Dive Thinking Like an Annotator: Generation of Dataset Labeling Instructions
We are all amazed by the advancement we have seen in AI models recently. We’ve seen how generative models revolutionized themselves by going from a funky image generation algorithm to the point where it became challenging to differentiate the AI-generated content from real ones.
All these advancements are made possible thanks to two main points. The advanced neural network structures, and maybe more importantly, the availability of large-scale datasets.
Take stable diffusion, for example. Diffusion models have been with us for some time, but we never saw them achieve that sort of result before. What made stable diffusion so powerful was the extremely large-scale dataset it was trained on. When we mean large, it’s really large. We are talking about over 5 billion data samples here.
Preparing such a dataset is obviously a highly demanding task. It requires careful collection of representative data points and supervised labeling. For stable diffusion, this could’ve been automated to some extent. But the human element is always in the equation. The labeling process plays a crucial role in supervised learning, especially in computer vision, as it can make or break the entire process.
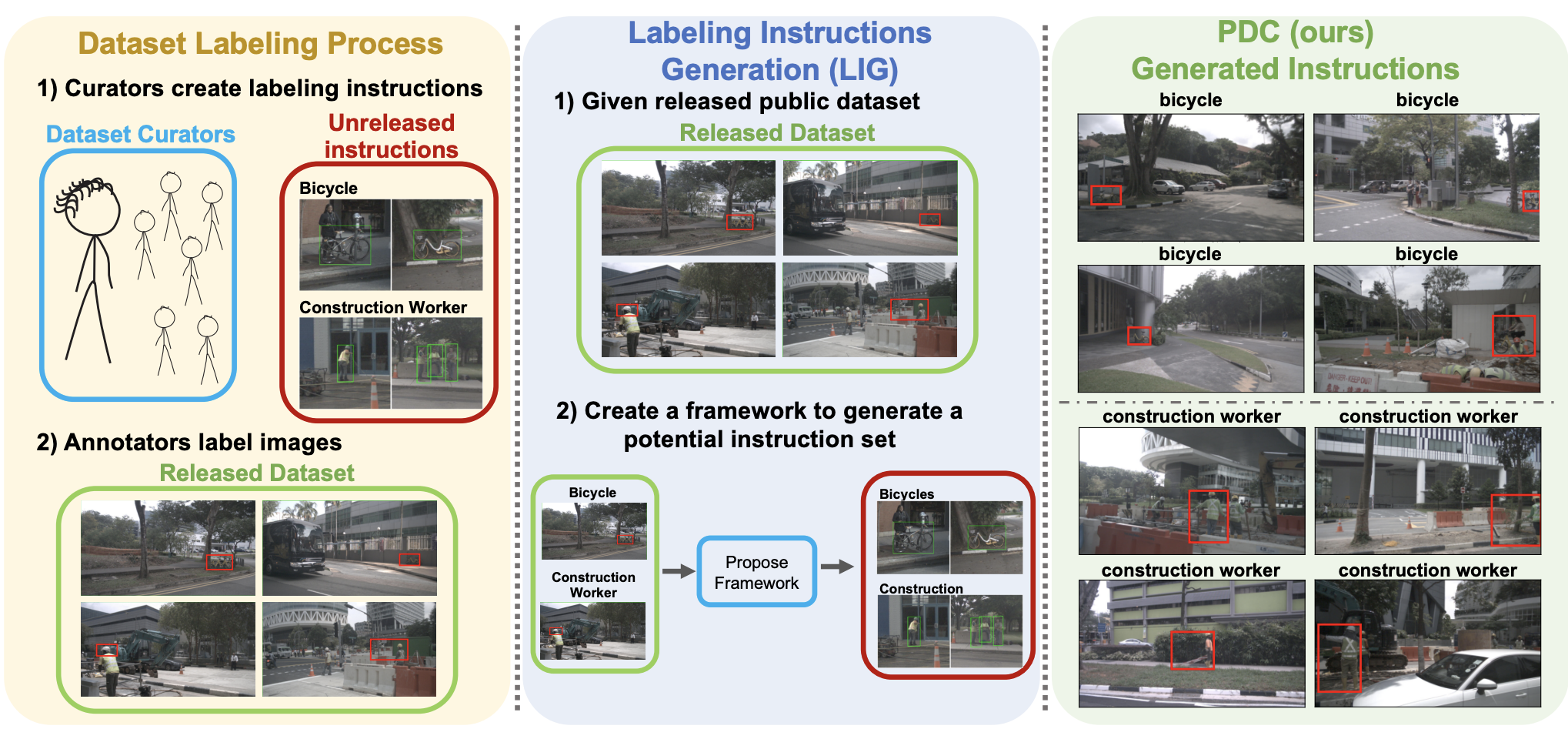
In the field of computer vision, large-scale datasets serve as the backbone for numerous tasks and advancements. However, the evaluation and utilization of these datasets often rely on the quality and availability of labeling instructions (LIs) that define class memberships and provide guidance to annotators. Unfortunately, publicly accessible LIs are rarely released, leading to a lack of transparency and reproducibility in computer vision research.
This lack of transparency possesses significant implications. This oversight has significant implications, including challenges in model evaluation, addressing biases in annotations, and understanding the limitations imposed by instruction policies.
We have new research in our hands that is done to address this gap. Time to meet Labeling Instruction Generation (LIG) task.
LIG aims to generate informative and accessible labeling instructions (LIs) for datasets without publicly available instructions. By leveraging large-scale vision and language models and proposing the Proxy Dataset Curator (PDC) framework, the research seeks to generate high-quality labeling instructions, thereby enhancing the transparency and utility of benchmark datasets for the computer vision community.
LIG aims to generate a set of instructions that not only define class memberships but also provide detailed descriptions of class boundaries, synonyms, attributes, and corner cases. These instructions consist of both text descriptions and visual examples, offering a comprehensive and informative dataset labeling instruction set.
To tackle the challenge of generating LIs, the proposed framework leverages large-scale vision and language models such as CLIP, ALIGN, and Florence. These models provide powerful text and image representations that enable robust performance across various tasks. The Proxy Dataset Curator (PDC) algorithmic framework is introduced as a computationally efficient solution for LIG. It leverages pre-trained VLMs to rapidly traverse the dataset and retrieve the best text-image pairs representative of each class. By condensing text and image representations into a single query via multi-modal fusion, the PDC framework demonstrates its ability to generate high-quality and informative labeling instructions without the need for extensive manual curation.
While the proposed framework shows promise, there are several limitations. For example, the current focus is on generating text and image pairs, and nothing is proposed for more expressive multi-modal instructions. The generated text instructions may also be less nuanced compared to human-generated instructions, but advancements in language and vision models are expected to address this limitation. Furthermore, the framework does not currently include negative examples, but future versions may incorporate them to provide a more comprehensive instruction set.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 900+ AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.