Point-Cloud Completion with Pretrained Text-to-image Diffusion Models
Have you ever heard the term point-cloud? It is a fundamental representation of 3D data, consisting of points in a three-dimensional coordinate system that describes the geometry and spatial attributes of objects or environments. They are widely used in computer vision, virtual reality, and autonomous driving because they provide a rich and detailed representation of real-world objects.
Point clouds are acquired using depth sensors, like LiDAR scanners or depth cameras. LiDAR scanners emit laser beams and measure the time it takes for the beam to bounce back after hitting an object. Depth cameras use structured light or time-of-flight techniques to estimate the depth of each pixel in an image.
While point clouds provide valuable information about the 3D world, they often suffer from imperfections and incompleteness. Factors like occlusions, sensor limitations, and noise can result in missing or noisy data points, making it challenging to obtain a complete and accurate representation of the scene or objects being captured. This limitation hinders the effective utilization of point clouds for various applications.
To overcome these limitations and achieve a comprehensive understanding of the three-dimensional world, researchers have been exploring point cloud completion techniques.
Recent advancements in deep learning and generative models have led to significant progress in point cloud completion. By training models on large-scale datasets of complete point clouds, these approaches can learn to infer missing geometry based on contextual information and patterns observed in the training data. They have demonstrated impressive results in completing complex and detailed object shapes, even in the presence of partial or noisy input data.
However, these methods struggle to complete point clouds if they do not belong to the objects seen in the training set. Let us meet with SDS-Complete, which tackles this problem using diffusion models.
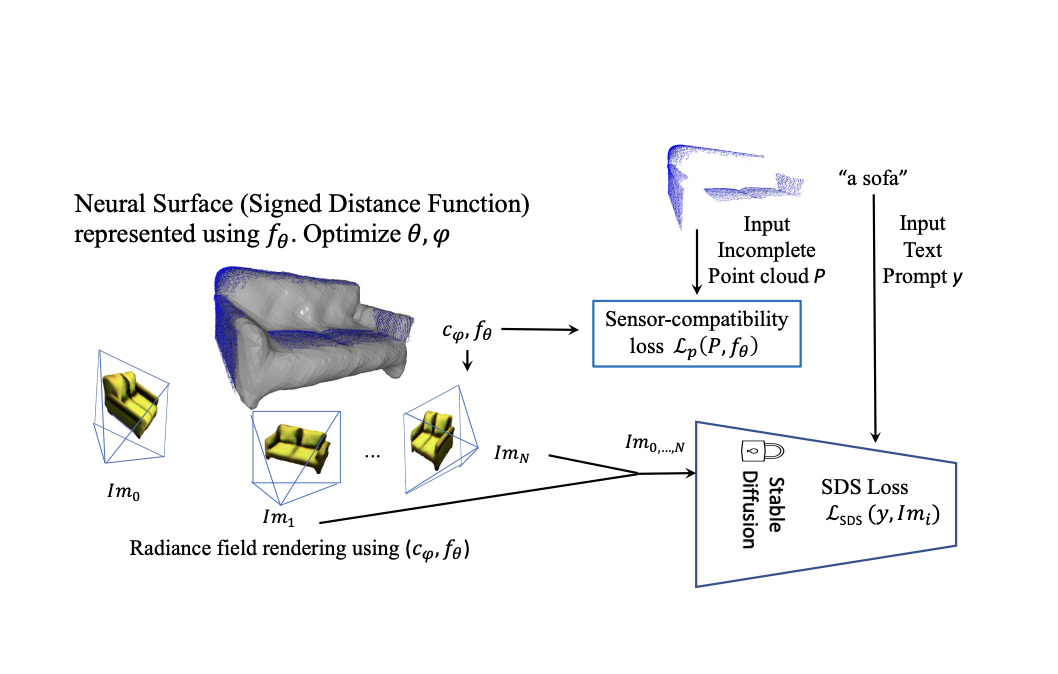
SDS-Complete leverages a pre-trained text-to-image diffusion model to guide the completion of missing parts in point clouds. Traditional approaches to point cloud completion rely heavily on large-scale datasets with a limited range of shape classes. However, real-world scenarios require the completion of diverse object classes, posing a significant challenge in developing models that can handle such variety.
The key idea behind SDS-Complete is to exploit the prior knowledge contained within pre-trained text-to-image diffusion models. These models have been trained on many diverse objects, making them a valuable resource for completing missing parts. By combining the prior information from the diffusion model with the observed partial point cloud, SDS-Complete generates accurate and realistic 3D shapes that faithfully reflect the partial observations.
To achieve this combination, SDS-Complete utilizes the SDS loss and a Signed Distance Function (SDF) surface representation. The loss ensures consistency with the input points, while the SDF representation enables preserving existing 3D content captured by different depth sensors. The method takes into account input constraints of text and point clouds, allowing for the completion of object surfaces guided by both textual information and observed data.
their Github page. One can also see more demos on their project page.
Check out the Paper and Project Page. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.