NTU and Microsoft Researchers Propose MIMIC-IT: A Large-Scale Multi-Modal in-Context Instruction Tuning Dataset
Recent developments in artificial intelligence have concentrated on conversational assistants with great comprehension capabilities who can then act. The noteworthy successes of these conversational assistants may be ascribed to the practice of instruction adjustment in addition to the large language models’ (LLMs) high generalization capacity. It entails optimizing LLMs for a variety of activities that are described by varied and excellent instructions. By including instruction adjustment, LLMs get a deeper understanding of user intentions, improving their zero-shot performance even in newly unexplored tasks.
Instruction tuning internalizes the context, which is desirable in user interactions, especially when user input bypasses obvious context, which may be one explanation for the zero-shot speed improvement. Conversational assistants have had amazing progress in linguistic challenges. An ideal casual assistant, however, must be able to handle jobs requiring several modalities. An extensive and top-notch multimodal instruction-following dataset is needed for this. The original vision-language instruction-following dataset is called LLaVAInstruct-150K or LLaVA. It is built utilizing COCO pictures, instructions, and data from GPT-4 based on item bounding boxes and image descriptions.
LLaVA-Instruct-150K is inspirational, yet it has three drawbacks. (1) Limited visual diversity: Because the dataset only uses the COCO picture, its visual diversity is limited. (2) It uses a single image as visual input, but a multimodal conversational assistant should be able to handle several photos or even lengthy films. For instance, when a user asks for assistance in coming up with an album title for a set of photographs (or an image sequence, such as a video), the system needs to respond properly. (3) Language-only in-context information: While a multimodal conversational assistant should use multimodal in-context information to understand better user instructions, language-only in-context information relies entirely on language.
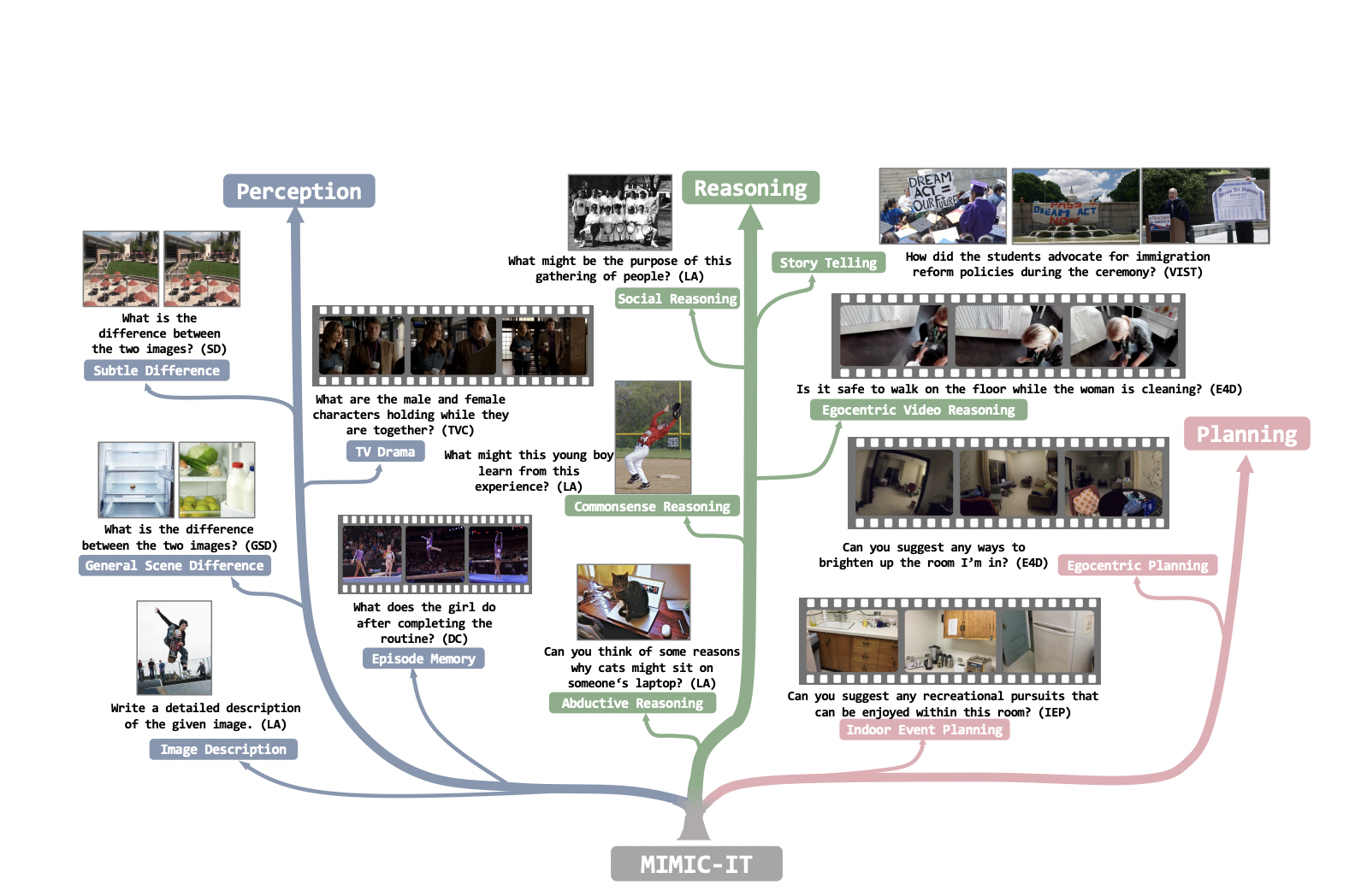
For instance, if a human user offers a specific visual sample of the required features, an assistant can more properly align its description of an image with the tone, style, or other elements. Researchers from S-Lab, Nanyang Technological University, Singapore and Microsoft Research, Redmond provide MIMICIT (Multimodal In-Context Instruction Tuning), which addresses these restrictions. (1) Diverse visual scenes, integrating photos and videos from general scenes, egocentric view scenes, and indoor RGB-D images across different datasets, are a feature of MIMIC-IT. (2) Multiple pictures (or a video) used as visual data to support instruction-response pairings that various images or movies may accompany. (3) Multimodal in-context infor consists of in-context data presented in various instruction-response pairs, photos, or videos (for more details on data format, see Fig. 1).
They provide Sythus, an automated pipeline for instruction-response annotation inspired by the self-instruct approach, to effectively create instruction-response pairings. Targeting the three core functions of vision-language models—perception, reasoning, and planning—Sythus uses system message, visual annotation, and in-context examples to guide the language model (GPT-4 or ChatGPT) in generating instruction-response pairs based on visual context, including timestamps, captions, and object information. Instructions and replies are also translated from English into seven other languages to allow multilingual usage. They train a multimodal model named Otter based on OpenFlamingo on MIMIC-IT.

Otter’s multimodal talents are assessed in two ways: (1) Otter performs best in the ChatGPT evaluation on the MMAGIBenchmark, which compares Otter’s perceptual and reasoning skills to other current vision-language models (VLMs). (2) Human assessment in the Multi-Modality Arena, where Otter performs better than other VLMs and receives the highest Elo score. Otter outperforms OpenFlamingo in all few-shot conditions, according to our evaluation of its few-shot in-context learning capabilities using the COCO Caption dataset.
Specifically, they provided: • The Multimodal In-Context Instruction Tuning (MIMIC-IT) dataset contains 2.8 million multimodal in-context instruction-response pairings with 2.2 million distinct instructions in various real-world settings. • Syphus, an automated process created with LLMs to produce instruction-response pairs that are high-quality and multilingual depending on visual context. • Otter, a multimodal model, exhibits skilful in-context learning and strong multimodal perception and reasoning ability, successfully following human intent.
Check Out The Paper and GitHub link. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.