Diffusion Models Beat GANs on Image Classification: This AI Research finds that Diffusion Models outperform comparable Generative-Discriminative Methods such as BigBiGAN for Classification Tasks
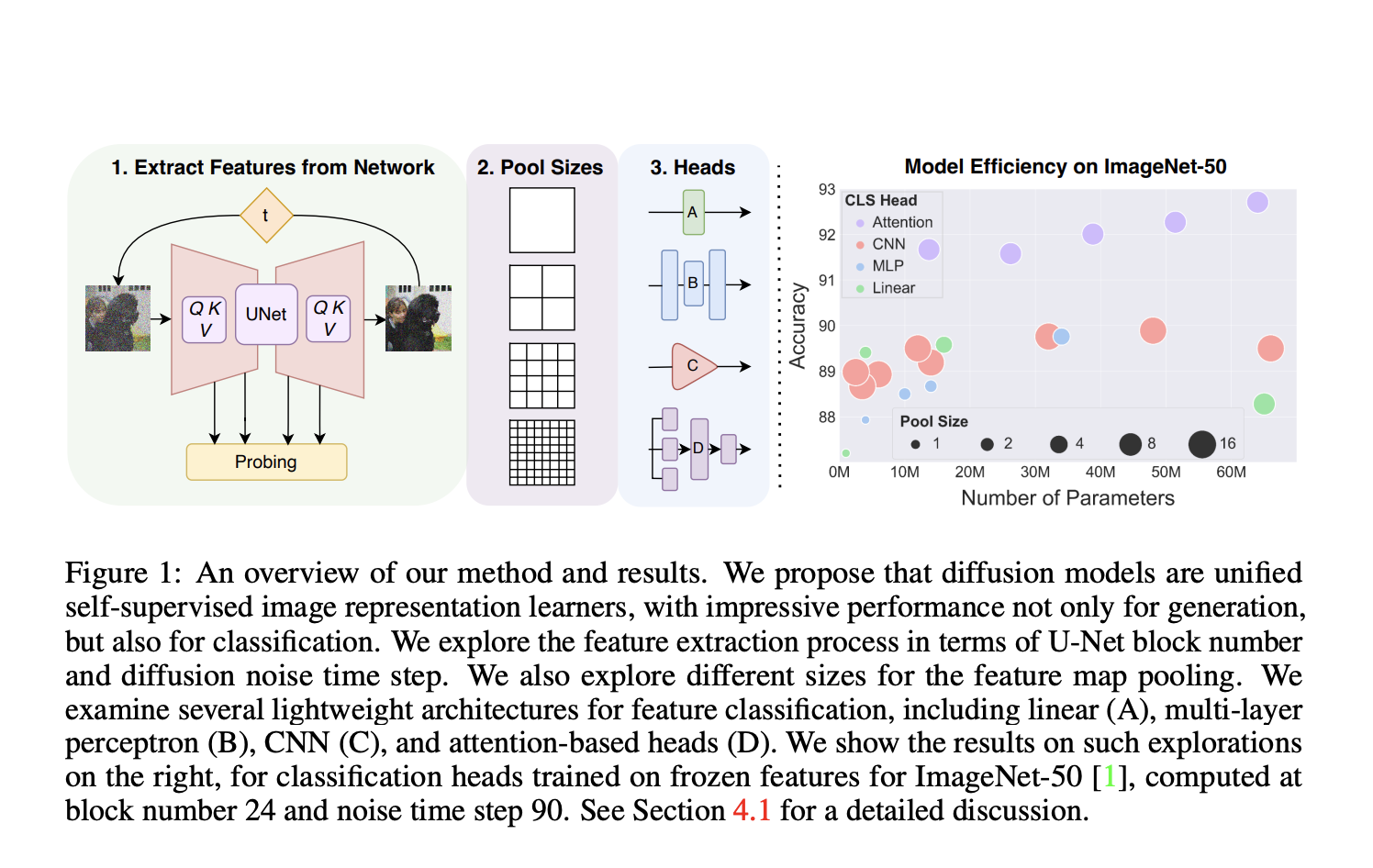
Learning unified, unsupervised visual representations is a crucial yet difficult task. Many computer vision problems fall into two basic categories: discriminative or generative. A model that can assign labels to individual pictures or sections of images is trained through discriminative representation learning. To use generative learning, one would create a model that creates or modifies pictures and carries out related operations like inpainting, super-resolution, etc. Unified representation learners concurrently pursue both goals, and the final model can discriminate and create unique visual artifacts. This type of unified representation learning is difficult.
One of the first deep learning techniques that concurrently solves both families of problems is BigBiGAN. However, the classification and generation performance of more current methods surpasses BigBiGAN’s by using more specialized models. In addition to BigBiGAN’s major accuracy and FID shortcomings, it also has a considerably higher training load than other approaches, is slower and bigger than comparable GANs due to its encoder, and costs more than ResNet-based discriminative approaches due to its GAN. PatchVAE aims to improve VAE’s performance for recognition tasks by concentrating on mid-level patch learning. Unfortunately, its classification improvements still lag far below supervised approaches, and the performance of picture production suffers greatly.
Recent research has made significant strides by performing well in generation and categorization, both with and without supervision. Unified self-supervised representation learning still needs to be addressed because this area still needs to be explored compared to the number of work in self-supervised image representation learning. Some researchers contend that discriminative and generative models vary inherently and that the representations acquired by one are not appropriate for the other due to prior flaws. Generative models inherently require representations that capture low-level, pixel, and texture features for high-quality reconstruction and creation.
On the other hand, discriminative models mainly depend on high-level information that distinguishes objects at a coarse level based not on specific pixel values but rather on the semantics of the image’s content. Despite these assumptions, they indicate that current techniques like MAE and MAGE, where the model must tend to low-level pixel information but learns models that are also excellent for classification tasks, support the early success of BigBiGAN. Modern diffusion models have also been quite successful in achieving generating goals. Their categorization potential is, however, mostly untapped and unstudied. Researchers from the University of Maryland argue that rather than creating a unified representation learner from scratch, cutting-edge diffusion models, potent image-creation models already have strong emergent classification capabilities.
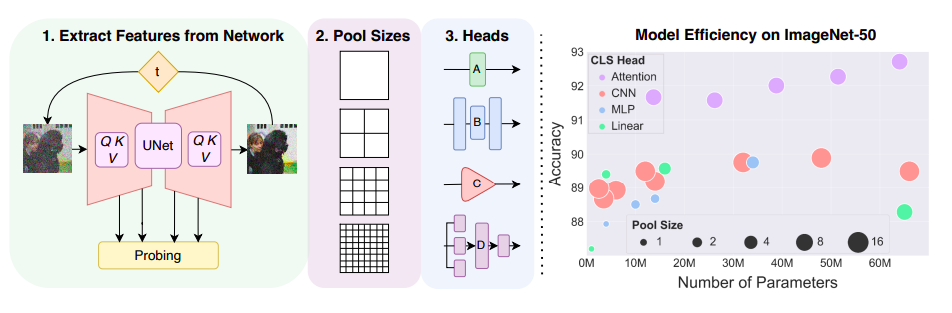
Figure 1 shows their remarkable success on these two fundamentally different challenges. Compared to BigBiGAN, their strategy for using diffusion models produces significantly superior picture creation performance and better image categorization performance. As a result, they demonstrate that diffusion models are already very close to state-of-the-art unified self-supervised representation learners in terms of optimizing for both classification and generation concurrently. The selection of features in diffusion models is one of their key difficulties. It is very difficult to choose the noise steps and feature block. They thus look into the applicability of the various aspects and compare them. These feature maps can also be rather big regarding channel depth and spatial resolution.
They also offer several classification heads to replace the linear classification layer to solve this, which can enhance classification results without sacrificing generation performance or adding more parameters. They show that diffusion models may be utilized for classification problems without changing the diffusion pre-training since they perform excellently as classifiers with adequate feature extraction. As a result, their method can be used for any pre-trained diffusion model and may, therefore, gain from upcoming enhancements to these models’ size, speed, and picture quality. The effectiveness of diffusion features for transfer learning on downstream tasks is also examined, and the features are directly contrasted with those from other approaches.
They select the fine-grained visual classification (FGVC) for downstream tasks, which appeals to the usage of unsupervised features because of the indicated lack of data for many FGVC datasets. Since a diffusion-based approach does not rely on the kinds of color invariances that other studies have shown would restrict unsupervised approaches in the FGVC transfer context, this task is particularly relevant using a diffusion-based approach. They use the well-known centered kernel alignment (CKA) to compare the features, which enables a thorough investigation of the significance of feature selection and how comparable diffusion model features are to those from ResNets and ViTs.
Their contributions, in brief, are as follows:
• With 26.21 FID (-12.37 vs. BigBiGAN) for unconditional image formation and 61.95% accuracy (+1.15% vs. BigBiGAN) for linear probing on ImageNet, they show that diffusion models may be employed as unified representation learners.
• They give analysis and distillation guidelines for getting the most usable feature representations out of the diffusion process.
• For using diffusion representations in a classification scenario, they contrast attention-based heads, CNN, and specialized MLP heads with standard linear probing.
• Using many well-known datasets, they examine the transfer learning characteristics of diffusion models with fine-grained visual categorization (FGVC) as a downstream task.
• They employ CKA to compare the numerous representations learned by diffusion models to alternative architectures and pre-training techniques, as well as to different layers and diffusion features.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 900+ AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.