Stanford Researchers Introduce SequenceMatch: Training LLMs With An Imitation Learning Loss
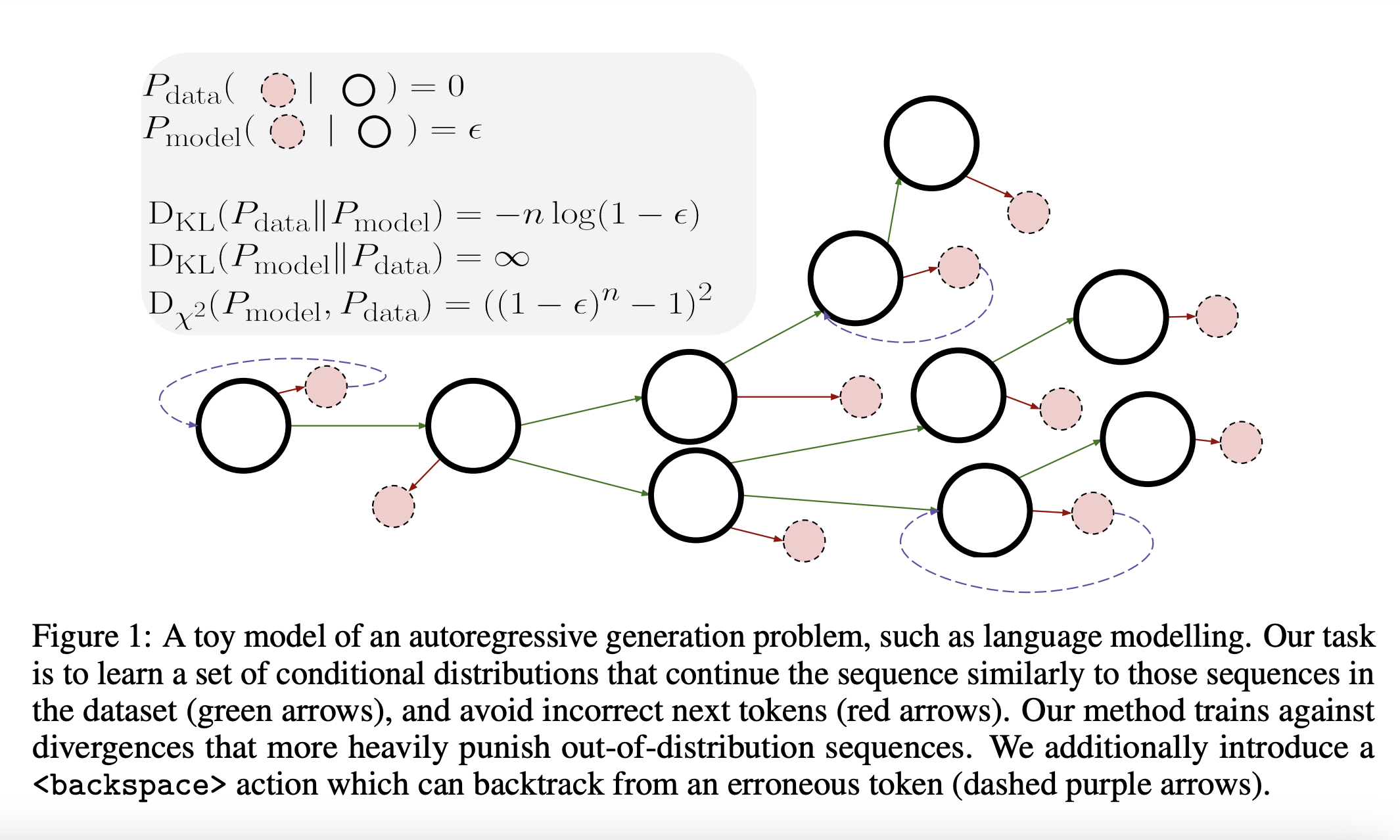
Autoregressive models are a class of statistical models based on the intuition that a variable’s current value largely depends on its past values. In other words, the model predicts the future value of a variable by regressing it on its past values. One of the most well-known examples of autoregressive models is the class of GPT models, especially GPT-3 and its variants, which are largely based on the foundation of predicting the next word in a sequence given the previous words. By training GPT in this autoregressive manner on a large text corpus, it learns to capture the statistical patterns, dependencies, and semantic relationships in language, thereby enabling it to generate contextually relevant text based on the input prompt. However, previous research experiments have shown that smaller models or models which are fine-tuned to have less randomness or variability (i.e., lower generation temperatures) tend to generate repetitive or erroneous outputs. Moreover, in certain scenarios, these models use their own outputs as inputs, often leading to compounding errors that quickly take the model out of its intended distribution.
To overcome these challenges, a team of researchers from Stanford conducted initial studies and identified two main obstacles that prevent autoregressive models trained with maximum likelihood estimation (MLE) from generating coherent sequences during evaluation. The first issue lies in the divergence measure used to assess the disparity between the model and the data distribution. Because MLE doesn’t consider out-of-distribution (OOD) sequences, the model’s behavior on such sequences cannot be controlled. To tackle this, the researchers devised the idea to minimize the χ2-divergence between a combination of actual data and the autoregressively generated sequences, which has shown superior performance compared to MLE. The second challenge arises when the model produces an OOD token without a suitable continuation that is aligned with the data distribution. To address this, the researchers introduce an <backspace> action in the generation process, allowing the model to erase the previous token and rectify any errors it may have made.
By drawing these learnings from their preliminary studies, Stanford Researchers have come up with a novel method called SequenceMatch, which enables the training of autoregressive models against difference divergence techniques while adding an <backspace> action that allows the model to correct errors. The researchers reformulated the problem of sequence generation as a reinforcement learning problem which, in simple terms, can be summarised as choosing the next course of action (which, in this case, is generating the next token) out of all possible sequences for a given state (i.e., a partial sequence). Therefore, by utilizing the latest developments in non-adversarial imitation learning, which is a framework within the field of reinforcement learning, the researchers were able to reduce the divergence between the occupancy measures of a trained model and the distribution of the actual data. Moreover, to further minimize compounding error in sequence generation, the autoregressive model was trained with an <backspace> action, as opposed to MLE, to facilitate backtracking by allowing the model to delete tokens. This fully supervised loss technique for language modeling, SequenceMatch, can be used as an additional step to fine-tune pre-trained models.
The researchers conducted several experimental evaluations to compare the performance of GPT-2 based models fine-tuned on SequenceMatch with MLE-trained models. The researchers used the MAUVE score as a metric to compare the performance, and it was revealed that models fine-tuned on SequenceMatch generated text closer to the dataset and appeared more fluent and error-free in contrast to MLE-trained models. The team also highlighted the limitation of their model as it requires more computational resources and time for generating lengthy texts. When it comes to future work, the researchers are focusing on studying how different divergence methods affect the quality of the sequences generated.
Check Out The Paper. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.