Researchers expand on the recently developed RelPose framework, which trains a network to predict distributions of relative rotations across pairs of images
The arduous task of recovering 3D from 2D images has advanced quickly in recent years, thanks to neural field-based algorithms that enable high-fidelity 3D recording of typical objects and environments and dense multiview observations. Additionally, there has been an upsurge in interest in making it possible to perform comparable reconstructions in sparse-view settings when there are only a few pictures of the underlying instance, such as online markets or casual user grabs. Several sparse-view reconstruction methods have yielded promising results, but they mostly rely on known (precise or approximative) 6D camera locations for this 3D inference and sidestep the problem of how these 6D poses may be obtained in the first place.
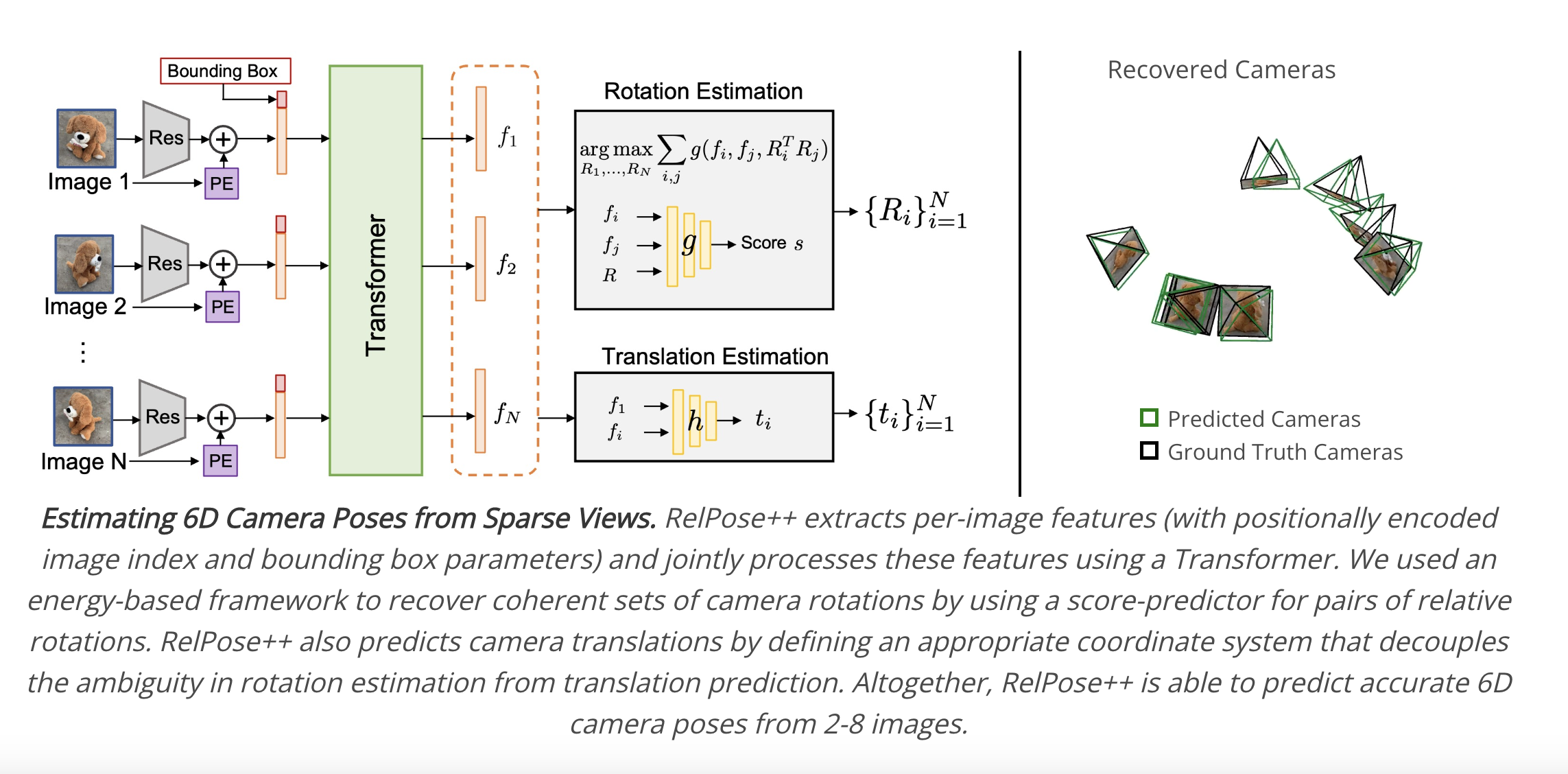
In this study, researchers from Carnegie Mellon University create a system that can fill in this gap and reliably determine (coarse) 6D postures for a generic item, such as a Fetch robot, from a limited set of photos (Fig. 1). Although it depends on bottom-up correspondences, the traditional method of recapturing camera postures from a series of images is not reliable in sparse-view scenarios with little overlap between subsequent views. Instead, their work uses a top-down strategy and expands on RelPose, which forecasts distributions across pairwise relative rotations before optimizing multiview consistent rotation hypotheses. RelPose’s projected allocations only consider pairs of pictures, which can be restrictive even if this optimization aids in enforcing multiview consistency.

Figure 1: Estimating 6D Camera Poses from Sparse Views. They suggest the RelPose++ framework, which can determine the necessary 6D camera rotations and translations from a sparse set of input photos (top: the cameras are colored from red to magenta, depending on the image index). RelPose++ may use multi-view cues while estimating a probability distribution across the relative rotations of the cameras corresponding to any two pictures. They discover that the distribution gets better when more photographs are included for context (bottom).
For instance, they cannot determine the Y-axis rotation of the bottle in Figure. 1’s first two photos since the second label might be on either the side or the back of the container. However, if they also consider the third image, they can immediately see that the first two images should be rotated by about 180 degrees! They expand on this realization in their framework RelPose++, which they offer, and provide a technique for collaboratively reasoning across several photos to forecast pairwise relative distributions. They specifically include a transformer-based module that updates the image-specific characteristics afterward utilized for relative rotation inference using context across all input pictures.
In addition to predicting camera rotations, RelPose++ also infers the camera translation to produce 6D camera poses. One major problem is that the world coordinate frame used to define camera extrinsic can be arbitrarily chosen. Naive solutions to this problem, like instantiating the first camera as the world origin, lead to predictions of camera translations and (relative) camera rotations becoming entangled. Instead, they provide a world coordinate frame centered at the point where the cameras’ optical axes converge for roughly center-facing pictures. They demonstrate how this aids in decoupling the rotational and translational prediction tasks and produces observable empirical advantages.
RelPose++ can recover 6D camera poses for objects in visible and unseen categories given just a few photos after being trained on 41 types from the CO3D dataset. They discover that RelPose++ outperforms the most recent cutting-edge sparse-view approaches by over 25% regarding rotation prediction accuracy. They illustrate the advantages of prediction in their suggested coordinate system and assess the full 6D camera poses by gauging the accuracy of the anticipated camera centers (while taking similarity transform ambiguity into consideration). In the hopes that it may also be useful for analyzing future strategies, they also develop a measure that assesses the accuracy of camera translations (decoupled from the accuracy of anticipated rotations). Finally, they demonstrate how the 6D poses from RelPose++ can directly benefit 3D reconstruction techniques that utilize sparse views in the future. The code and demo are made available on GitHub.
Check out the Paper, GitHub link, and Project page. Don’t forget to join our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.