UC Berkeley And MIT Researchers Propose A Policy Gradient Algorithm Called Denoising Diffusion Policy Optimization (DDPO) That Can Optimize A Diffusion Model For Downstream Tasks Using Only A Black-Box Reward Function
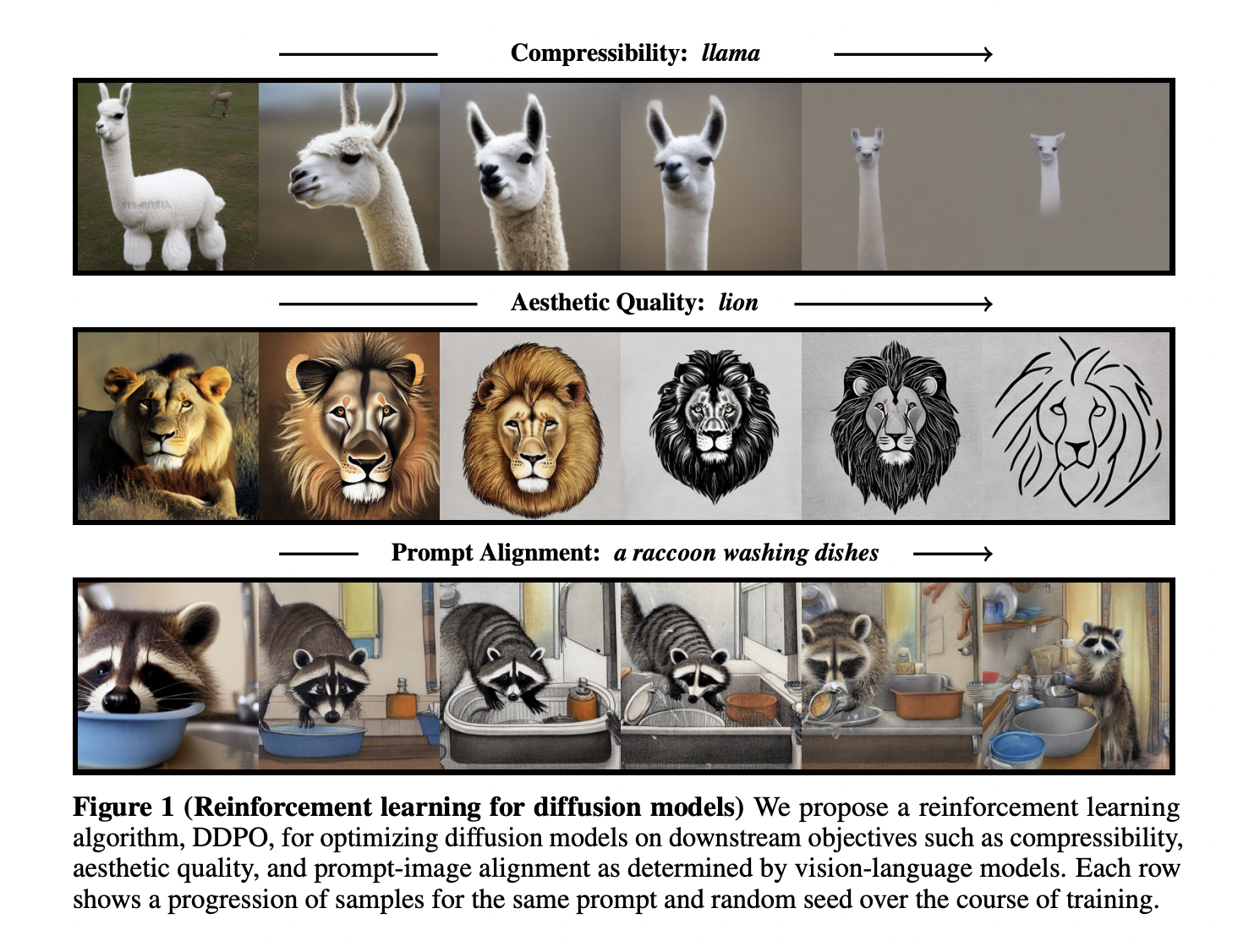
Researchers have made notable strides in training diffusion models using reinforcement learning (RL) to enhance prompt-image alignment and optimize various objectives. Introducing denoising diffusion policy optimization (DDPO), which treats denoising diffusion as a multi-step decision-making problem, enables fine-tuning Stable Diffusion on challenging downstream objectives.
By directly training diffusion models on RL-based objectives, the researchers demonstrate significant improvements in prompt-image alignment and optimizing objectives that are difficult to express through traditional prompting methods. DDPO presents a class of policy gradient algorithms designed for this purpose. To improve prompt-image alignment, the research team incorporates feedback from a large vision-language model known as LLaVA. By leveraging RL training, they achieved remarkable progress in aligning prompts with generated images. Notably, the models shift towards a more cartoon-like style, potentially influenced by the prevalence of such representations in the pretraining data.
The results obtained using DDPO for various reward functions are promising. Evaluations on objectives such as compressibility, incompressibility, and aesthetic quality show notable enhancements compared to the base model. The researchers also highlight the generalization capabilities of the RL-trained models, which extend to unseen animals, everyday objects, and novel combinations of activities and objects. While RL training brings substantial benefits, the researchers note the potential challenge of over-optimization. Fine-tuning learned reward functions can lead to models exploiting the rewards non-usefully, often destroying meaningful image content.
Additionally, the researchers observe a susceptibility of the LLaVA model to typographic attacks. RL-trained models can loosely generate text resembling the correct number of animals, fooling LLaVA in prompt-based alignment scenarios.
In summary, introducing DDPO and using RL training for diffusion models represent significant progress in improving prompt-image alignment and optimizing diverse objectives. The results showcase advancements in compressibility, incompressibility, and aesthetic quality. However, challenges such as reward over-optimization and vulnerabilities in prompt-based alignment methods warrant further investigation. These findings open up new opportunities for research and development in diffusion models, particularly in image generation and completion tasks.
Check out the Paper, Project, and GitHub Link. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.
Credit: Source link
Comments are closed.