Microsoft Research Introduces phi-1: A New Large Language Model Specialized in Python Coding with Significant Smaller Size than Competing Models
Since the discovery of the Transformer design, the art of training massive artificial neural networks has advanced enormously, but the science underlying this accomplishment is still in its infancy. A sense of order eventually emerged amid the overwhelming and perplexing array of results around the same time Transformers were released, showing that performance increases predictably as one increases either the amount of computing or the network size, a phenomenon now known as scaling laws. These scaling rules served as a guide for the subsequent investigation of scale in deep learning, and the discovery of variations in these laws resulted in a sharp increase in performance.
In this paper, they investigate how the data quality might be improved along a different axis. Higher quality data produces better results; for instance, data cleaning is a crucial step in creating current datasets and can result in relatively smaller datasets or the ability to run the data through more iterations. Recent research on TinyStories, a high-quality dataset created artificially to teach neural networks English, demonstrated that the benefits of high-quality data go far beyond this. By dramatically altering the scaling laws, improved data quality may make it possible to match the performance of large-scale models with much leaner training/models.
In this study, authors from Microsoft Research demonstrate that good-quality data can further enhance the SOTA of large language models (LLMs) while significantly decreasing the dataset size and training computation. The environmental cost of LLMs can be greatly reduced by smaller models that require less training. They build specific Python functions from their docstrings, using LLMs trained for coding. HumanEval, the evaluation standard suggested in the latter paper, has been frequently used to compare LLM performance on code.
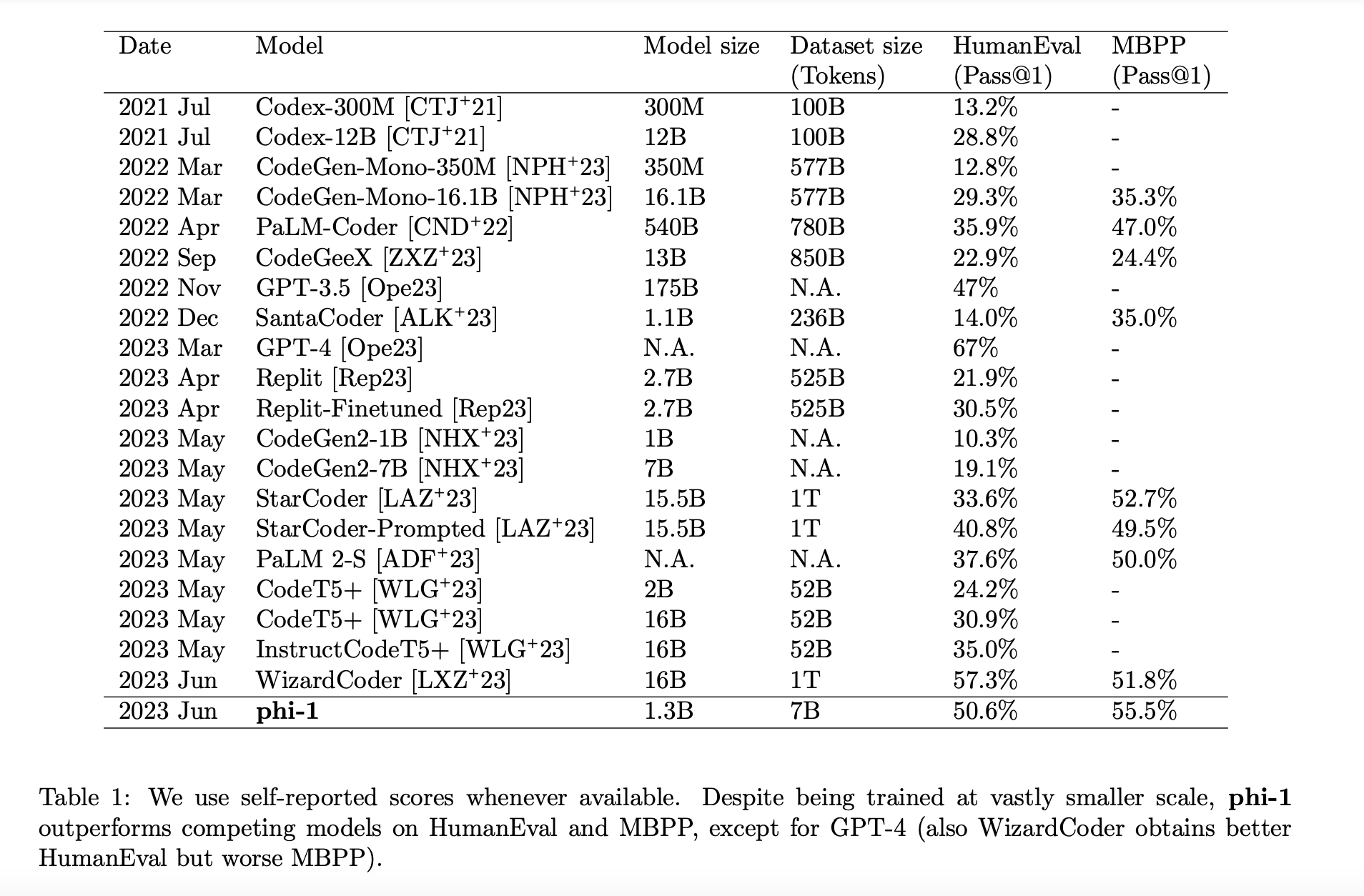
They demonstrate the power of high-quality data in breaking existing scaling laws by training a 1.3B-parameter model, which they call phi-1, for roughly eight passes over 7B tokens (slightly over 50B total tokens seen) followed by finetuning on less than 200M tokens. Roughly speaking, they pretrain on “textbook quality” data, both synthetically generated (with GPT-3.5) and filtered from web sources, and they finetune on “textbook-exercise-like” data. Despite being several orders of magnitude smaller than competing models, both in terms of dataset and model size (see Table 1), they attain 50.6% pass@1 accuracy on HumanEval and 55.5% pass@1 accuracy on MBPP (Mostly Basic Python Programs), which are one of the best self-reported numbers using only one LLM generation.
By training a 1.3B-parameter model they name phi-1 for around eight runs over 7B tokens (just over 50B total tokens observed), followed by finetuning on fewer than 200M tokens, they show the ability of high-quality data to defy established scaling rules. In general, they pretrain on “textbook quality” data that was both artificially created (using GPT-3.5) and filtered from online sources, and they finetune on “textbook-exercise-like” data. They achieve 50.6% pass@1 accuracy on HumanEval and 55.5% pass@1 accuracy on MBPP (Mostly Basic Python Programmes), which is one of the best self-reported numbers using only one LLM generation, despite being several orders of magnitude smaller than competing models.
Check Out The Paper. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.