses NeRF, a 3D representation more suited for modeling various scenarios with intricate geometry. In this study, researchers from the University of Hong Kong introduce Text2NeRF, a text-driven 3D scene synthesis system that combines the best features of a trained text-to-image diffusion model with the Neural Radiance Field (NeRF).
Due to NeRF’s superiority in modeling fine-grained and lifelike features in varied settings, which might greatly reduce the artifacts induced by a triangle mesh, they chose NeRF as the 3D representation. They use finer-grained image priors inferred from the diffusion model instead of the earlier techniques, like DreamFusion, which controlled the 3D generation with semantic priors. This enables Text2NeRF to produce more delicate geometric structures and realistic texture in 3D scenes. In addition, they restrict the NeRF optimization from scratch without the need for extra 3D supervision or multiview training data by using a pre-trained text-to-image diffusion model as the image-level prior.
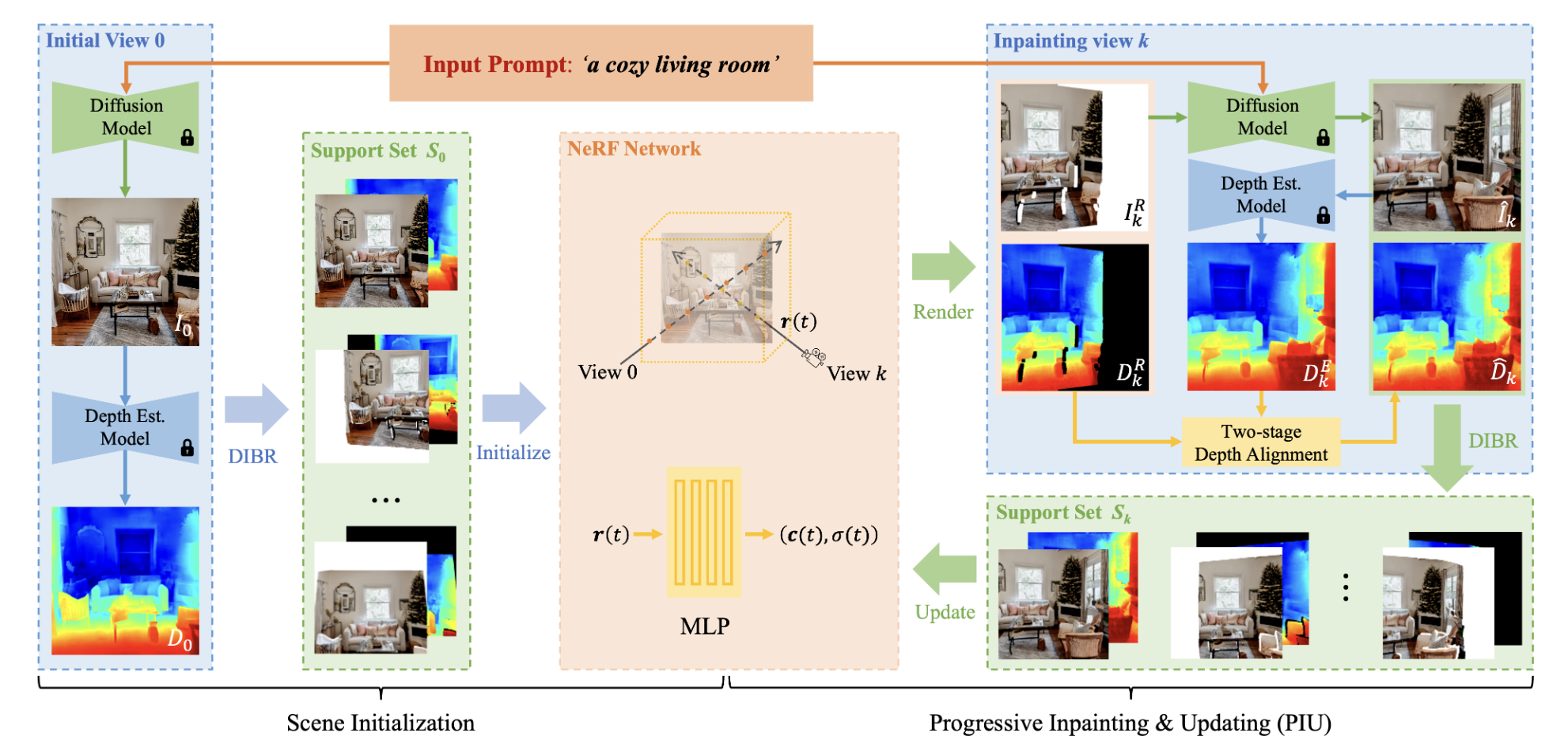
The NeRF representation’s parameters are optimized using depth and content priors. To be more precise, they use a monocular depth estimation approach to provide the geometric prior of the created scene and the diffusion model to construct a text-related picture as the content prior. Additionally, they suggest a progressive inpainting and updating technique (PIU) for the unique view synthesis of the 3D scene to ensure consistency across various viewpoints. The created scene can be enlarged and modified view-by-view in accordance with a camera trajectory using the PIU approach. By rendering the updated NeRF in this manner, the increased area of the current view may be mirrored in the following view, guaranteeing that the same region won’t be extended again during the scene expansion process and maintaining the continuity and view consistency of the created scene. In a nutshell, NeRF’s PIU method and 3D representation make sure that the diffusion model produces view-consistent pictures while creating a 3D scene. Due to the lack of multiview constraints, they discover that single view training in NeRF results in overfitting to this view, which leads to geometric uncertainty during view-by-view updating.
They provide a support set for the produced view to offer multiview constraints for the NeRF model to solve this problem. Meanwhile, they use an L2 depth loss in addition to picture RGB loss, inspired by, to accomplish depth-aware NeRF optimization and boost the NeRF model’s convergence rate and stability. They also present a two-stage depth alignment technique to align the depth value of the same point from multiple viewpoints, considering that the depth maps at separate views are estimated independently and may be inconsistent in overlapping areas. Their Text2NeRF can produce various high-fidelity and view-consistent 3D sceneries from natural language descriptions because of the aforementioned well-designed components.
Due to the method’s universality, Text2NeRF created various 3D settings, including artistic, interior, and outdoor scenes. Text2NeRF is also not constrained by the view range and can create 360-degree views. Numerous tests show that their Text2NeRF works qualitatively and numerically better than the earlier techniques. The following is a summary of their contributions: • They provide a text-driven framework for creating realistic 3D settings that combine diffusion modelling with NeRF representations and allow for zero-shot creation of a range of interior and outdoor scenes using a variety of natural language prompts.
• They provide the PIU technique, which gradually produces unique contents that are view-consistent for 3D scenes, and they construct the support set, which offers multiview constraints for the NeRF model during view-by-view updating.
• They implement a two-stage depth alignment technique to eliminate estimated depth misalignment in various perspectives, and they use the depth loss to accomplish depth-aware NeRF optimization. The code will soon be released on GitHub.
Check out the Paper and Project Page. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.