Sketch-Based Image-to-Image Translation: Transforming Abstract Sketches into Photorealistic Images with GANs
Some people are skilled at sketching, while others may be talented in other tasks. When presented with a shoe image, individuals can make simple lines to represent the photo, but the quality of the sketches may vary. On the contrary, humans have an intrinsic ability to visualize a realistic image based on even an abstract drawing, a skill developed over millions of years of evolution.
With the advent of AI and generative models, generating a photorealistic image from abstract sketches falls within the broader context of image-to-image translation literature. This problem has been explored in prior works such as pix2pix, CycleGAN, MUNIT, and BicycleGAN. Some of these prior approaches, including sketch-specific variants, have claimed to tackle similar problems by generating photo edgemaps, which highlight objects’ significant contours and outlines in a sketch. These edgemaps are detailed pictures, implying that these models do not consider abstract sketches but rather focus on refined ones.
The paper presented in this article focuses on sketch-based image-to-image translation but with a crucial distinction from the cited approaches. It focuses on generating images directly from abstract human sketches rather than using photo edgemaps. According to the authors, the models trained with edgemaps produce high-quality photorealistic photos with edgemaps, but unrealistic results with amateur human sketches. This outcome is because all previous approaches assume pixel alignment during translation. As a result, the generated results accurately reflect the drawing skill (or lack thereof) of the individual, leading to subpar outcomes for non-artists.
Consequently, a non-trained artist will never achieve a satisfactory result with these models. However, the novel AI approach presented in this article seeks to democratize sketch-to-photo generation technology.
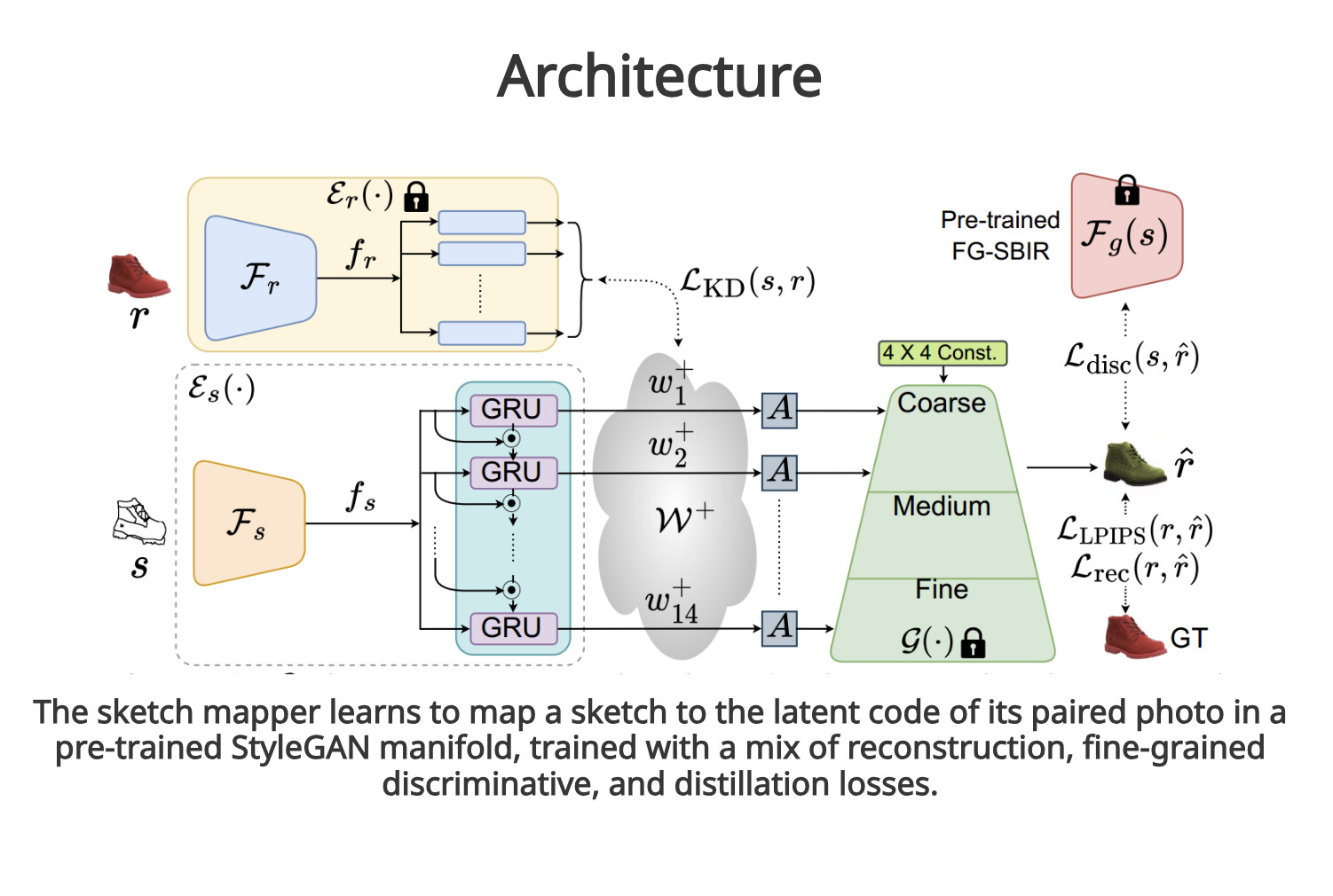
Its architecture is presented in the figure below.
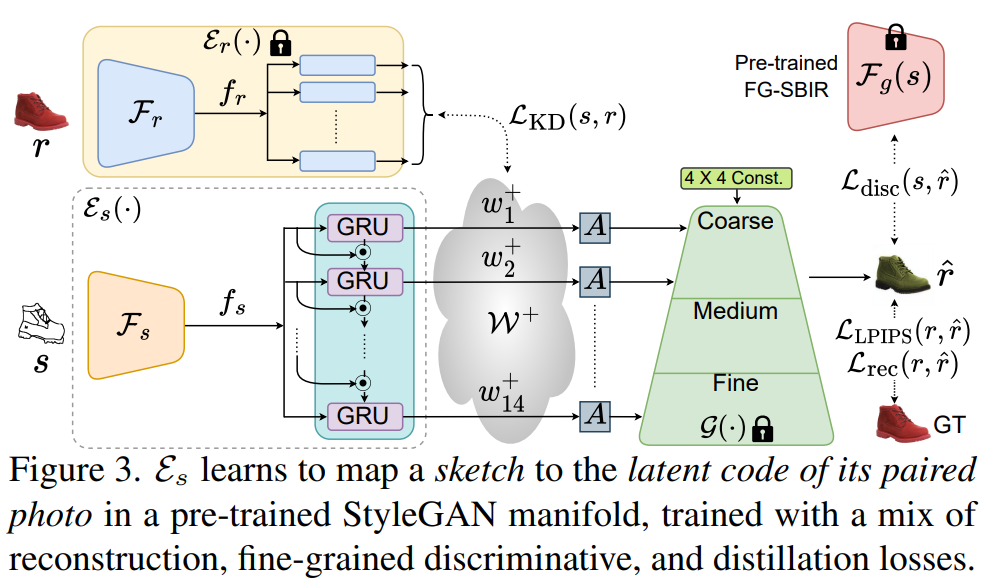
This technique enables the generation of a photorealistic image from a sketch regardless of the sketch’s quality. The authors found that the pixel-alignment artifact presented in previous approaches resulted from training the encoder-decoder architecture end-to-end. This caused the generated results to strictly follow the boundaries defined in the input sketch (edgemap), limiting the quality of the outcomes. To address this, they introduced a decoupled encoder-decoder training method. The researchers pre-trained the decoder using StyleGAN solely on photos and froze it afterward. This ensured that the generated results were of photorealistic quality, sampled from the StyleGAN manifold.
Another important aspect is the gap between abstract sketches and realistic photos. To overcome this problem, they trained an encoder to map abstract sketch representations to the latent space of StyleGAN, rather than actual photos as usual. They used ground-truth sketch-photo pairs and imposed a novel fine-grained discriminative loss between the input sketch and the generated photo, along with a conventional reconstruction loss, to ensure accurate mapping. Furthermore, they introduced a partial-aware augmentation strategy to handle the abstract nature of sketches. This involved rendering partial versions of a full sketch and appropriately allocating latent vectors based on the level of partial information.
After training their generative model, the researchers observed several interesting properties. They found that the level of abstraction in the generated photo could be controlled easily by adjusting the number of predicted latent vectors and adding Gaussian noise. The model also exhibited robustness towards noisy and partial sketches due to the partial-aware sketch augmentation strategy. Furthermore, the model showed good generalization to different abstraction levels of input sketches.
A manifold of results for the proposed approach and state-of-the-art techniques is reported below.

This was the summary of a novel AI generative image-to-image model to synthesize photorealistic images from abstract human sketches. If you are interested and want to learn more about this work, you can find further information by clicking on the links below.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Daniele Lorenzi received his M.Sc. in ICT for Internet and Multimedia Engineering in 2021 from the University of Padua, Italy. He is a Ph.D. candidate at the Institute of Information Technology (ITEC) at the Alpen-Adria-Universität (AAU) Klagenfurt. He is currently working in the Christian Doppler Laboratory ATHENA and his research interests include adaptive video streaming, immersive media, machine learning, and QoS/QoE evaluation.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.