Meet DreamBooth: An AI Technique For Subject-Driven Text-to-Image Generation
Imagine your quadruped friend playing outside or your car showcased in an exclusive showroom. Creating these fictional scenarios is particularly challenging, as it requires combining instances of particular subjects (such as objects or animals) within fresh contexts.
Recently developed large-scale text-to-image models have demonstrated remarkable capabilities in generating high-quality and diverse images based on natural language descriptions. One of the key advantages of such models lies in their ability to leverage a robust semantic understanding acquired from a vast collection of image-caption pairs. This semantic prior enables the model to associate words like “dog” with various representations of dogs, accounting for different poses and contextual variations within an image. While these models excel in synthesis, they cannot faithfully replicate the appearance of subjects from a given reference set or generate new interpretations of those subjects in different contexts. This limitation occurs due to the constrained expressiveness of their output domain. Consequently, even detailed textual descriptions of an object may result in instances with distinct appearances, which is bad news if you were looking for something like this.
The good news is that a new AI approach has been recently introduced to enable the “personalization” of text-to-image diffusion models. This enables a brand-new way of tailoring generative models to meet individual users’ unique image generation requirements. The goal is to expand the model’s language-vision dictionary to establish associations between new words and specific subjects users intend to generate.
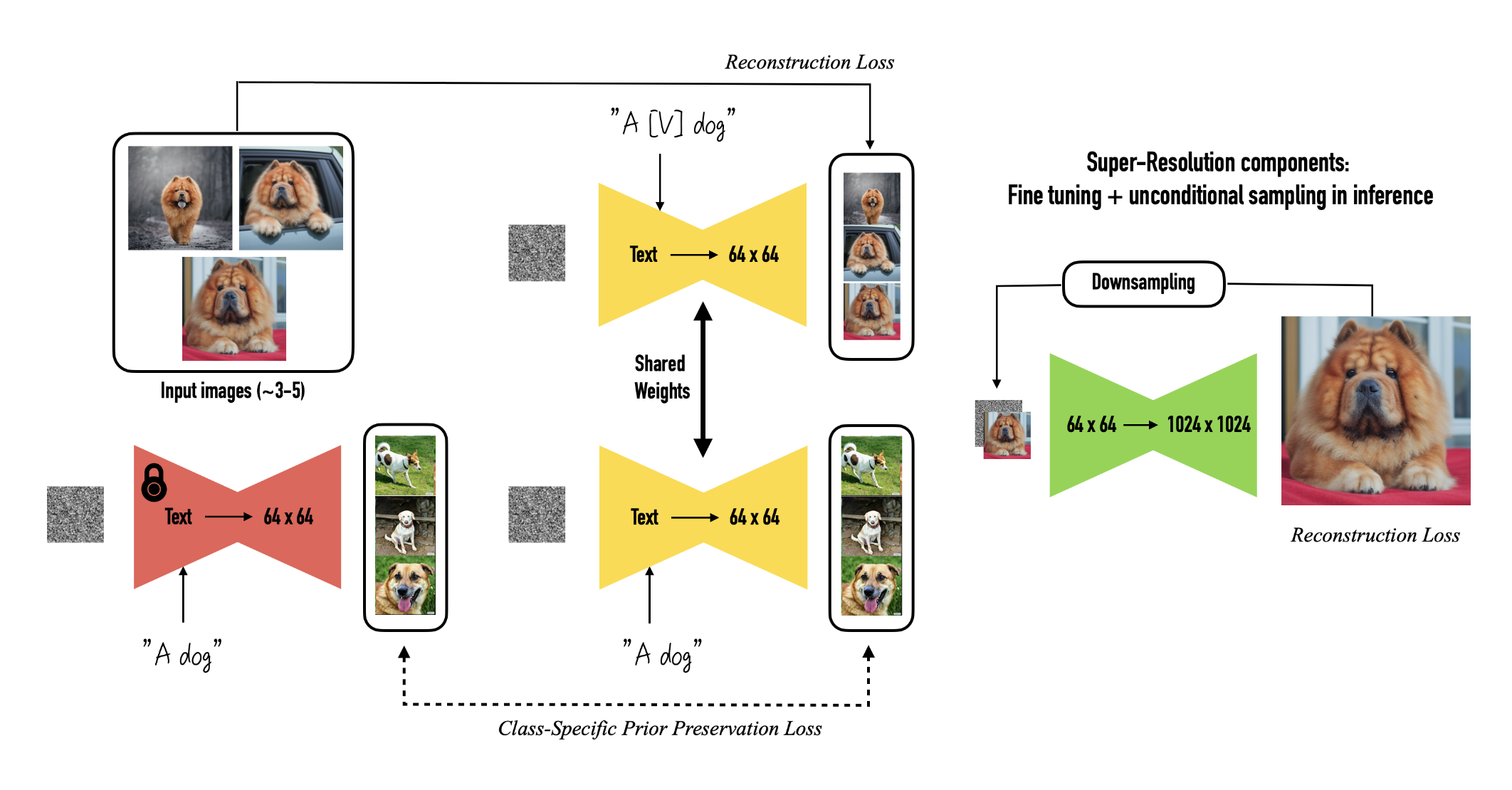
Once the expanded dictionary is integrated into the model, it gains the capability to synthesize novel photorealistic images of the subject set within different scenes while preserving their distinctive identifying features. This process can be intended as a “magic photo booth” where a few subject images are captured, and the booth subsequently generates photos of the subject in diverse conditions and scenes, guided by simple and intuitive text prompts. DreamBooth’s architecture is presented in the figure below.

Formally, the goal is to embed the subject into the model’s output domain in a way that allows its synthesis along with a unique identifier, given a small collection of subject images (around 3-5). To achieve this, DreamBooth represents the subject using rare token identifiers and performs fine-tuning of a pre-trained, diffusion-based text-to-image framework.
The text-to-image model is fine-tuned using input images and text prompts that consist of a unique identifier followed by the class name of the subject (e.g., “A [V] dog”). This approach allows the model to utilize prior knowledge about the subject class while associating the class-specific instance with the unique identifier. A class-specific prior preservation loss is proposed to prevent language drift, which could lead the model to incorrectly associate the class name (e.g., “dog”) with a specific instance. This loss leverages the embedded semantic prior on the class within the model, encouraging the generation of diverse instances of the same class as the subject.
The proposed approach is applied to various text-based image generation tasks, including subject recontextualization, property modification, original art renditions, and more. These applications open up new avenues for previously challenging tasks.
Some output examples for the recontextualization task are presented below, together with the given text prompt to achieve it.

This was the summary of DreamBooth, a novel AI technique for subject-driven text-to-image generation. If you are interested and want to learn more about this work, you can find further information by clicking on the links below.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 900+ AI Tools in AI Tools Club
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.