Researchers from Princeton Introduce MeZO: A Memory-Efficient Zeroth-Order Optimizer that can Fine-Tune Large Language Models (LLMs)
Large Language Models are rapidly advancing with the huge success of Generative Artificial Intelligence in the past few months. These models are contributing to some remarkable economic and societal transformations, the best example of which is the well-known ChatGPT developed by OpenAI, which has had millions of users ever since its release, with the number increasing exponentially, if not the same. This chatbot, based on Natural Language Processing (NLP) and Natural Language Understanding (NLU), allows users to generate meaningful text just like humans. It meaningfully answers questions, summarizes long paragraphs, completes codes and emails, etc. Other LLMs, like PaLM, Chinchilla, BERT, etc., have also shown great performances in the domain of AI.
Fine-tuning pre-trained language models has been a popular approach for a lot of language-related tasks. Fine-tuning allows these models to adapt to specialized domains, incorporate human instructions, and cater to individual preferences. It basically adjusts the parameters of an already trained LLM using a smaller and domain-specific dataset. As language models scale up with more parameters, fine-tuning becomes computationally demanding and memory-intensive for the process of computing gradients during backpropagation. Memory usage is significantly higher than that needed for inference because of the involvement of caching activations, gradients, and storage of gradient history.
Recently, a team of researchers from Princeton University has introduced a solution for the memory issue. Called MeZO, a memory-efficient zeroth-order optimizer, this is an adaptation of the traditional ZO-SGD method that estimates gradients using only differences in loss values and operates in-place, allowing fine-tuning language models with the same memory footprint as inference. The team has focussed on zeroth-order approaches in MeZO as ZO methods can estimate gradients using only two forward passes, making them memory-efficient.
The MeZO algorithm has been particularly designed to optimize Large Language Models with billions of parameters. Some of the main contributions mentioned by the team are –
- MeZO has been developed by modifying the ZO-SGD method and a few variations to run in place on arbitrary-sized models with hardly any memory overhead.
- MeZO has been shown to be compatible with PEFT and comprehensive parameter tunings, like LoRA and prefix tuning.
- MeZO can improve non-differentiable goals like accuracy or F1 score while still utilizing the same amount of memory as inference.
- An adequate pre-training ensures that MeZO’s per-step optimization rate and global convergence rate depend on a specific condition number of the landscape, i.e., the effective local rank rather than a large number of parameters, which is contrasting to the previous ZO lower bounds that imply the convergence rate can be slow according to the number of parameters.
- Experiments suggested that on tests on various model types like masked LM and autoregressive LM, the model scales from 350M to 66B, and downstream tasks like classification, multiple-choice, and generation.
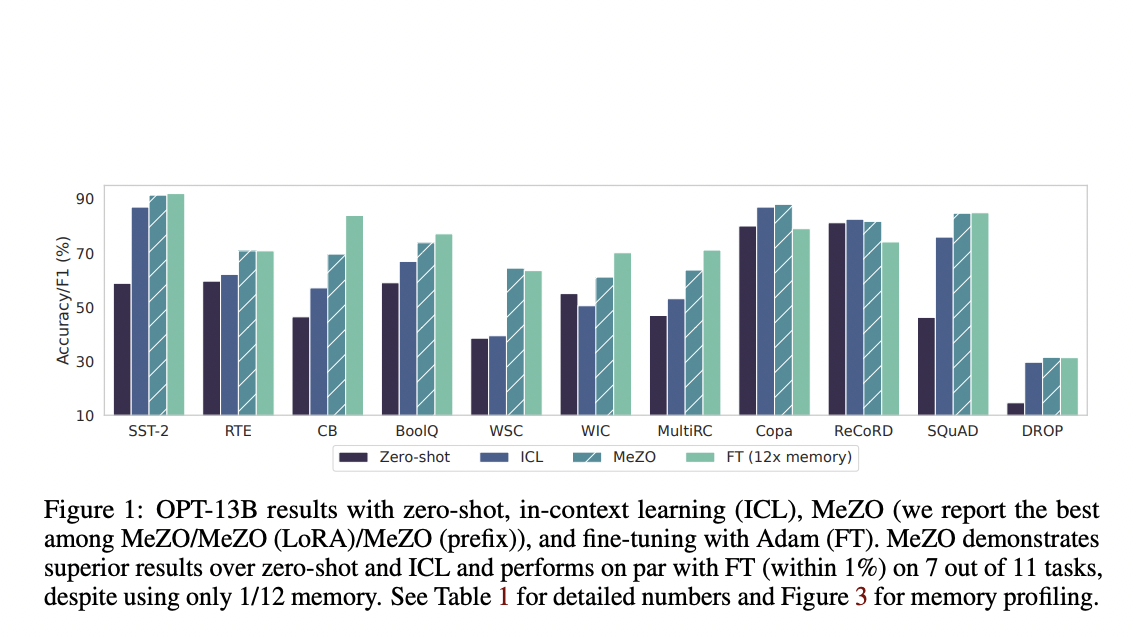
- MeZO outperforms zero-shot, ICL, and linear probing in experiments and even performs better or similarly to fine-tuning on 7 out of 11 tests with OPT-13B, although consuming about 12 less memory than RoBERTa-large or normal fine-tuning, respectively.
Upon evaluation, MeZO was able to train a 30-billion parameter model using a single Nvidia A100 80GB GPU, while backpropagation can only train a 2.7-billion parameter LM within the same memory constraints. In conclusion, MeZO is a memory-efficient zeroth-order optimizer that can effectively fine-tune large language models.
Check Out The Paper and Github. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.