Scaling Generative Retrieval: Google Research and University of Waterloo’s Empirical Study on Generative Retrieval Across Diverse Corpus Scales, Including a Deep Dive into the 8.8M-Passage MS MARCO Task
In a revolutionary leap forward, generative retrieval approaches have emerged as a disruptive paradigm in information retrieval methods. Harnessing the potential of advanced sequence-to-sequence Transformer models, these approaches aim to transform how we retrieve information from vast document corpora. Traditionally limited to smaller datasets, a recent groundbreaking study titled “How Does Generative Retrieval Scale to Millions of Passages?” conducted by a team of researchers from Google Research and the University of Waterloo, delves into the uncharted territory of scaling generative retrieval to entire document collections comprising millions of passages.
Generative retrieval approaches approach the information retrieval task as a unified sequence-to-sequence model that directly maps queries to relevant document identifiers using the innovative Differentiable Search Index (DSI). Through indexing and retrieval, DSI learns to generate document identifiers based on their content or pertinent queries during the training stage. During inference, it processes a query and presents retrieval results as a ranked list of identifiers.
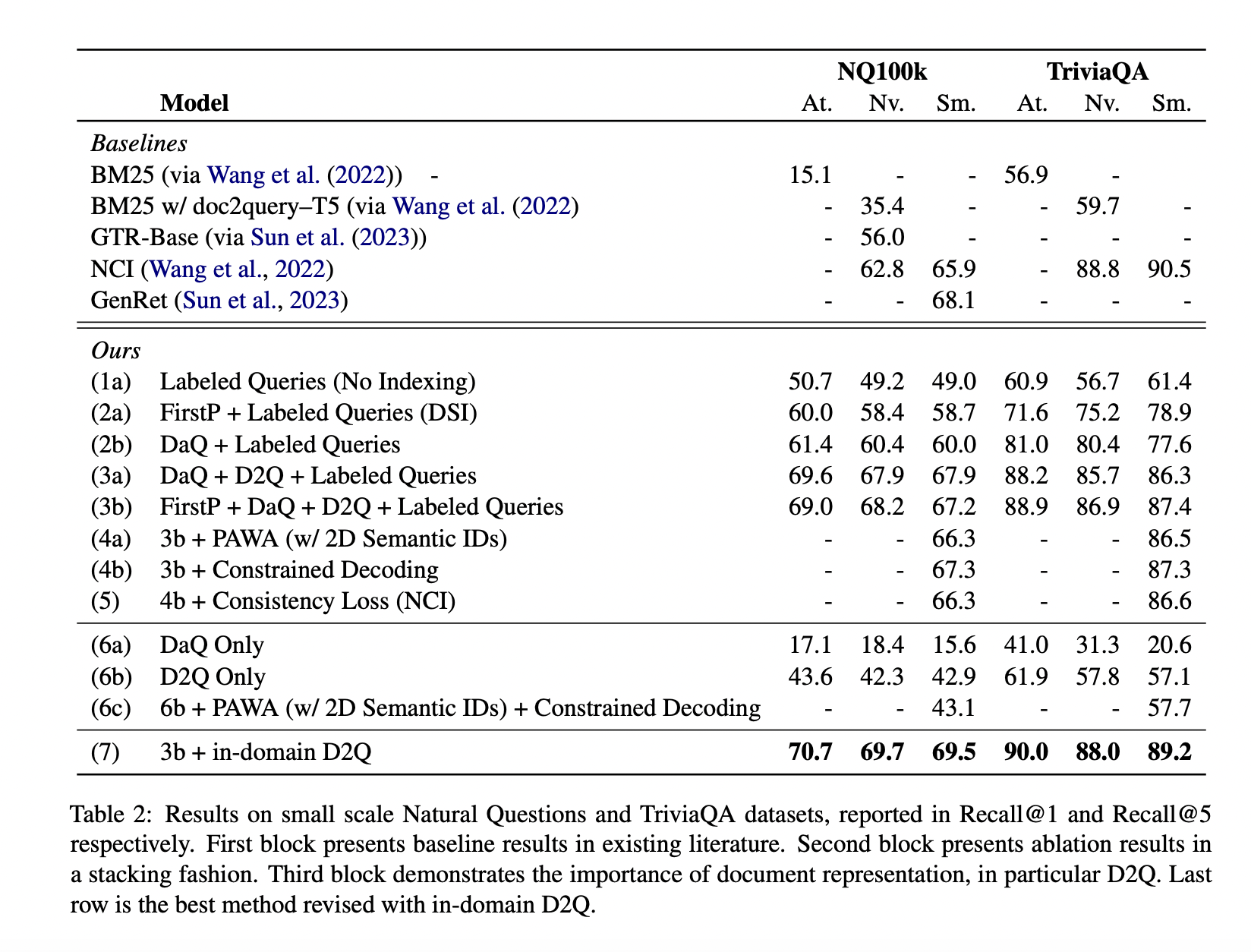
The researchers embarked on a journey to explore the scalability of generative retrieval, scrutinizing various design choices for document representations and identifiers. They shed light on the challenges posed by the gap between the index and retrieval tasks and the coverage gap. The study highlights four types of document identifiers: unstructured atomic identifiers (Atomic IDs), naive string identifiers (Naive IDs), semantically structured identifiers (Semantic IDs), and the innovative 2D Semantic IDs. Additionally, three crucial model components are reviewed: Prefix-Aware Weight-Adaptive Decoder (PAWA), Constrained decoding, and Consistency loss.
With the ultimate goal of evaluating generative retrieval models on a colossal corpus, the researchers focused on the MS MARCO passage ranking task. This task presented a monumental challenge, as the corpus contained 8.8 million passages. Undeterred, the team pushed the boundaries by exploring model sizes that reached 11 billion parameters. The results of their arduous endeavor led to several significant findings.
First and foremost, the study revealed that synthetic query generation emerged as the most critical component as the corpus size expanded. With larger corpora, generating realistic and contextually appropriate queries became paramount to the success of generative retrieval. The researchers emphasized the importance of considering the compute cost of handling such massive datasets. The computational demands placed on systems necessitate careful consideration and optimization to ensure efficient and cost-effective scaling.
Moreover, the study affirmed that increasing model size is imperative for enhancing the effectiveness of generative retrieval. As the model grows more expansive, its capacity to comprehend and interpret vast amounts of textual information becomes more refined, resulting in improved retrieval performance.
This pioneering work provides invaluable insights into the scalability of generative retrieval, opening up a realm of possibilities for leveraging large language models and their scaling power to bolster generative retrieval on mammoth corpora. While the study addressed numerous critical aspects, it also unearthed new questions that will shape the future of this field.
Looking ahead, the researchers acknowledge the need for continued exploration, including the optimization of large language models for generative retrieval, further refinement of query generation techniques, and innovative approaches to maximize efficiency and reduce computational costs.
In conclusion, the remarkable study conducted by Google Research and the University of Waterloo team showcases the potential of generative retrieval at an unprecedented scale. By unraveling the intricacies of scaling generative retrieval to millions of passages, they have paved the way for future advancements that promise to revolutionize information retrieval and shape the landscape of large-scale document processing.
Check Out The Paper. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.