Meet MeLoDy: An Efficient Text-to-Audio Diffusion Model For Music Synthesis
Music is an art composed of harmony, melody, and rhythm that permeates every aspect of human life. With the blossoming of deep generative models, music generation has drawn much attention in recent years. As a prominent class of generative models, language models (LMs) showed extraordinary modeling capability in modeling complex relationships across long-term contexts. In light of this, AudioLM and many follow-up works successfully applied LMs to audio synthesis. Concurrent with the LM-based approaches, diffusion probabilistic models (DPMs), as another competitive class of generative models, have also demonstrated exceptional abilities in synthesizing speech, sounds, and music.
However, generating music from free-form text remains challenging as the permissible music descriptions can be diverse and relate to genres, instruments, tempo, scenarios, or even some subjective feelings.
Traditional text-to-music generation models often focus on specific properties such as audio continuation or fast sampling, while some models prioritize robust testing, which is occasionally conducted by experts in the field, such as music producers. Furthermore, most are trained on large-scale music datasets and demonstrated state-of-the-art generative performances with high fidelity and adherence to various aspects of text prompts.
Yet, the success of these methods, such as MusicLM or Noise2Music, comes with high computational costs, which would severely impede their practicalities. In comparison, other approaches built upon DPMs made efficient samplings of high-quality music possible. Nevertheless, their demonstrated cases were comparatively small and showed limited in-sample dynamics. Aiming for a feasible music creation tool, a high efficiency of the generative model is essential since it facilitates interactive creation with human feedback being taken into account, as in a previous study.
While LMs and DPMs both showed promising results, the relevant question is not whether one should be preferred over another but whether it is possible to leverage the advantages of both approaches concurrently.
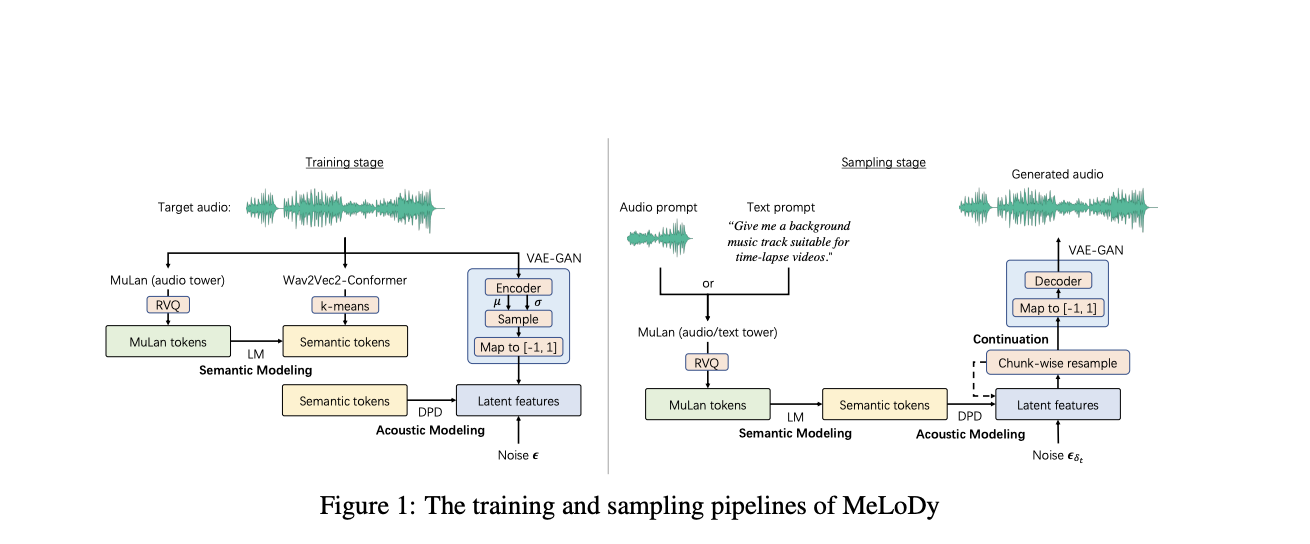
According to the mentioned motivation, an approach termed MeLoDy has been developed. The overview of the strategy is presented in the figure below.
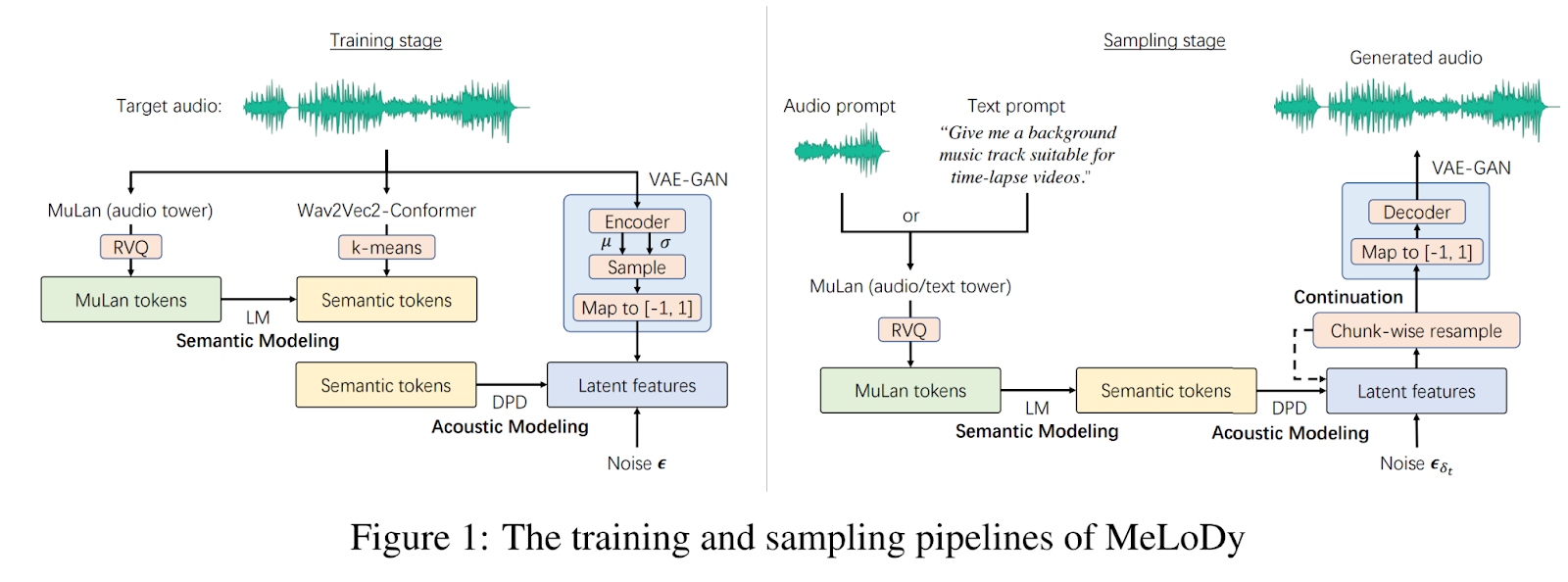
After analyzing the success of MusicLM, the authors leverage the highest-level LM in MusicLM, termed semantic LM, to model the semantic structure of music, determining the overall arrangement of melody, rhythm, dynamics, timbre, and tempo. Conditional on this semantic LM, they exploit the non-autoregressive nature of DPMs to model the acoustics efficiently and effectively with the help of a successful sampling acceleration technique.
Furthermore, the authors propose the so-called dual-path diffusion (DPD) model instead of adopting the classic diffusion process. Indeed, working on the raw data would exponentially increase the computational expenses. The proposed solution is to reduce the raw data to a low-dimensional latent representation. Reducing the dimensionality of the data hinders its impact on the operations and, hence, decreases the model running time. Afterward, the raw data can be reconstructed from the latent representation through a pre-trained autoencoder.
Some output samples produced by the model are available at the following link: https://efficient-melody.github.io/. The code has yet to be available, which means that, at the moment, it is not possible to try it out, either online or locally.
This was the summary of MeLoDy, an efficient LM-guided diffusion model that generates music audios of state-of-the-art quality. If you are interested, you can learn more about this technique in the links below.
Check Out The Paper. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.