Google AI Researchers Introduce Pic2Word: A Novel Approach To Zero-Shot Composed Image Retrieval (ZS-CIR)
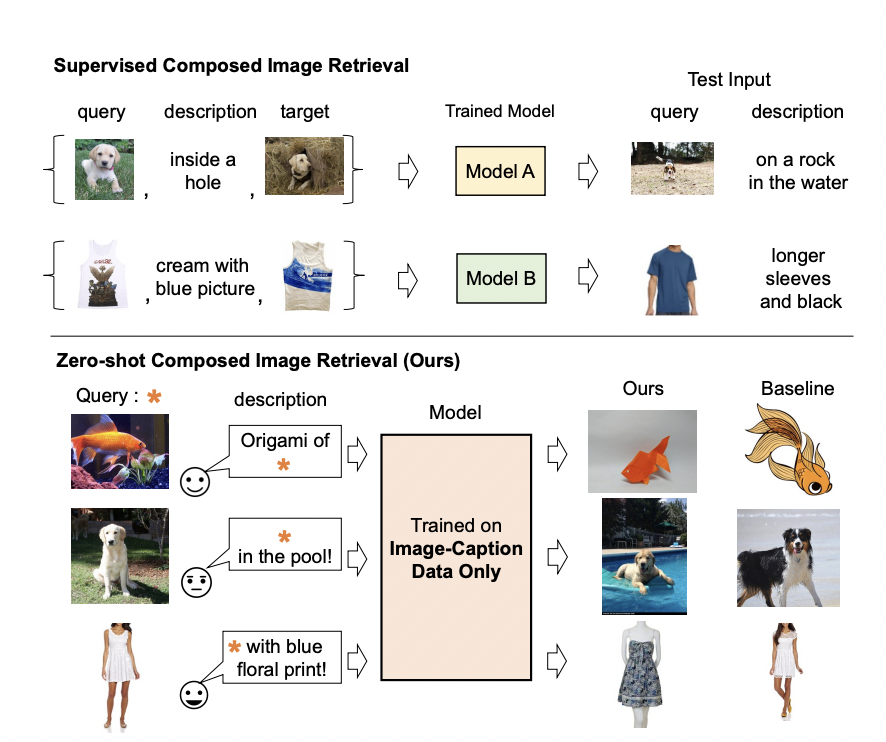
Image Retrieval is a complex process if we try to represent it accurately. Many research scientists are working on this process to ensure minimum loss from the actual image given. Researchers found a way to represent an image through text embeddings. But formatting an image through text is challenging as there was a severe loss and less accuracy. This image representation comes under a broad category of Computer Vision and Convolutional Neural Networks. Researchers developed a Composed image retrieval (CIR) system to have a minimal loss, but the problem with this method was that it requires a large dataset for training the model.
To have a solution to this problem statement, Google AI researchers introduced a method of Pic2Word. This is the same as mapping a function from x to y. Thus, pictures and images are mapped toward words to ensure a zero-shot minimum loss. The advantage of this method is that it doesn’t require any labeled data. It can also act on unlabelled images and caption images, which are easier to collect than the labeled dataset. Research scientists find it very similar to Convolutional Neural Networks. The training set comprises ‘Query and Description’. This information is passed on to the retrieval model, which acts as the hidden layer when compared to the neural networks. We pass on this through the hidden layers, which give a baseline image and our image as an output. In this case, there is a minimal loss between the input and output image.
The Contrastive image pre-trained model proposed by the research scientists is a machine-learning model that generates embeddings for the text and images. The image is passed into the visual encoder, which gives visual embedding spaces. This is processed further into the text encoder, which generates text embeddings. These visual and text embeddings are processed further, giving a minimal loss via this model. This loss is called contrastive loss. Text embeddings are used to search an image, which gives us a retrieved image. The output of the image is a different image but with the same content as before. Thus, the loss that occurred is minimum via this method. The fashion attribute composition model is a machine-learning model in which the same image is obtained as the input image. The color obtained in this model is also the same as the input.
These methods are very helpful in mapping an image to word tokens. Researchers propose to employ a trained CLIP model that treats an image as a text token so that the language encoder can flexibly compose the image features and text description. Researchers perform a comprehensive analysis demonstrating Pic2Word across various diverse tasks.
Check out the Paper, GitHub link, and Blog. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Bhoumik Mhatre is a Third year UG student at IIT Kharagpur pursuing B.tech + M.Tech program in Mining Engineering and minor in economics. He is a Data Enthusiast. He is currently possessing a research internship at National University of Singapore. He is also a partner at Digiaxx Company. ‘I am fascinated about the recent developments in the field of Data Science and would like to research about them.’
Credit: Source link
Comments are closed.