Meta AI Unveils Revolutionary I-JEPA: A Groundbreaking Leap in Computer Vision That Emulates Human and Animal Learning and Reasoning
Humans pick up a tremendous quantity of background information about the world just by watching it. The Meta team has been working on developing computers that can learn internal models of how the world functions to let them learn much more quickly, plan out how to do challenging jobs, and quickly adapt to novel conditions since last year. For the system to be effective, these representations must be learned directly from unlabeled input, such as images or sounds, rather than manually assembled labeled datasets. This learning process is known as self-supervised learning.
Generative architectures are trained by obscuring or erasing parts of the data used to train the model. This could be done with an image or text. They then make educated guesses about what pixels or words are missing or distorted. However, a major drawback of generative approaches is that the model attempts to fill in any gaps in knowledge, notwithstanding the inherent uncertainty of the real world.
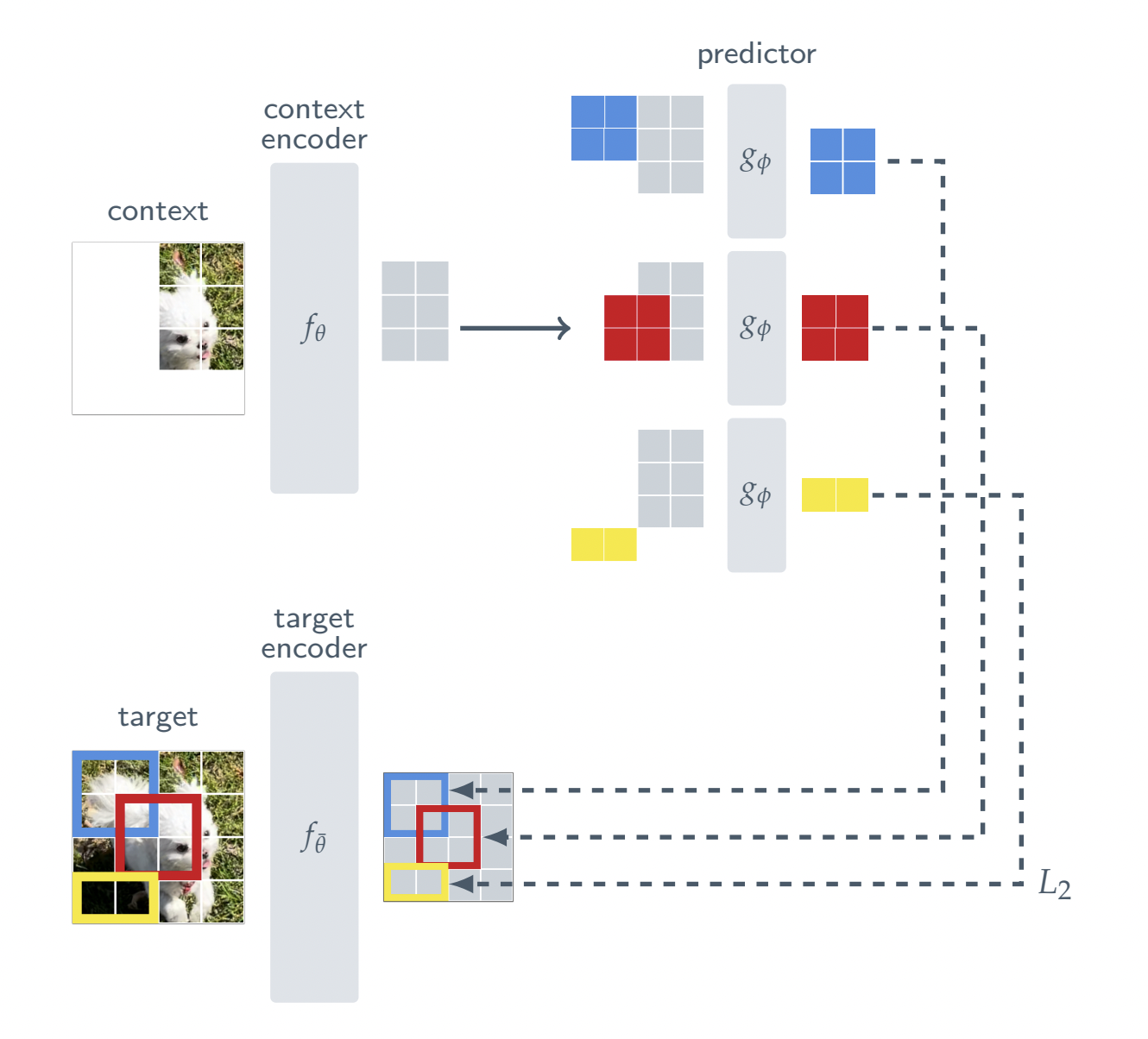
Researchers at Meta have just unveiled their first artificial intelligence model. By comparing abstract representations of images (rather than comparing the pixels themselves), their Image Joint Embedding Predictive Architecture (I-JEPA) can learn and improve over time.
According to the researchers, the JEPA will be free of the biases and problems that plague invariance-based pretraining because it does not involve collapsing representations from numerous views/augmentations of an image to a single point.
The goal of I-JEPA is to fill in knowledge gaps using a representation closer to how individuals think. The proposed multi-block masking method is another important design option that helps direct I-JEPA toward developing semantic representations.
I-JEPA’s predictor can be considered a limited, primitive world model that can describe spatial uncertainty in a still image based on limited contextual information. In addition, the semantic nature of this world model allows it to make inferences about previously unknown parts of the image rather than relying solely on pixel-level information.
To see the model’s outputs when asked to forecast within the blue box, the researchers trained a stochastic decoder that transfers the I-JEPA predicted representations back into pixel space. This qualitative analysis demonstrates that the model can learn global representations of visual objects without losing track of where those objects are in the frame.
Pre-training with I-JEPA uses few computing resources. It doesn’t require the overhead of applying more complex data augmentations to provide different perspectives. The findings suggest that I-JEPA can learn robust, pre-built semantic representations without custom view enhancements. A linear probing and semi-supervised evaluation on ImageNet-1K also beats pixel and token-reconstruction techniques.
Compared to other pretraining methods for semantic tasks, I-JEPA holds its own despite relying on manually produced data augmentations. I-JEPA outperforms these approaches on basic vision tasks like object counting and depth prediction. I-JEPA is adaptable to more scenarios since it uses a less complex model with a more flexible inductive bias.
The team believes that JEPA models have the potential to be used in creative ways in areas like video interpretation is quite promising. Using and scaling up such self-supervised approaches for developing a broad model of the world is a huge step forward.
Check Out The Paper and Github. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.