Revolutionizing AI Efficiency: UC Berkeley’s SqueezeLLM Debuts Dense-and-Sparse Quantization, Marrying Quality and Speed in Large Language Model Serving
Recent developments in Large Language Models (LLMs) have demonstrated their impressive problem-solving ability across several fields. LLMs can include hundreds of billions of parameters and are trained on enormous text corpora.
Studies show that in LLM inference, memory bandwidth, not CPU, is the key performance limitation for generative tasks. This indicates that the rate at which parameters can be loaded and stored for memory-bound situations, rather than arithmetic operations, becomes the key latency barrier. However, progress in memory bandwidth technology has lagged far behind computation, giving rise to a phenomenon known as the Memory Wall.
Quantization is a promising method that involves storing model parameters with less accuracy than the usual 16 or 32 bits used during training. Despite recent advancements like LLaMA and its instruction-following variations, it is still difficult to achieve good quantization performance, especially with lower bit precision and relatively modest models (e.g., 50B parameters).
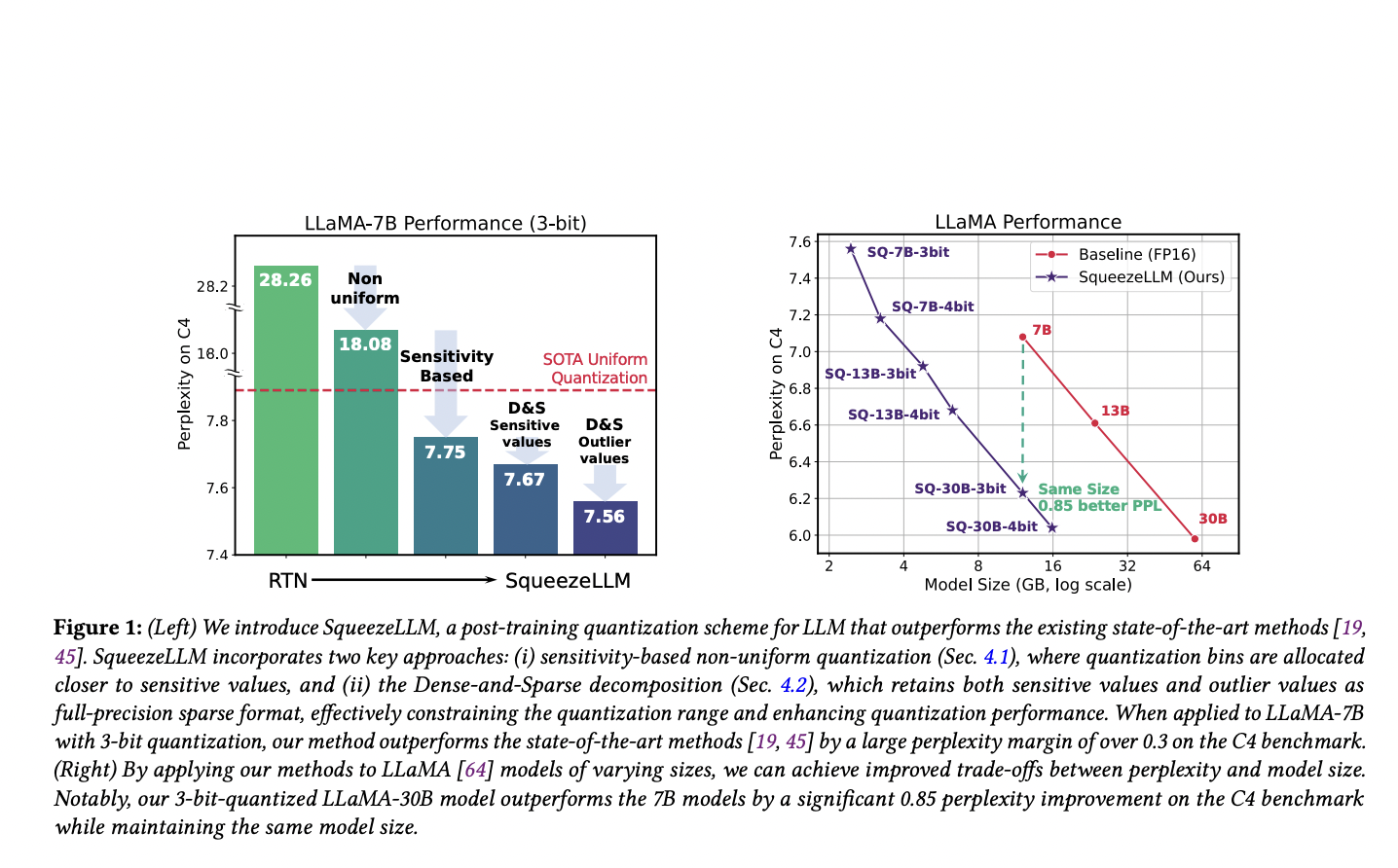
A new study from UC Berkeley investigates low-bit precision quantization in depth to reveal the shortcomings of current methods. Based on these findings, the researchers introduce SqueezeLLM, a post-training quantization framework that combines a Dense-and-Sparse decomposition technique with a unique sensitivity-based non-uniform quantization strategy. These methods permit quantization with ultra-low-bit precision while preserving competitive model performance, drastically cutting down on model sizes and inference time costs. Their method reduces the LLaMA-7B model’s perplexity at 3-bit precision from 28.26 with uniform quantization to 7.75 on the C4 dataset, which is a considerable improvement.
Through comprehensive testing on the C4 and WikiText2 benchmarks, the researchers discovered that SqueezeLLM consistently outperforms existing quantization approaches by a wide margin across different bit precisions when applied to LLaMA-7B, 13B, and 30B for language modeling tasks.
According to the team, the low-bit precision quantization of many LLMs is particularly difficult due to substantial outliers in the weight matrices. These outliers likewise impact their non-uniform quantization approach since they bias the allocation of bits toward extremely high or low values. To eliminate the outlier values, they provide a straightforward method that splits the model weights into dense and sparse components. By isolating the extreme values, the central region displays a narrower range of up to 10, resulting in better quantization precision. With efficient sparse storage methods like Compressed Sparse Rows (CSR), the sparse data can be kept in full precision. This method incurs low overhead by using efficient sparse kernels for the sparse half and parallelizing the computation alongside the dense part.
The team demonstrates their framework’s potential quantizing IF models by applying SqueezeLLM to the Vicuna-7B and 13B models. They compare two systems in their tests. To begin, they use the MMLU dataset, a multi-task benchmark that measures a model’s knowledge and problem-solving abilities, to gauge the quality of the generated output. They also use GPT-4 to rank the generation quality of the quantized models relative to the FP16 baseline, using the evaluation methodology presented in Vicuna. In both benchmarks, SqueezeLLM regularly outperforms GPTQ and AWQ, two current state-of-the-art approaches. Notably, in both assessments, the 4-bit quantized model performs just as well as the baseline.
The work shows considerable latency reductions and advances in quantization performance with their models running on A6000 GPUs. The researchers demonstrate speedups of up to 2.3 compared to the baseline FP16 inference for LLaMA-7B and 13B. Additionally, the proposed method achieves up to 4x quicker latency than GPTQ, demonstrating its efficacy in quantization performance and inference efficiency.
Check Out The Paper and Github. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.