The Magic Brush That Works in 3D: Blended-NeRF is an AI Model That Does Zero-Shot Object Generation in Neural Radiance Fields

The recent couple of years were full of eureka moments for various disciplines. We have witnessed revolutionary methods emerging that resulted in colossal advancements. It was ChatGPT for language models, stable diffusion for generative models, and neural radiance fields (NeRF) for computer graphics and vision.
NeRF has emerged as a groundbreaking technique, revolutionizing how we represent and render 3D scenes. NeRF represents a scene as a continuous 3D volume, encoding geometry and appearance information. Unlike traditional explicit representations, NeRF captures scene properties through a neural network, allowing for the synthesis of novel views and accurate reconstruction of complex scenes. By modeling the volumetric density and color of each point in the scene, NeRF achieves impressive photorealism and detail fidelity.
The versatility and potential of NeRF have sparked extensive research efforts to enhance its capabilities and address its limitations. Techniques for accelerating NeRF inference, handling dynamic scenes, and enabling scene editing have been proposed, further expanding the applicability and impact of this novel representation.
Despite all these efforts, NeRFs still have limitations that prevent their adaptability in practical scenarios. Editing NeRF scenes is one of the most important examples here. It is challenging due to the implicit nature of NeRFs and the lack of explicit separation between different scene components.
Unlike the other methods that provide explicit representations like meshes, NeRFs do not provide a clear distinction between shape, color, and material. Moreover, blending new objects into NeRF scenes requires consistency across multiple views, further complicating the editing process.
The ability to capture the 3D scenes is just one part of the equation. Being able to edit the output is equally as important. Digital images and videos are powerful because we can edit them relatively easily, especially with the recent text-to-X AI models that enable effortless editing. So, how could we bring that power to NeRF scenes? Time to meet with Blended-NeRF.
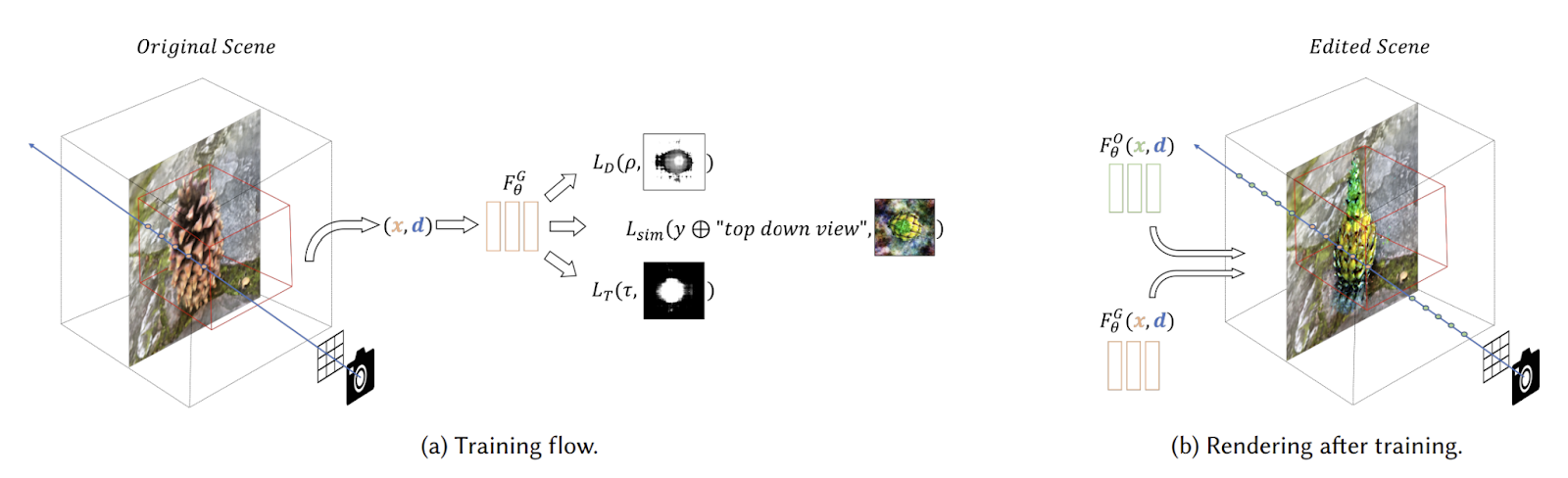
Blended-NeRF is an approach for ROI-based editing of NeRF scenes guided by text prompts or image patches. It allows for editing any region of a real-world scene while preserving the rest of the scene without the need for new feature spaces or sets of two-dimensional masks.
The goal is to generate natural-looking and view-consistent results that seamlessly blend with the existing scene. More importantly, Blended-NeRF is not restricted to a specific class or domain and enables complex text-guided manipulations, such as object insertion/replacement, object blending, and texture conversion.
Achieving all of these features is not easy. That’s why Blended-NeRF leverages a pre trained language-image model, such as CLIP, and a NeRF model initialized on an existing NeRF scene as the generator for synthesizing and blending new objects into the scene’s region of interest (ROI).
The CLIP model guides the generation process based on user-provided text prompts or image patches, enabling the generation of diverse 3D objects that blend naturally with the scene. To enable general local edits while preserving the rest of the scene, a simple GUI is presented to the user for localizing a 3D box within the NeRF scene, utilizing depth information for intuitive feedback. For seamless blending, a novel distance smoothing operation is proposed, merging the original and synthesized radiance fields by blending the sampled 3D points along each camera ray.
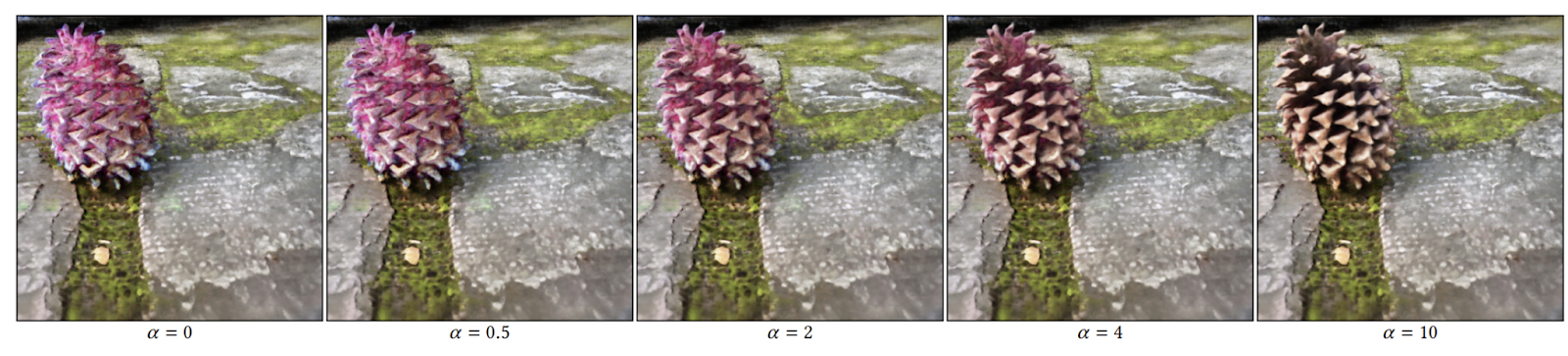
However, there was one more issue. Using this pipeline for editing NeRF scenes yields low-quality, incoherent, and inconsistent results. To address this, the researchers behind Blended-NeRF incorporate augmentations and priors suggested in previous works, such as depth regularization, pose sampling, and directional-dependent prompts, to achieve more realistic and coherent results.
Check out the Paper and Project. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.