Meet DISCO: A Novel AI Technique For Human Dance Generation
Generative AI has gained significant interest in the computer vision community. Recent advancements in text-driven image and video synthesis, such as Text-to-Image (T2I) and Text-to-Video (T2V), boosted by the advent of diffusion models, have exhibited remarkable fidelity and generative quality. These advancements demonstrate considerable image and video synthesis, editing, and animation potential. However, the synthesized images/videos are still far from perfection, especially for human-centric applications like human dance synthesis. Despite the long history of human dance synthesis, existing methods greatly suffer from the gap between the synthesized content and real-world dance scenarios.
Starting from the era of Generative Adversarial Networks (GANs), researchers have tried to extend the video-to-video style transfer for transferring dance movements from a source video to a target individual, which often requires human-specific fine-tuning on the target person.
Recently, a line of work leverages pre-trained diffusion-based T2I/T2V models to generate dance images/videos conditioned on text prompts. Such coarse-grained condition dramatically limits the degree of controllability, making it almost impossible for users to precisely specify the anticipated subjects, i.e., human appearance, as well as the dance moves, i.e., human pose.
Though the introduction of ControlNet partially alleviates this problem by incorporating pose control with geometric human keypoints, it remains unclear how ControlNet can ensure the consistency of rich semantics, such as human appearance, in the reference image, due to its dependency on text prompts. Moreover, almost all existing methods trained on limited dance video datasets suffer from either limited subject attributes or excessively simplistic scenes and backgrounds. This leads to poor zero-shot generalizability to unseen compositions of human subjects, poses, and backgrounds.
In order to support real-life applications, such as user-specific short video content generation, the human dance generation must adhere to real-world dance scenarios. The generative model is, therefore, expected to synthesize human dance images/videos with the following properties: faithfulness, generalizability, and compositionality.
The generated images/videos should exhibit faithfulness by retaining the appearance of human subjects and backgrounds consistent with the reference images while accurately following the provided pose. The model should also demonstrate generalizability by handling unseen human subjects, backgrounds, and poses without requiring human-specific fine-tuning. Lastly, the generated images/videos should showcase compositionality, allowing for arbitrary combinations of human subjects, backgrounds, and poses sourced from different images/videos.
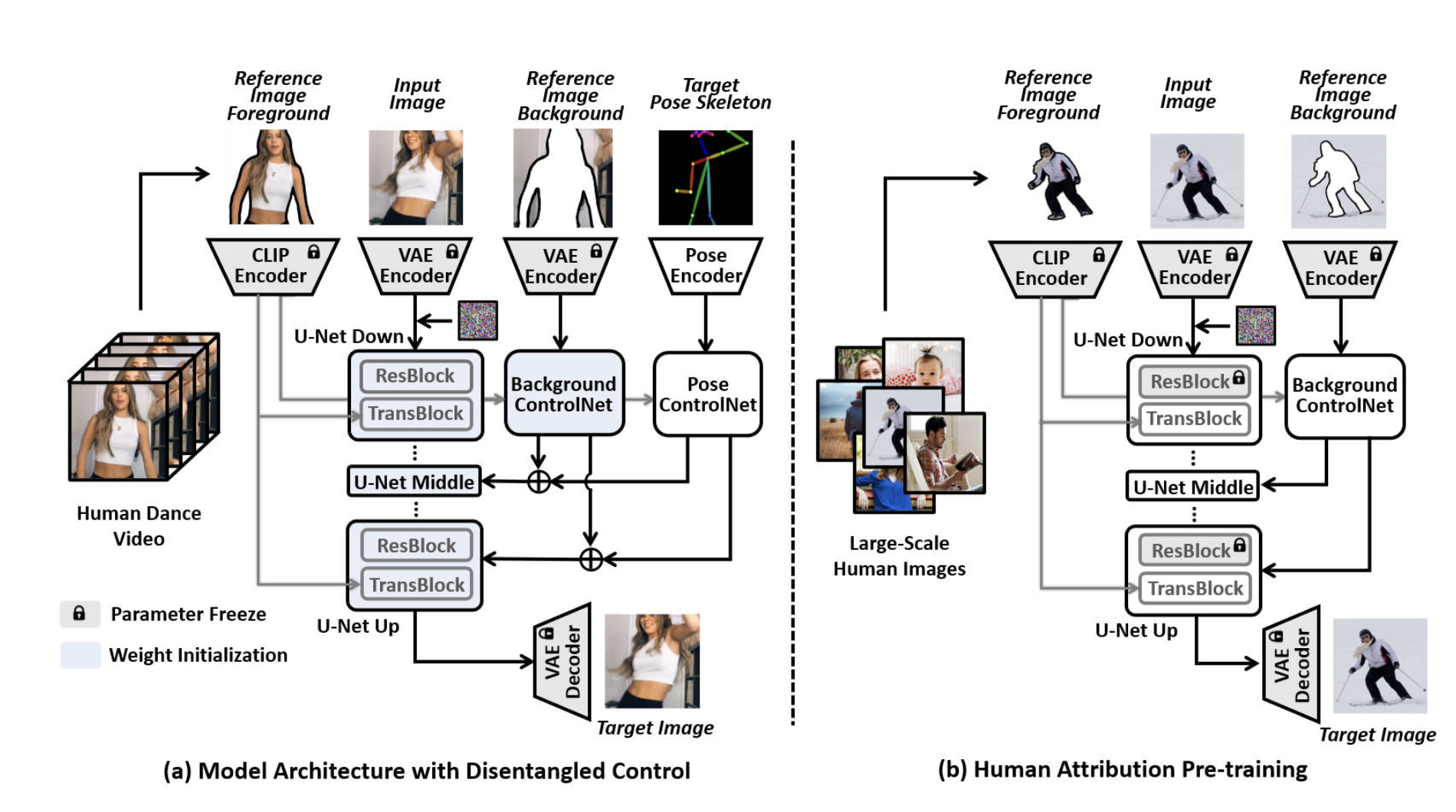
In this regard, a novel approach called DISCO is proposed for human dance generation in real-world scenarios. The overview of the approach is presented in the figure below.

DISCO incorporates two key designs: a novel model architecture with disentangled control for improved faithfulness and compositionality and a pre-training strategy named human attribute pre-training for better generalizability. The novel model architecture of DISCO ensures that the generated dance images/videos faithfully capture the desired human subjects, backgrounds, and poses while allowing for flexible composition of these elements. Additionally, the disentangled control enhances the model’s ability to maintain faithful representation and accommodate diverse compositions. Furthermore, DISCO employs the human attribute pre-training strategy to strengthen the model’s generalizability. This pre-training technique equips the model with the capability to handle unseen human attributes, enabling it to generate high-quality dance content that extends beyond the limitations of the training data. Overall, DISCO presents a comprehensive solution that combines a sophisticated model architecture with an innovative pre-training strategy, effectively addressing the challenges of human dance generation in real-world scenarios.
The outcomes are presented below, together with a comparison of DISCO with the state-of-the-art techniques for human dance generation.

This was the summary of DISCO, a novel AI technique to generate human dance. If you are interested and want to learn more about this work, you can find further information by clicking on the links below.
Check out the Paper, Project, and GitHub link. Don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 800+ AI Tools in AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
Credit: Source link
Comments are closed.