Friendship Ended with Single Modality – Now Multi-Modality is My Best Friend: CoDi is an AI Model that can Achieve Any-to-Any Generation via Composable Diffusion
Generative AI is a term we hear almost every day now. I even don’t remember how many papers I’ve read and summarized about generative AI here. They are impressive, what they do seems unreal and magical, and they can be used in many applications. We can generate images, videos, audio, and more by just using text prompts.
The significant progress made in generative AI models in recent years has enabled use cases that were deemed impossible not so long ago. It started with text-to-image models, and once it was seen that they produced incredibly nice results. After that, the demand for AI models capable of handling multiple modalities has increased.
Recently, there is a surging demand for models that can take any combination of inputs (e.g., text + audio) and generate various combinations of modal outputs (e.g., video + audio) has increased. Several models have been proposed to tackle this, but these models have limitations regarding real-world applications involving multiple modalities that coexist and interact.
While it’s possible to chain together modality-specific generative models in a multi-step process, the generation power of each step remains inherently limited, resulting in a cumbersome and slow approach. Additionally, independently generated unimodal streams may lack consistency and alignment when combined, making post-processing synchronization challenging.
Training a model to handle any mixture of input modalities and flexibly generate any combination of outputs presents significant computational and data requirements. The number of possible input-output combinations scales exponentially, while aligned training data for many groups of modalities is scarce or non-existent.
Let us meet with CoDi, which is proposed to tackle this challenge. CoDi is a novel neural architecture that enables the simultaneous processing and generation of arbitrary combinations of modalities.

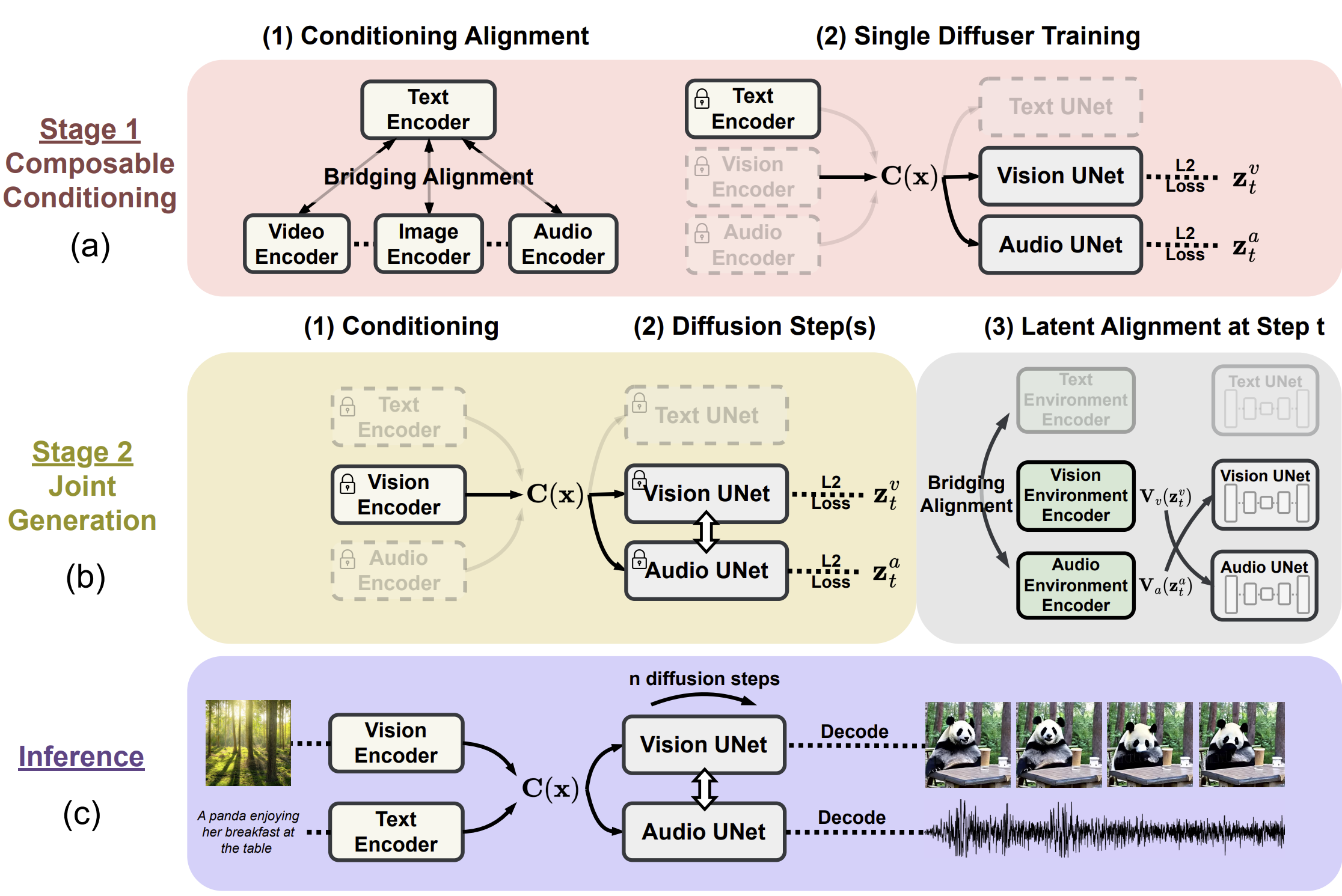
CoDi proposes aligning multiple modalities in both the input conditioning and generation diffusion steps. Additionally, it introduces a “Bridging Alignment” strategy for contrastive learning, enabling it to efficiently model the exponential number of input-output combinations with a linear number of training objectives.
The key innovation of CoDi lies in its ability to handle any-to-any generation by leveraging a combination of latent diffusion models (LDMs), multimodal conditioning mechanisms, and cross-attention modules. By training separate LDMs for each modality and projecting input modalities into a shared feature space, CoDi can generate any modality or combination of modalities without direct training for such settings.
The development of CoDi requires comprehensive model design and training on diverse data resources. First, the training starts with a latent diffusion model (LDM) for each modality, such as text, image, video, and audio. These models can be trained independently in parallel, ensuring exceptional single-modality generation quality using modality-specific training data. For conditional cross-modality generation, where images are generated using audio+language prompts, the input modalities are projected into a shared feature space, and the output LDM attends to the combination of input features. This multimodal conditioning mechanism prepares the diffusion model to handle any modality or combination of modalities without direct training for such settings.

In the second stage of training, CoDi handles many-to-many generation strategies involving the simultaneous generation of arbitrary combinations of output modalities. This is achieved by adding a cross-attention module to each diffuser and an environment encoder to project the latent variable of different LDMs into a shared latent space. This seamless generation capability allows CoDi to generate any group of modalities without training on all possible generation combinations, reducing the number of training objectives from exponential to linear.
Check Out The Paper, Code, and Project. Don’t forget to join our 24k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.