Meet LLM-Blender: A Novel Ensembling Framework to Attain Consistently Superior Performance by Leveraging the Diverse Strengths of Multiple Open-Source Large Language Models (LLMs)
Large Language Models have shown remarkable performance in a massive range of tasks. From producing unique and creative content and questioning answers to translating languages and summarizing textual paragraphs, LLMs have been successful in imitating humans. Some well-known LLMs like GPT, BERT, and PaLM have been in the headlines for accurately following instructions and accessing vast amounts of high-quality data. Models like GPT4 and PaLM are not open-source, which prevents anyone from understanding their architectures and the training data. On the other hand, the open-source nature of LLMs like Pythia, LLaMA, and Flan-T5 provides an opportunity to researchers to fine-tune and improve the models on custom instruction datasets. This enables the development of smaller and more efficient LLMs like Alpaca, Vicuna, OpenAssistant, and MPT.
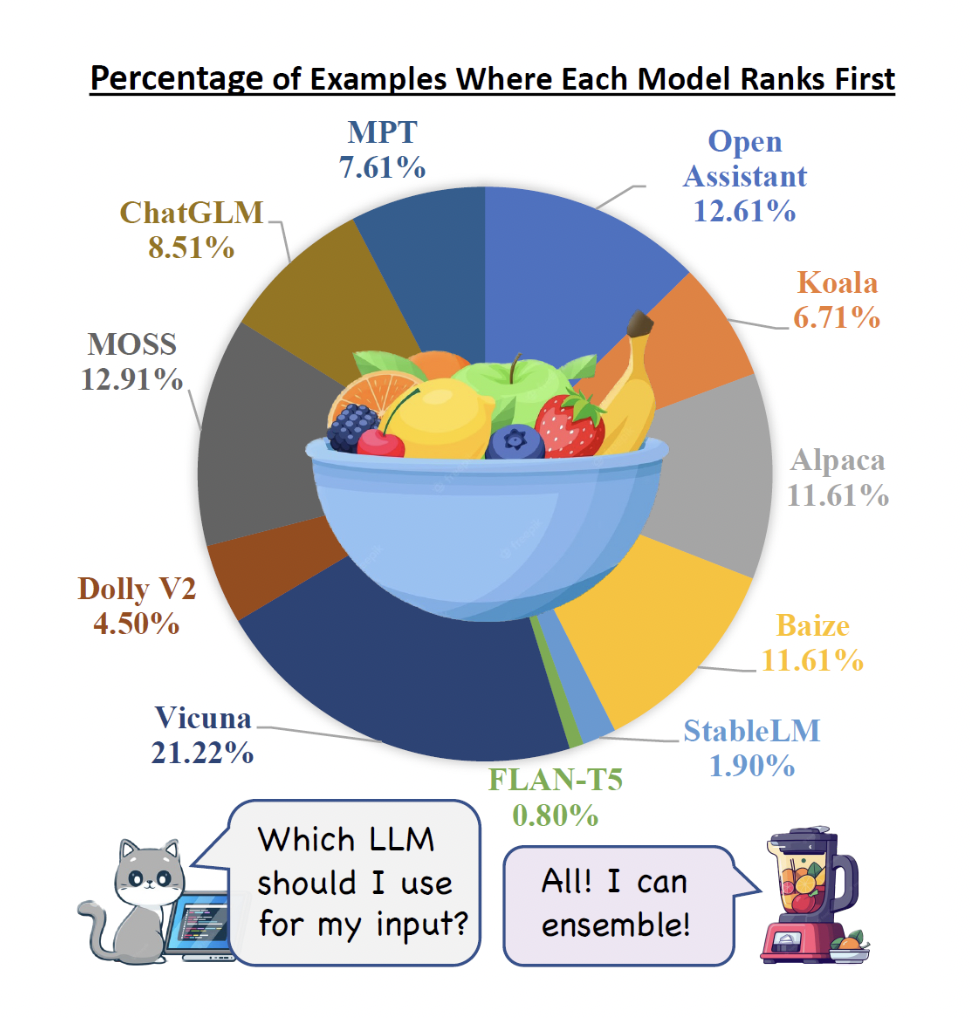
There is no single open-source LLM that leads the market, and the best LLMs for various examples can differ greatly from one another. Therefore, in order to continuously produce improved answers for each input, it is essential to dynamically ensemble these LLMs. Biases, errors, and uncertainties can be reduced by integrating the distinctive contributions of various LLMs, thus resulting in outcomes that more closely match human preferences. To address this, researchers from the Allen Institute for Artificial Intelligence, the University of Southern California, and Zhejiang University have proposed LLM-BLENDER, an ensembling framework that consistently obtains superior performance by utilizing the many advantages of several open-source large language models.
LLM-BLENDER consists of two modules – PAIRRANKER and GENFUSER. These modules show that the optimal LLM for different examples can vary significantly. PAIRRANKER, the first module, has been developed to identify minute variations among potential outputs. It uses an advanced pairwise comparison technique in which the original text and two candidate outputs from various LLMs act as inputs. In order to jointly encode the input and the candidate pair, it makes use of cross-attention encoders like RoBERTa, where the quality of the two candidates can be determined by PAIRRANKER using this encoding.
The second module, GENFUSER, focuses on merging the top-ranked candidates to generate an improved output. It makes the most of the advantages of the chosen candidates while minimizing their disadvantages. GENFUSER aims to develop an output that is superior to the output of any one LLM by merging the outputs of various LLMs.
For evaluation, the team has provided a benchmark dataset called MixInstruct, which incorporates Oracle pairwise comparisons and combines various instruction datasets. This dataset uses 11 popular open-source LLMs to generate multiple candidates for each input across various instruction-following tasks. It comprises training, validation, and test examples with Oracle comparisons for automatic evaluation. These oracle comparisons have been used to give candidate outputs a ground truth ranking, allowing the performance of LLM-BLENDER and other benchmark techniques to be assessed.
The experimental findings have shown that LLM-BLENDER performs much better across a range of evaluation parameters than individual LLMs and baseline techniques. It establishes a sizable performance gap and shows that employing the LLM-BLENDER ensembling methodology results in higher-quality output when compared to using a single LLM or baseline method. PAIRRANKER’s selections have outperformed individual LLM models because of their better performance in reference-based metrics and GPT-Rank. Through efficient fusion, GENFUSER significantly improves response quality by utilizing the top picks from PAIRRANKER.
LLM-BLENDER has also outperformed individual LLMs, like Vicuna, and has thus shown great potential for improving LLM deployment and research through ensemble learning.
Check Out The Paper, Project, and Github. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.