The Artist Pal in Your Pocket: SnapFusion is an AI Approach That Brings the Power of Diffusion Models to Mobile Devices
Diffusion models. This is a term you heard about a lot if you have been paying attention to the advancements in the AI domain. They were the key that enabled the revolution in generative AI methods. We now have models that can generate photorealistic images using text prompts in a span of seconds. They have revolutionized content generation, image editing, super-resolution, video synthesis, and 3D asset generation.
Though this impressive performance does not come cheap. Diffusion models are extremely demanding in terms of computation requirements. That means you need really high-end GPUs to make full use of them. Yes, there are also attempts to make them run on your local computers; but even then, you need a high-end one. On the other hand, using a cloud provider can be an alternative solution, but then you might risk your privacy in that case.
Then, there is also the on-the-go aspect we need to think about. For the majority of people, they spend more time on their phones than their computers. If you want to use diffusion models on your mobile device, well, good luck with that, as it will be too demanding for the limited hardware power of the device itself.
Diffusion models are the next big thing, but we need to tackle their complexity before applying them in practical applications. There have been multiple attempts that have focused on speeding up inference on mobile devices, but they have not achieved seamless user experience or quantitatively evaluated generation quality. Well, it was the story until now because we have a new player on the field, and it’s named SnapFusion.
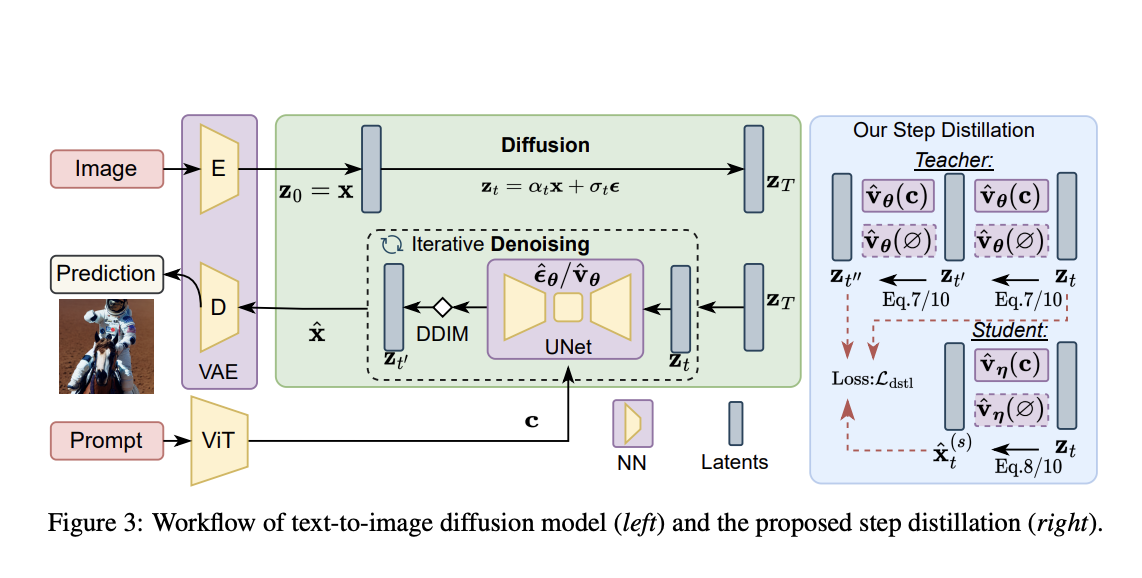
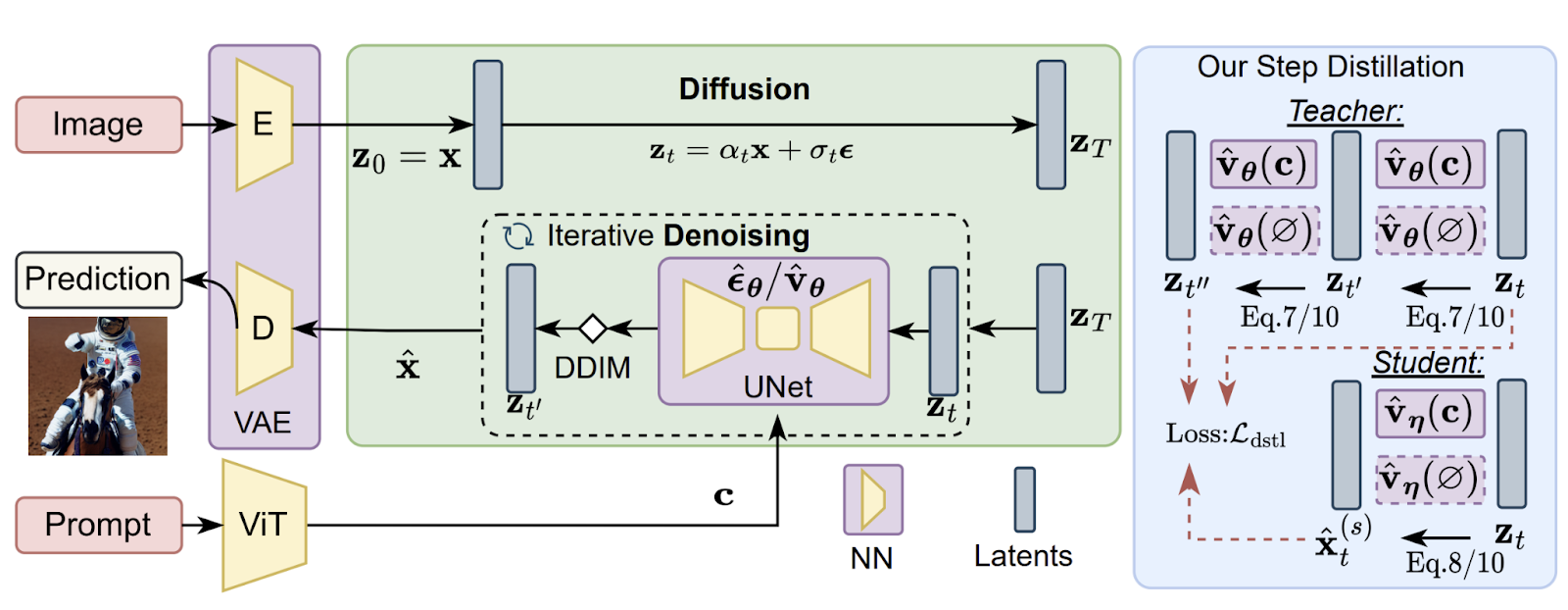
SnapFusion is the first text-to-image diffusion model that generates images on mobile devices in less than 2 seconds. It optimizes the UNet architecture and reduces the number of denoising steps to improve inference speed. Additionally, it uses an evolving training framework, introduces data distillation pipelines, and enhances the learning objective during step distillation.
Before making any changes to the structure, the authors of SnapFusion first investigated the architecture redundancy of SD-v1.5 to obtain efficient neural networks. However, applying conventional pruning or architecture search techniques to SD was challenging due to the high training cost. Any changes in the architecture may result in degraded performance, requiring extensive fine-tuning with significant computational resources. So, that road was blocked, and they had to develop alternative solutions that can preserve the performance of the pre-trained UNet model while gradually improving its efficacy.
To increase inference speed, SnapFusion focuses on optimizing the UNet architecture, which is a bottleneck in the conditional diffusion model. Existing works primarily focus on post-training optimizations, but SnapFusion identifies architecture redundancies and proposes an evolving training framework that outperforms the original Stable Diffusion model while significantly improving speed. It also introduces a data distillation pipeline to compress and accelerate the image decoder.
SnapFusion includes a robust training phase, where stochastic forward propagation is applied to execute each cross-attention and ResNet block with a certain probability. This robust training augmentation ensures that the network is tolerant to architecture permutations, allowing for accurate assessment of each block and stable architectural evolution.
The efficient image decoder is achieved through a distillation pipeline that uses synthetic data to train the decoder obtained via channel reduction. This compressed decoder has significantly fewer parameters and is faster than the one from SD-v1.5. The distillation process involves generating two images, one from the efficient decoder and the other from SD-v1.5, using text prompts to obtain the latent representation from the UNet of SD-v1.5.
The proposed step distillation approach includes a vanilla distillation loss objective, which aims to minimize the discrepancy between the student UNet’s prediction and the teacher UNet’s noisy latent representation. Additionally, a CFG-aware distillation loss objective is introduced to improve the CLIP score. CFG-guided predictions are used in both the teacher and student models, where the CFG scale is randomly sampled to provide a trade-off between FID and CLIP scores during training.

Thanks to the improved step distillation and network architecture development, SnapFusion can generate 512 × 512 images from text prompts on mobile devices in less than 2 seconds. The generated images exhibit quality similar to the state-of-the-art Stable Diffusion model.
Check Out The Paper and Project Page. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Featured Tools From AI Tools Club
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.